【学界】旷视等提出GIF2Video:首个深度学习GIF质量提升方法
来源:机器之心
你还为 GIF 动图模糊不清而烦恼吗?
论文:GIF2Video: Color Dequantization and Temporal Interpolation of GIF images

论文链接:https://arxiv.org/abs/1901.02840
背景
互联网之中,GIF 可谓无处不在,通过海量用户的制作与使用而不断涌现,流转不息。GIF 的广泛传播可归因于其文件较小,上手高度便捷。
但是,由于制作过程的颜色量化非常严重,相较于原视频,GIF 经常成像较差。把一段视频制作成一张 GIF 需要 3 步:帧采样(frame sampling)、颜色量化(color quantization)以及可选用的颜色抖动(color dithering)。
帧采样会导致 jerky motion 的问题,而颜色量化和抖动则会产生平坦区域(flat color regions)、伪边界(false contours)、颜色偏移(color shift)和点状分布(dotted pattern)等问题,如图 1 所示。
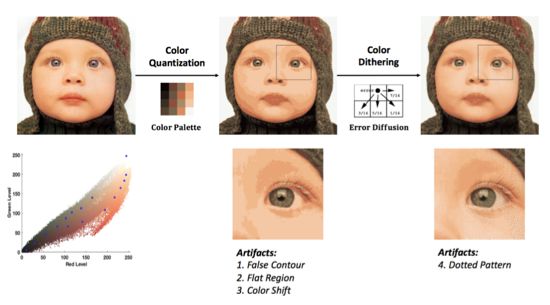
图 1:颜色量化与抖动。
设计思想
本文工作的亮点是一种新的颜色反量化(color dequantization)方法,去除由颜色量化(一种有损压缩过程)带来的成像瑕疵。GIF 的颜色量化过程远比传统的色深压缩(bit depth reduction)更为激进,每张 GIF 通常只用到 256 色(甚至更少,如 32 色)的调色板,本文的任务即是 GIF 图像进行反量化处理,其挑战性要远胜于传统的色深增强。
当然,从量化图像中复原所有原始像素近乎不可能,因此本文目标是渲染一个接近原图像的合理版本,具体做法是收集训练数据并训练一个卷积神经网络,从而把量化图像映射到原版本。
但是,训练一个良好适用于不同 GIF 图像的卷积网络相当困难。为此,本文提出 2 项全新的技术以提升反量化网络的性能:
首先,本文把反量化视为一个优化问题,并借鉴 Lucas-Kanade 迭代思想,提出一种可迭代用于颜色反量化的新型网络架构——组合性颜色反量化网络(Compositional Color Dequantization Network/CCDNet),它可以很好地消除由严重量化导致的成像瑕疵。
其次,本文在设计重建损失和生成对抗损失函数时,兼顾像素颜色和图像梯度两个维度,事实证明这比仅在颜色值上定义损失函数更有效。
GIF2Video 效果演示视频。左上为 input GIF,右上为 ground truth GIF,左下为 output GIF,右下为 ground truth GIF 和 output GIF 之差,黑色越深,表示相差越小。
GIF 制作及其瑕疵
如上所述,把视频制作成 GIF 共有 3 步: (1) 帧采样、(2) 颜色量化、(3) 颜色抖动。帧采样可以显著减少 GIF 文件大小,但也降低了视频内容的时序分辨率;颜色量化与抖动的详细过程与细节及其成像瑕疵请参见原论文,本节不再赘述。
方法
本文方法将 GIF 动图(由一序列 GIF 帧组成)转化为视频,质量比原始 GIF 高出一大截,它主要分为两步:颜色反量化和插帧(frame interpolation)。
