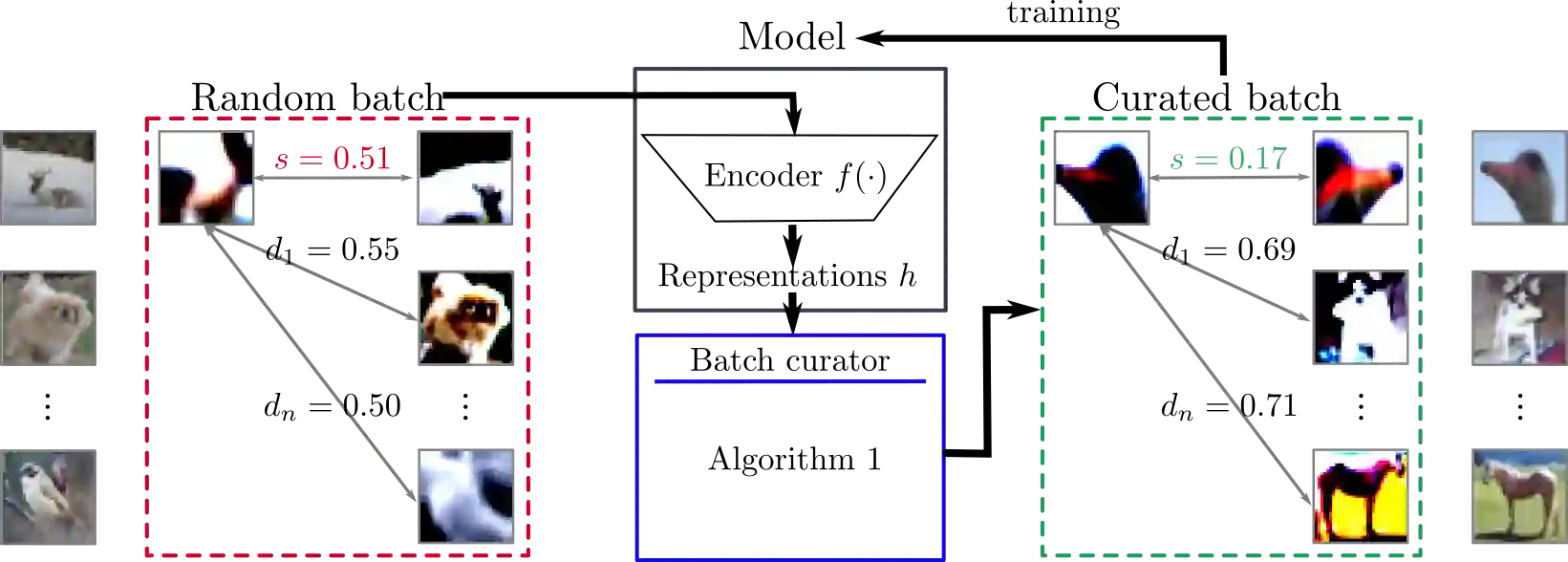
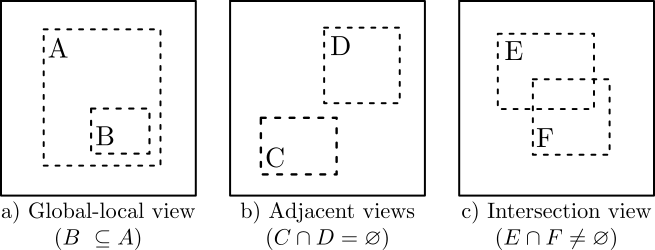
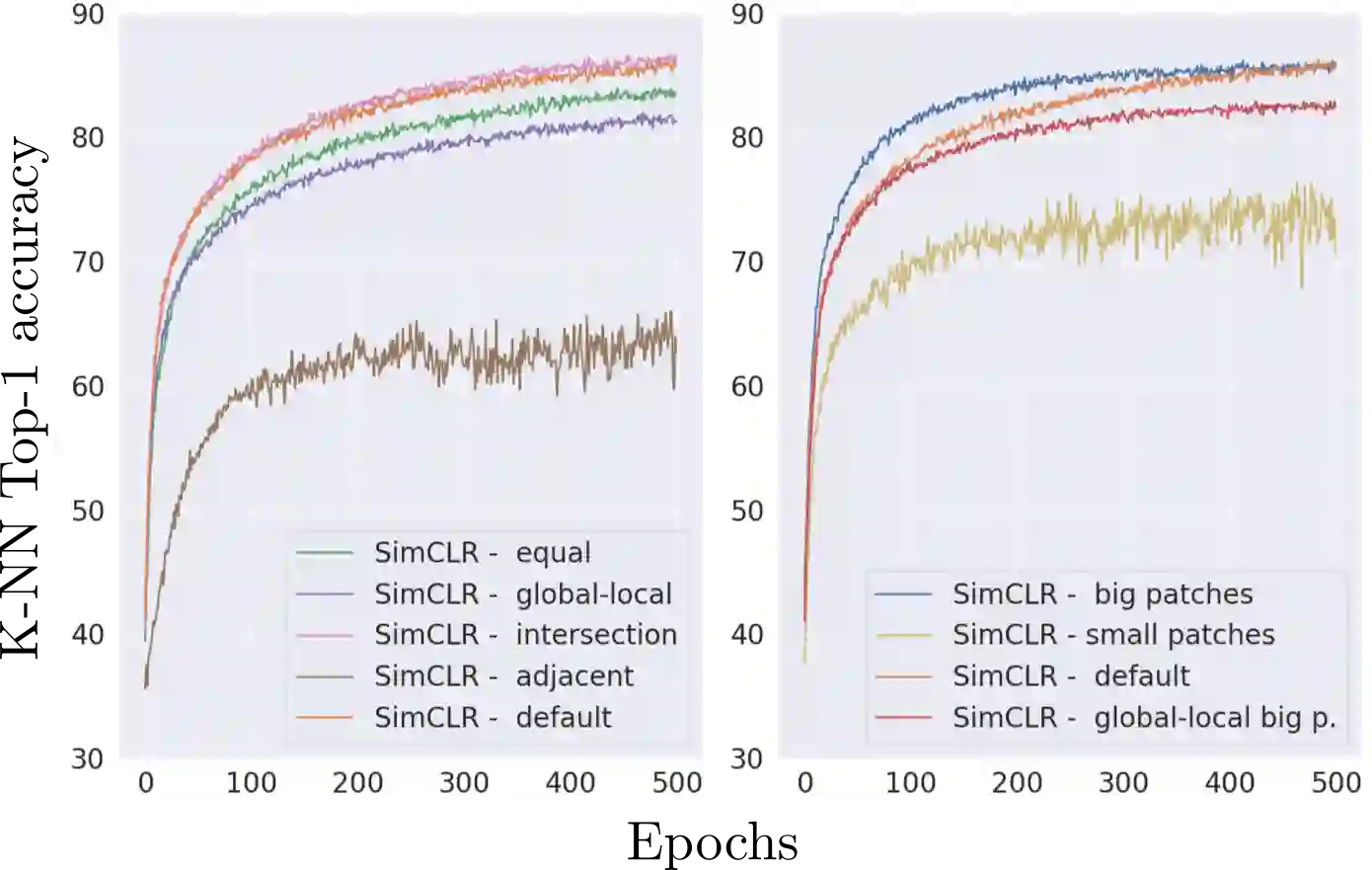
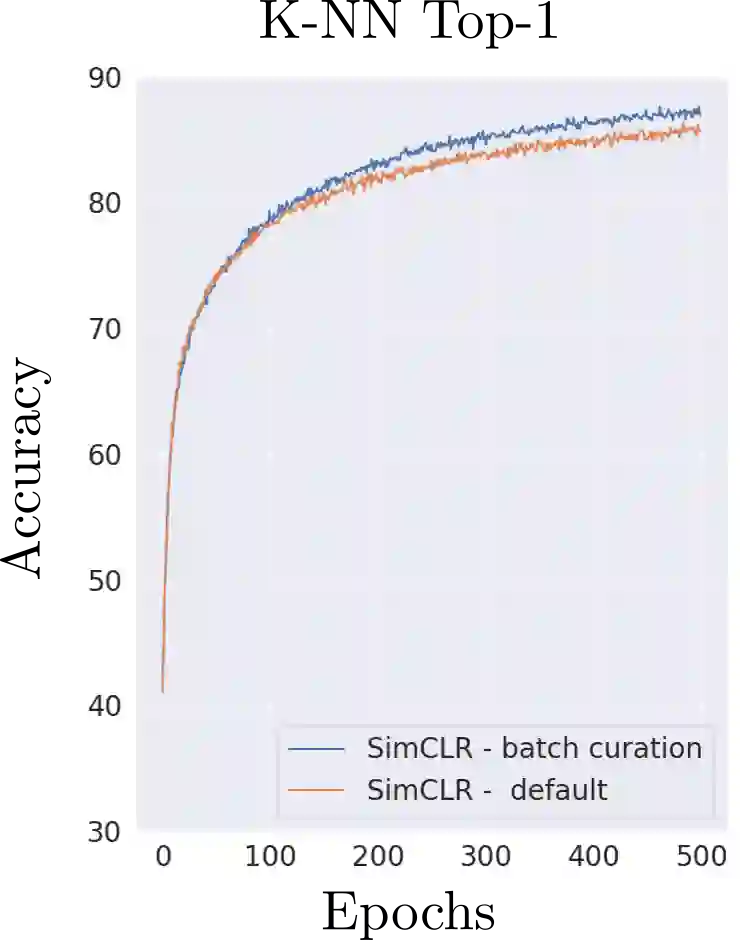
The state-of-the-art unsupervised contrastive visual representation learning methods that have emerged recently (SimCLR, MoCo, SwAV) all make use of data augmentations in order to construct a pretext task of instant discrimination consisting of similar and dissimilar pairs of images. Similar pairs are constructed by randomly extracting patches from the same image and applying several other transformations such as color jittering or blurring, while transformed patches from different image instances in a given batch are regarded as dissimilar pairs. We argue that this approach can result similar pairs that are \textit{semantically} dissimilar. In this work, we address this problem by introducing a \textit{batch curation} scheme that selects batches during the training process that are more inline with the underlying contrastive objective. We provide insights into what constitutes beneficial similar and dissimilar pairs as well as validate \textit{batch curation} on CIFAR10 by integrating it in the SimCLR model.
翻译:最近出现的最先进的、不受监督的对比性视觉显示学习方法(SimCLR、MoCo、SwaV)都利用数据扩增方法来构建由相似和不同图像组成的即时歧视的借口任务。 相似的对配是随机从同一张图像中提取补丁,并应用诸如颜色抖动或模糊等若干其他变体来构建的。 而从某批不同图像中转换成的补丁被视为不同配方。 我们争辩说,这一方法可以产生相似的对, 它们是不同的。 在这项工作中, 我们通过引入一个“ textit{batch curation} ” 计划来解决这个问题, 在培训过程中选择更符合基本对比目标的批次组。 我们通过将其纳入SIMCLR模型, 来提供对类似和不同配对的有益之处的洞察力, 以及对CIFAR10 的校准 textit{batch curation。