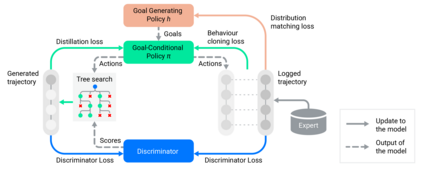
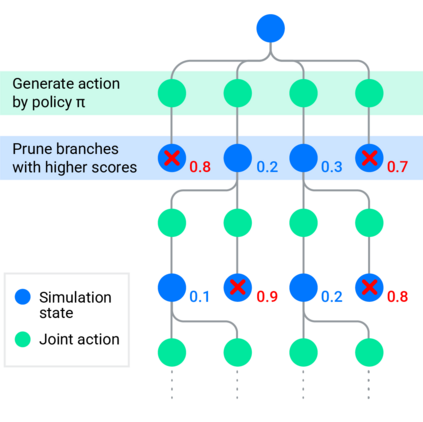
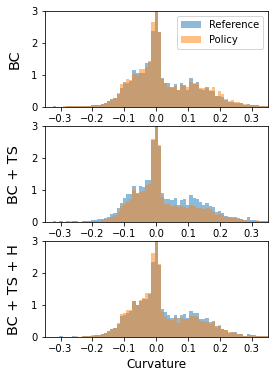
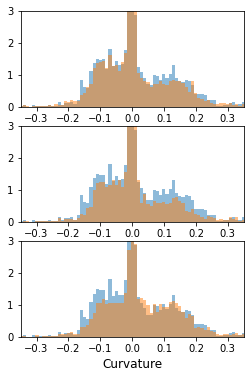
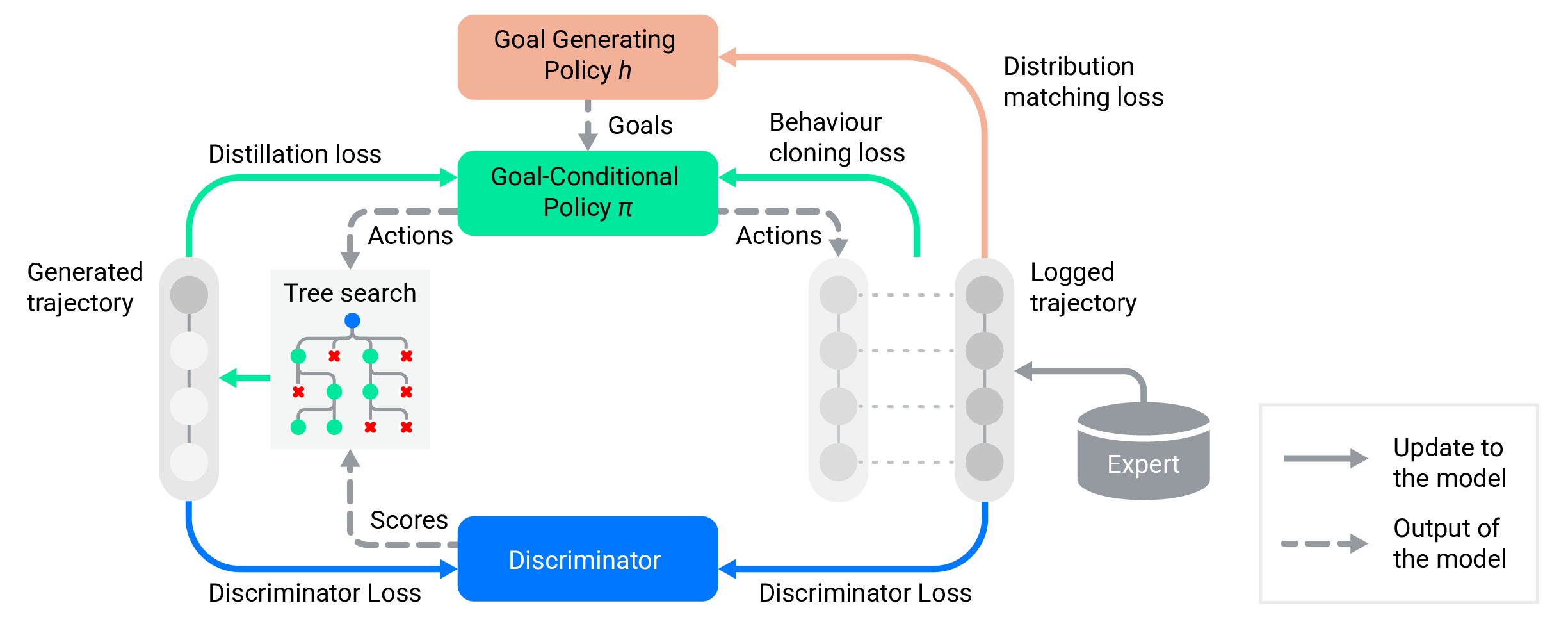
Simulation is a crucial tool for accelerating the development of autonomous vehicles. Making simulation realistic requires models of the human road users who interact with such cars. Such models can be obtained by applying learning from demonstration (LfD) to trajectories observed by cars already on the road. However, existing LfD methods are typically insufficient, yielding policies that frequently collide or drive off the road. To address this problem, we propose Symphony, which greatly improves realism by combining conventional policies with a parallel beam search. The beam search refines these policies on the fly by pruning branches that are unfavourably evaluated by a discriminator. However, it can also harm diversity, i.e., how well the agents cover the entire distribution of realistic behaviour, as pruning can encourage mode collapse. Symphony addresses this issue with a hierarchical approach, factoring agent behaviour into goal generation and goal conditioning. The use of such goals ensures that agent diversity neither disappears during adversarial training nor is pruned away by the beam search. Experiments on both proprietary and open Waymo datasets confirm that Symphony agents learn more realistic and diverse behaviour than several baselines.
翻译:模拟现实化需要与这些汽车互动的人类道路使用者的模型。这些模型可以通过将示范(LfD)学习到已经在路上的汽车所观察到的轨迹来获得。然而,现有的LfD方法通常不够充分,产生经常碰撞或驱离道路的政策。为了解决这一问题,我们提议交响乐,通过将常规政策与平行的波束搜索结合起来,大大改善现实主义。光束搜索通过对准的分支进行剪切除来完善这些政策。然而,这种模型也可能损害多样性,例如,从演示(LfD)到从演示(LfD)到在路上已经观察到的汽车所观察到的轨迹。但是,现有的LfD方法通常不够充分,产生经常碰撞或驱离道路的政策。为了解决这一问题,我们建议交响,通过将常规政策与平行的波束搜索结合起来,大大改善现实主义。使用这种目标可以确保代理人的多样性不会在对抗性训练期间消失,也不会被光线搜索所割去。但是,对专利和开路数据设置的实验也可以损害多样性,即代理人覆盖整个现实行为分布比多种基线和不同的行为更现实。