颜色反量化方面,本文提出一个由 Lucas-Kanade 迭代算法启发的全新的组合性卷积神经网络。并且,用于训练网络的重建损失函数和生成对抗损失函数都是在像素颜色和图像梯度两个空间内计算并结合的。
执行颜色反量化之后,本文使用一个改进的视频插帧算法以增加输出视频的时序分辨率。
颜色反量化
令 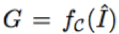
因此,颜色反量化的目标是在给定 G 的情况下恢复原始图像,即。但是量化函数 f_C 是一个多对一的映射,所以颜色的反量化是一个不适定(ill-posed)问题。
本文提出的方法将量化函数 f_C 本身嵌入到组合性网络中,从而为反量化函数的学习和推理提供了有价值的信息和指引。
组合性架构
已量化 GIF 图像 G 和调色板 C 既定之后,本文寻找接近于 ground truth 图像 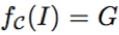
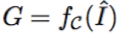
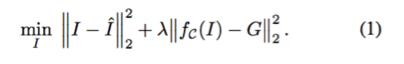
但是,由于量化函数 f_C 的导数几乎处处为 0,第二个损失项 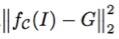
为此,本文借鉴 Lucas-Kanade 算法迭代地优化第二个损失项。每次迭代都要计算对复原图像的更新以进一步最小化损失:
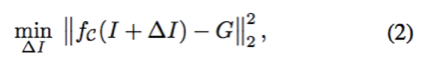
对 f_C 采用一阶泰勒展开,方程(2)可近似为:
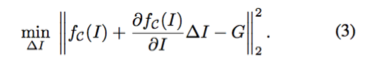
这是一个关于 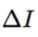
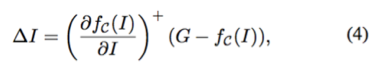
方程(4)表示在一阶泰勒展开近似下,最佳更新
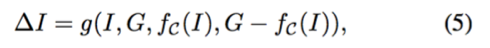
其中 g 表示需要学习的深度卷积网络。遵循 Lucas-Kanade 算法的迭代思路,本文交替计算更新方向和更新反量化图像:
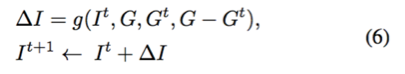
其中 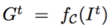
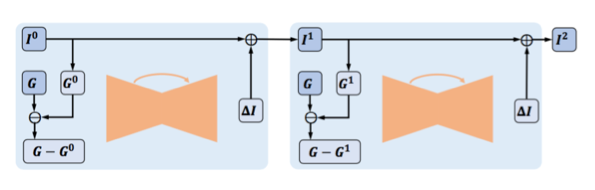
图 2: CCDNet 架构。
当前图像估计 I^t 既定的情况下,本文首先使用输入 GIF 图像 G 的同一调色板计算 I^t 的颜色量化图像 G_t。接着 U-Net 模块把 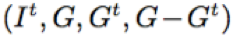
颜色反量化损失
令 G_i 表示 CCDNet 的输入 GIF 图像,I_i 表示相应的输出。本文提出使用方程(7)中的损失函数以测量 I_i 和 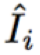

为使图像估计更为清晰,本文使用 L_1 范数计算重建损失函数 
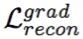
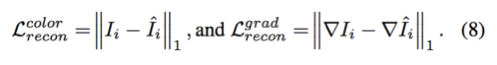
