解读自监督学习(Self-Supervised Learning)几篇相关paper
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:bingo
https://zhuanlan.zhihu.com/p/96748604
本文已由原作者授权,不得擅自二次转载
Supervised deep learning由于需要大量标注信息,同时之前大量的研究已经解决了许多问题。所以近期大家的研究关注点逐渐转向了Unsupervised learning,许多顶会包括ICML, NeurIPS, CVPR, ICCV相继出现一些不错的paper和研究工作。
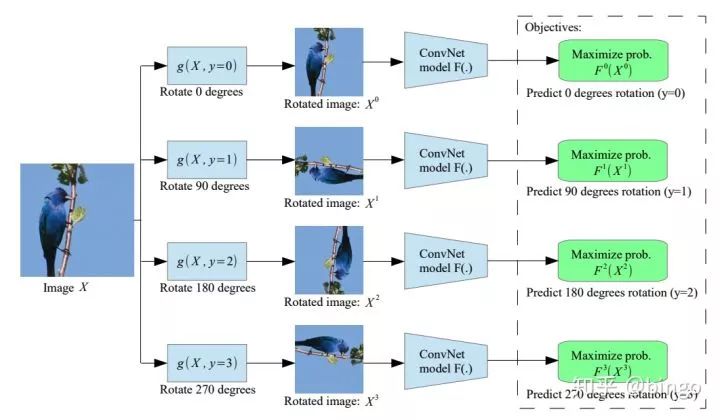
这里主要关注Unsupervised learning一类特定的方法:Self-supervised learning(自监督学习)。自监督学习的思想非常简单,就是输入的是一堆无监督的数据,但是通过数据本身的结构或者特性,人为构造标签(pretext)出来。有了标签之后,就可以类似监督学习一样进行训练。比较知名的工作有两个,一个是:Unsupervised Visual Representation Learning by Context Prediction (ICCV15),如图一,人为构造图片Patch相对位置预测任务,这篇论文可以看作是self-supervised这一系列方法的最早期paper之一;另一个是:Unsupervised Representation Learning by Predicting Image Rotations (ICLR18),如图二,人为构造图片旋转角度预测任务,这篇论文因为想法极其简单在投稿到ICLR之后受到了极大关注,最终因为实验结果非常全面有效最终被录用。

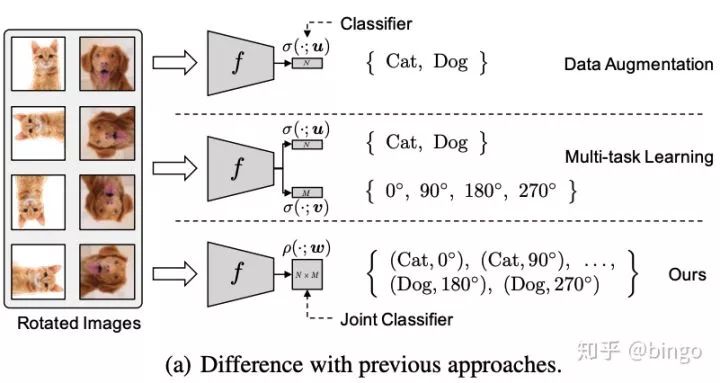
这里重点介绍最近的几篇self-supervised learning相关的paper。第一篇是RETHINKING DATA AUGMENTATION: SELF-SUPERVISION AND SELF-DISTILLATION。这篇论文的思想非常直观,如图三。首先,Data Augmentation相关的方法会对通过对原始图片进行一些变换(颜色、旋转、裁切等)来扩充原始训练集合,提高模型泛化能力;Multi-task learning将正常分类任务和self-supervised learning的任务(比如旋转预测)放到一起进行学习。作者指出通过data augmentation或者multi-task learning等方法的学习强制特征具有一定的不变性,会使得学习更加困难,有可能带来性能降低。因此,作者提出将分类任务的类别和self-supervised learning的类别组合成更多类别(例如 (Cat, 0),(Cat,90)等),用一个损失函数进行学习。
比较有意思的一点是,作者通过简单变换证明:如果 


在实际物体分类过程中,可以将不同旋转角度的分类结果进行加和,即: p(Cat) = p(Cat,0)+p(Cat,90) +p(Cat,180)+p(Cat,270),但是这样测试时间会变成原来的4倍。所以,作者提出了第二个模块,self-distillation(自蒸馏),distillation思想最早是hinton在nips14年提出来的。如下图,self-distillation思路是在学习的过程中限制不同旋转角度的平均特征表示和原始图片的特征表示尽可能接近,这里使用KL散度作为相似性度量。

