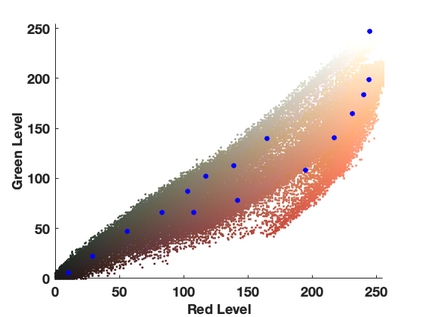
Graphics Interchange Format (GIF) is a highly portable graphics format that is ubiquitous on the Internet. Despite their small sizes, GIF images often contain undesirable visual artifacts such as flat color regions, false contours, color shift, and dotted patterns. In this paper, we propose GIF2Video, the first learning-based method for enhancing the visual quality of GIFs in the wild. We focus on the challenging task of GIF restoration by recovering information lost in the three steps of GIF creation: frame sampling, color quantization, and color dithering. We first propose a novel CNN architecture for color dequantization. It is built upon a compositional architecture for multi-step color correction, with a comprehensive loss function designed to handle large quantization errors. We then adapt the SuperSlomo network for temporal interpolation of GIF frames. We introduce two large datasets, namely GIF-Faces and GIF-Moments, for both training and evaluation. Experimental results show that our method can significantly improve the visual quality of GIFs, and outperforms direct baseline and state-of-the-art approaches.
翻译:图形互换格式( GIF) 是一种高度可移植的图形格式, 它在互联网上普遍存在。 尽管其大小小, GIF 图像往往包含一些不受欢迎的视觉文物, 如平面彩色区域、假轮廓、颜色变化和点形图案。 在本文中, 我们提议了以学习为基础的第一方法GIF2Video, 用于提高野生GIF的视觉质量。 我们集中关注GIF 恢复具有挑战性的任务, 恢复在 GIF 创建的三个步骤中丢失的信息: 框架取样、 颜色定量化和颜色抖动。 我们首先提出一个新的CNN 色彩淡化结构。 它建立在一个多步色校正的构成结构上, 其全面的损耗函数旨在处理大度错误。 然后我们调整 SuperSlomo 网络, 用于对 GIF框架进行时间互调。 我们引入了两个大型数据集, 即 GIF- Faces 和 GIF- Moments,, 用于培训和评估。 实验结果显示我们的方法可以显著地改进 GIFFFFs 的视觉质量、 外形基线和外形 。