本文还使用条件生成式对抗网络(Conditional GAN)优化 CCDNet,促使网络输出的分布尽可能逼近真实图像的分布。这里的对抗性损失函数在颜色值和梯度值上同时定义,实验表明考虑梯度值的损失确实非常重要:
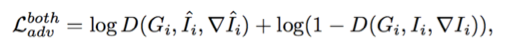
时序插值
SuperSlomo 是新近提出的一种神经网络,专为变长式多帧插值(variable-length multi-frame interpolation)而设计。本文使用 SuperSlomo 反转帧采样的过程,提升 GIF 的时序分辨率。
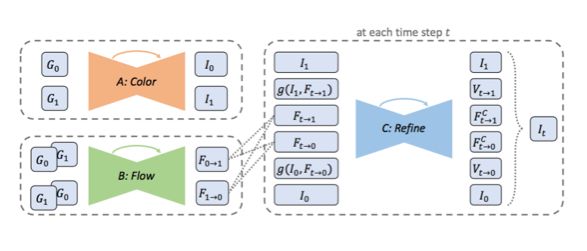
图 4:GIF2Video pipeline。
图 4 描绘了整个 GIF2Video 流程图,这一算法有 3 个组件:
网络 A 执行颜色反量化,输出对 ground truth 图像的估计 I_0 和 I_1;
网络 B 估计两个输入帧之间的双向光流图
和
;
网络 C 接收网络 A 和 B 的输出,并计算插值帧 I_t。
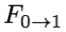
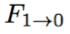
本文使用 CCDNet 作为网络 A,网络 B 和 C 则是 SuperSlomo 的两个 U-Net 模块。网络 B 直接使用 GIF 图像来估计双向光流,而不是使用网络 A 的输出,这使得网络 A 和 B 可并行运行。实验表明这一并行模型与串行模型性能相似。
数据集
本文的另一个贡献是针对这一任务采集了两个大型数据集:GIF-Faces 和 GIF-Moments。两个数据集都包含大量 GIF 动图及其相应的高质量视频。顾名思义,GIF-Faces 以人脸为主,GIF-Moments 则更通用和多元,基于互联网用户制作的真实 GIF 而打造。

图 5:GIF-Faces(上行)和 GIF-Moments(下行)数据集的样帧。
图 5 给出了两个数据集的一些样帧(无抖动)。上行的图像来自数据集 GIF-Faces,包含了人脸和部分上半身,背景场景多样;下行的图像来自数据集 GIF-Moments,内容更加多元,场景范围涵盖体育、电影、动画等。
实验
本文实验使用峰值信噪比(PSNR)和结构相似性指数(SSIM)作为评价指标。PSNR 基于估计图像与原始图像之间的均方根误差(RMSE)定义。SSIM 也被经常用于评价图像质量。
本文首先计算每一帧的 PSNR 和 SSIM,然后在每一视频内取均值,最后再在测试集的所有视频取均值。下面是一些实验结果的图示:
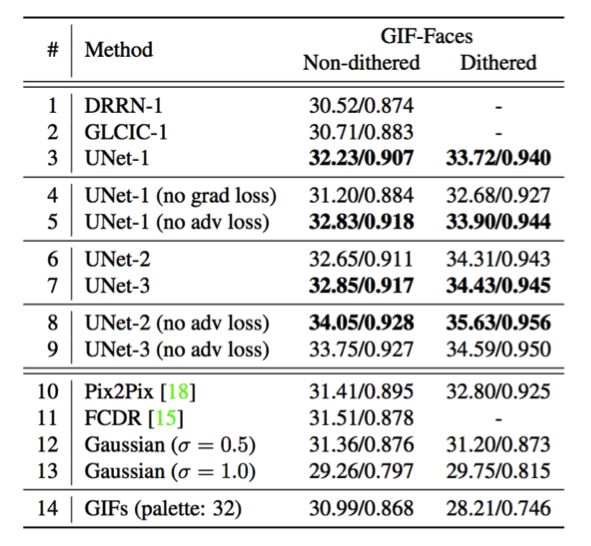
表 1:数据集 GIF-Faces 上的 GIF 颜色反量化的结果对比。
由表 1 可知,第 1-9 行是 CCDNet 不同设置下的结果;第 10-13 行是若干个现有方法的结果。性能通过 PSNR 和 SSIM 进行衡量(越高越好)。
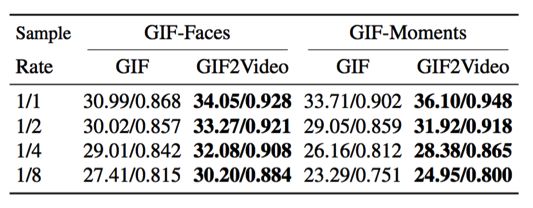
表 2:GIF 帧时序插值的结果。
由表 2 可知,随着时序下采样因子从 1 增至 8,已制作 GIF 的成像质量迅速下降。在 GIF-Faces 数据集上,GIF2Video 可提升复原视频的 PSNR 高达 3 dB。这等价于颜色值减少 30% 的均方根误差。