最终,整个方法的优化目标如下:

第一项和第二项分别对应图(a)和图(b),第三项是正常的分类交叉熵损失,作为一个辅助loss。
之前的研究思路主要是设计各种各样的pretext任务,比如patch相对位置预测、旋转预测、灰度图片上色、视频帧排序等等。CVPR19和ICCV19上,Google Brain的几个研究员发表了两篇论文,从另外的视角分析和研究self-supervised learning问题。两篇paper名字分别是:Revisiting Self-Supervised Visual Representation Learning (CVPR19)和S^4L: Self-Supervised Semi-Supervised Learning (ICCV19) 。
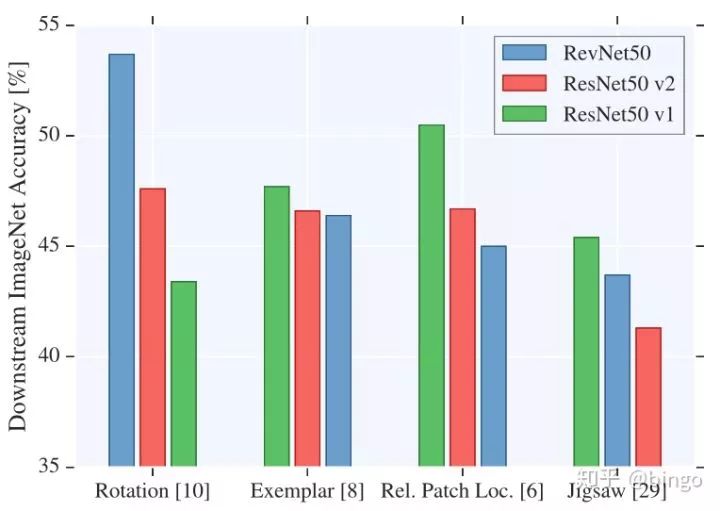
Revisiting这篇paper研究了多种网络结构以及多种self-supervised的任务的组合,得到了一些启发性的经验结论:
与supervised learning不同的是,self-supervised learning在不同task上的结果依赖于网络结构的选择,比如对于rotation预测,RevNet50性能最好,但是对于Patch预测,ResNet50v1性能最好。
以前的self-supervised方法通常表明,alexnet的最后几层特征性能会下降。但是这篇paper结论是对于skip-connection(resnet)结构的网络,高层的特征性能并不会下降。
增加filter数目和特征大小,对于性能提升帮助很大。
衡量无监督性能最后训练的线性分类器非常依赖学习率的调整策略。
S^4L这一篇paper,非常像上面图(a)中multitask learning的策略,即有标签数据上面加一个正常的分类损失,无标签数据上加一个self-supervised的损失,具体公式如下:

作者提出了两个算法,一个是 S^4L-Rotation,即无监督损失是旋转预测任务;另一个是S^4L-Exemplar,即无监督损失是基于图像变换(裁切、镜像、颜色变换等)的triplet损失。
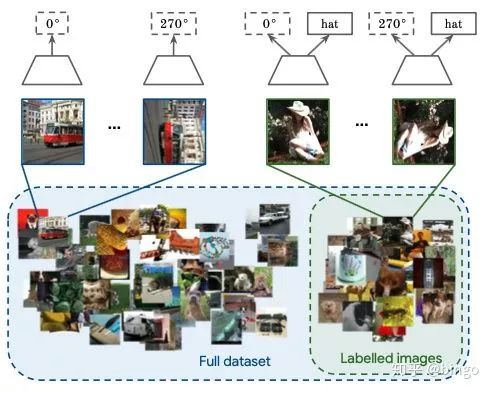
所有的实验在10%或者1%标签的Imagenet上进行,同时作者自己从训练集划分出一小部分作为验证集进行参数调节。实验过程中,作者观察到weight decay的调节和学习率策略对最终性能有很重要的影响。
比较有意思的是,Revisiting和S^4L的作者是同一拨人,只是作者顺序不同,并且所有作者都是equal contribution。
重磅!CVer-学术微信交流群已成立
扫码添加CVer助手,可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!




