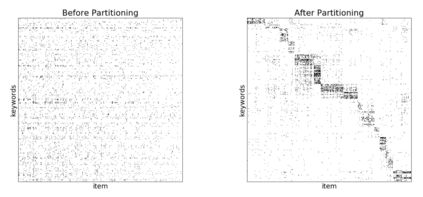
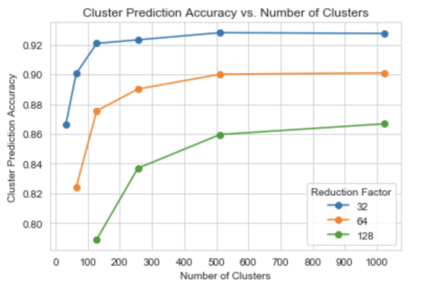
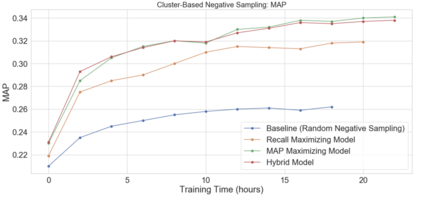
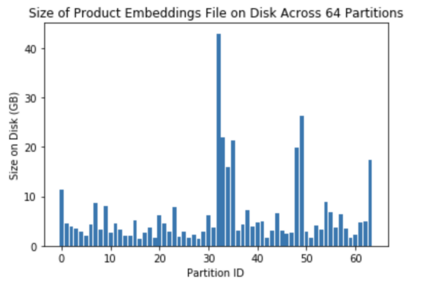
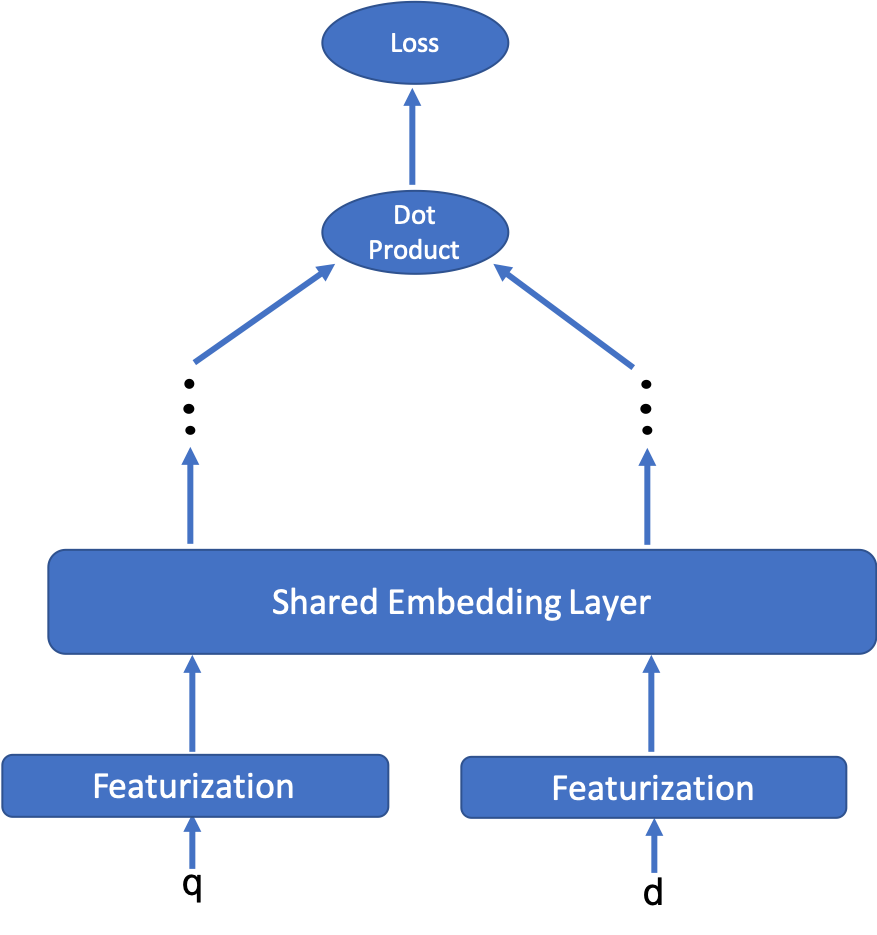
We present principled approaches to train and deploy dyadic neural embedding models at the billion scale, focusing our investigation on the application of semantic product search. When training a dyadic model, one seeks to embed two different types of entities (e.g., queries and documents or users and movies) in a common vector space such that pairs with high relevance are positioned nearby. During inference, given an embedding of one type (e.g., a query or a user), one seeks to retrieve the entities of the other type (e.g., documents or movies, respectively) that are highly relevant. In this work, we show that exploiting the natural structure of real-world datasets helps address both challenges efficiently. Specifically, we model dyadic data as a bipartite graph with edges between pairs with positive associations. We then propose to partition this network into semantically coherent clusters and thus reduce our search space by focusing on a small subset of these partitions for a given input. During training, this technique enables us to efficiently mine hard negative examples while, at inference, we can quickly find the nearest neighbors for a given embedding. We provide offline experimental results that demonstrate the efficacy of our techniques for both training and inference on a billion-scale Amazon.com product search dataset.
翻译:我们提出了在10亿规模上培训和部署dyadic神经嵌入模型的原则性方法,我们的调查重点是运用语义产品搜索。在培训dyadic模型时,我们试图将两种不同类型的实体(例如查询和文件或用户和电影)嵌入一个共同的矢量空间,使具有高度相关性的对等方处于附近位置。在推断过程中,考虑到一种类型的嵌入(例如查询或用户),我们寻求检索其他类型实体(例如文件或电影)的高度相关性。在这项工作中,我们表明利用现实世界数据集的自然结构有助于有效地应对这两项挑战。具体地说,我们将dyadic数据建为双面图,在具有积极关联的对等方之间有边缘。我们然后提议将这一网络分割成一个具有语义一致性的集群,从而缩小我们的搜索空间,方法是集中研究其中的一小部分,以获得某项投入。在培训中,这一技术使我们能够有效地挖掘负面的例子,同时推断,我们可以迅速找到近距离的亚马逊数据集的实验性结果。