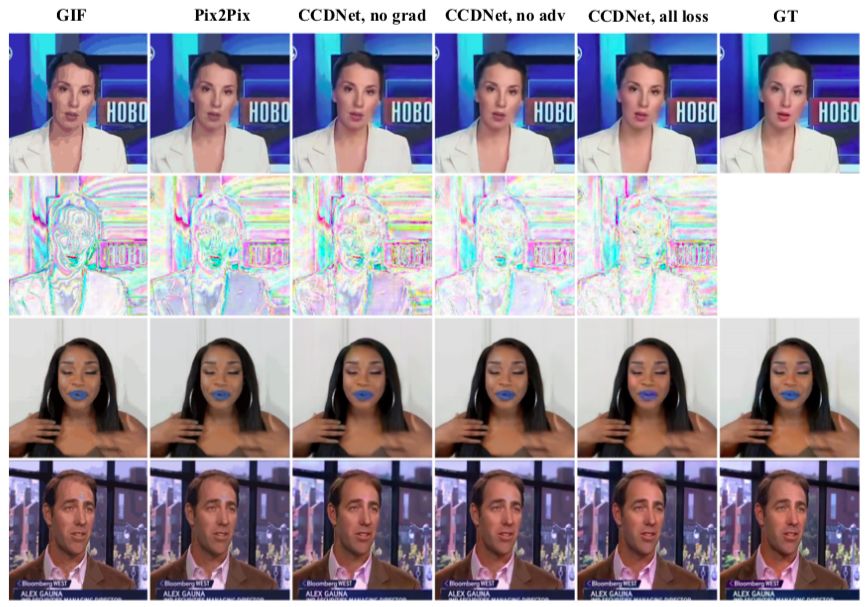
图 8: 数据集 GIF-Faces 中 GIF 颜色反量化的定性结果。
训练 Pix2Pix 和 CCDNet 而不借助于图像的基于梯度的损失是无法很好地消除量化瑕疵的,比如平坦区域和伪边界。借助对抗性损失训练 CCDNet 可带来更加逼真、颜色更加丰富的图像(见图 8 皮肤和嘴唇的颜色)。在数字设备上观看效果更佳。
结论
本文提出了 GIF2Video,首个基于深度学习提升自然场景下 GIF 成像质量的方法,其主要任务有两个:颜色反量化和帧插值。针对第一个任务,本文给出一个组合性网络架构 CCDNet,并通过综合损失函数训练它,颜色反量化被嵌入于 CCDNet 以指导网络学习和推理。对于第二个任务,本文采用 SuperSlomo 进行变长多帧插值以提升输入 GIF 的时序分辨率。
实验结果表明 GIF2Video 可以通过显著减少量化瑕疵而大幅提升输入 GIF 的成像质量。本文希望该方法可以激发更多灵感,发觉更多方法优化从 GIF 重建视频的任务,比如把图像序列看作一个 3D volume 或者应用循环神经网络提升帧内一致性。

参考文献
[1] Graphicsinterchangeformat,version89a.https://www.w3.org/Graphics/GIF/spec- gif89a.txt.
[10] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Gen- erative adversarial nets. In Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, editors, NIPS. 2014.
[18] P.Isola,J.-Y.Zhu,T.Zhou,andA.A.Efros.Image-to-image translation with conditional adversarial networks. In Proc. CVPR, 2017.
[19] H. Jiang, D. Sun, V. Jampani, M.-H. Yang, E. Learned- Miller, and J. Kautz. Super slomo: High quality estimation of multiple intermediate frames for video interpolation. 2018.
[27] B.LucasandT.Kanade.Aniterativeimageregistrationtech- nique with an application to stereo vision. In Proceedings of Imaging Understanding Workshop, 1981.
[39] C. Wang, H. Huang, X. Han, and J. Wang. Video inpaint- ing by jointly learning temporal structure and spatial details. arXiv preprint arXiv:1806.08482, 2018.
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得


