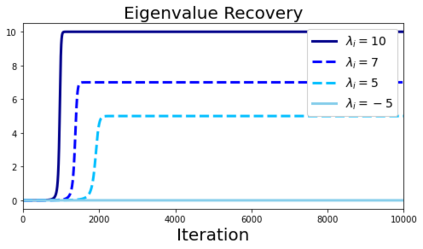
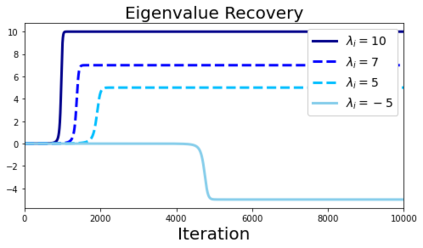
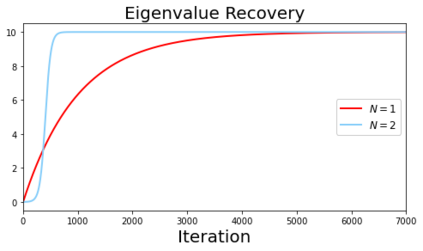
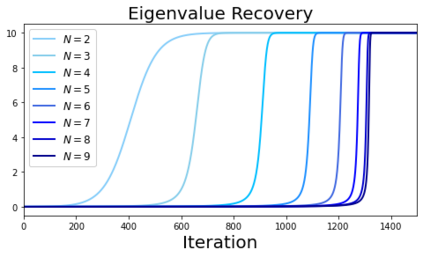
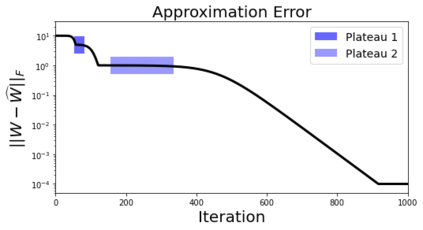
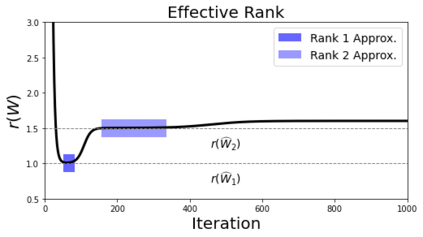
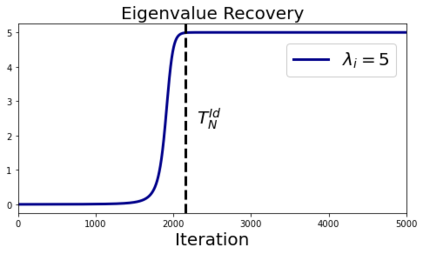
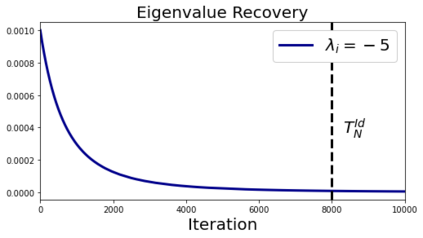
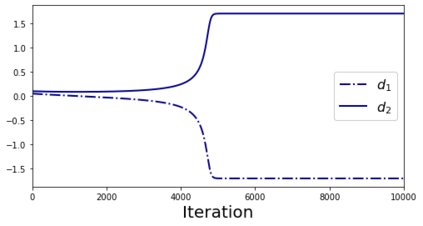
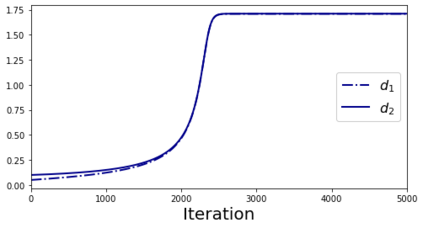
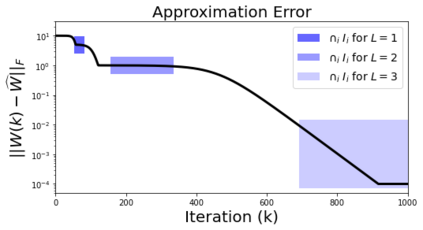
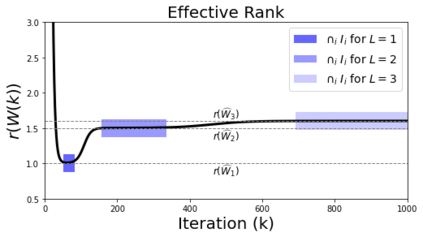
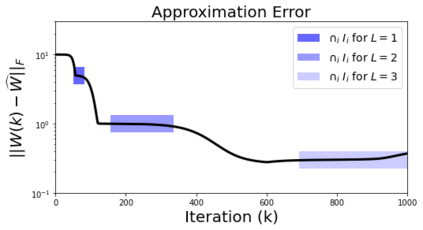
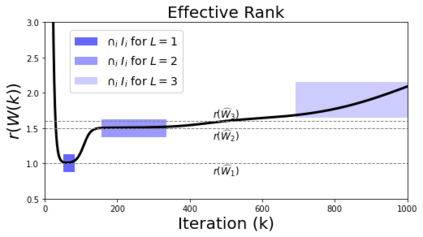
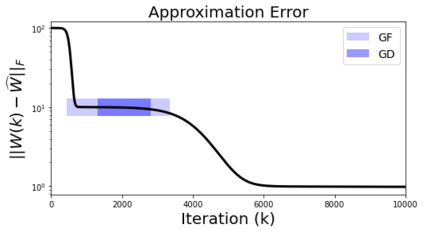
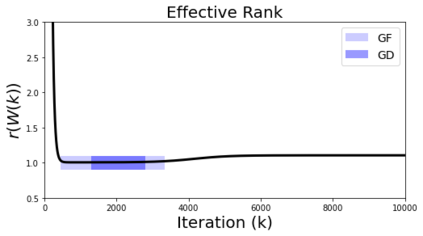
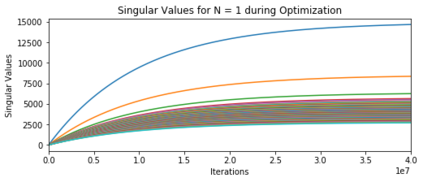
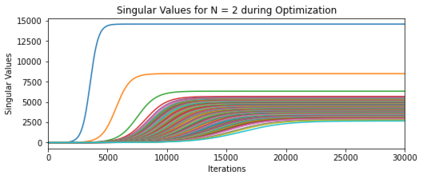
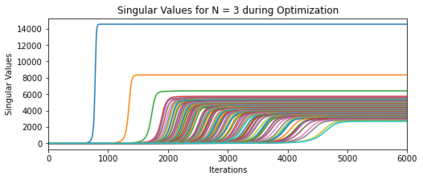
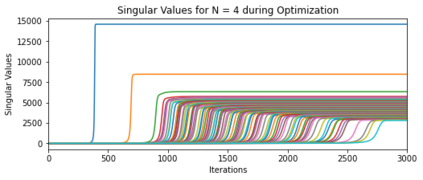
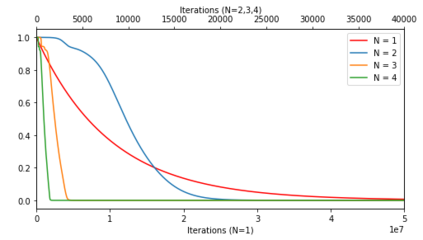
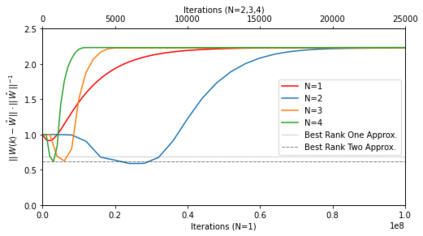
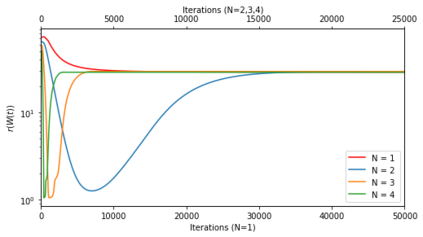
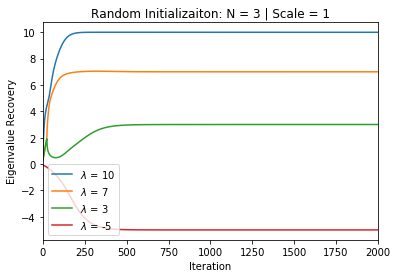
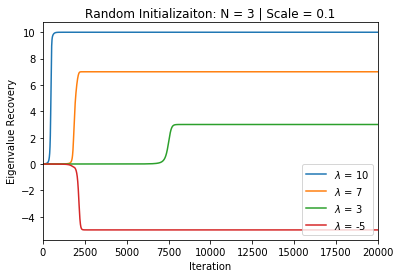
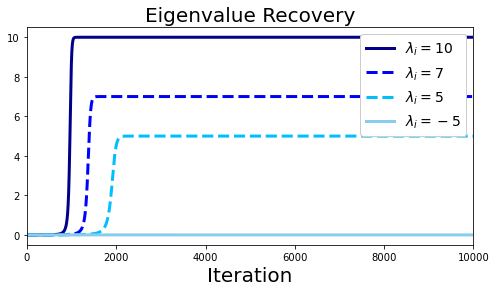
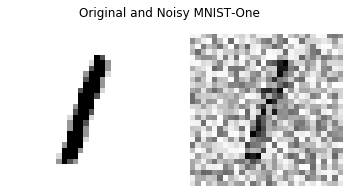In many deep learning scenarios more network parameters than training examples are used. In such situations often several networks can be found that exactly interpolate the data. This means that the used learning algorithm induces an implicit bias on the chosen network. This paper aims at shedding some light on the nature of such implicit bias in a certain simpified setting of linear networks, i.e., deep matrix factorizations. We provide a rigorous analysis of the dynamics of vanilla gradient descent. We characterize the dynamical behaviour of ground-truth eigenvectors and convergence of the corresponding eigenvalues to the true ones. As a consequence, for exactly characterized time intervals, the effective rank of gradient descent iterates is provably close to the effective rank of a low-rank projection of the ground-truth matrix, such that early stopping of gradient descent produces regularized solutions that may be used for denoising, for instance. In particular, apart from few initial steps of the iterations, the effective rank of our matrix is monotonically increasing, suggesting that "matrix factorization implicitly enforces gradient descent to take a route in which the effective rank is monotone". Since empirical observations in more general scenarios such as matrix sensing show a similar phenomenon, we believe that our theoretical results help understanding the still mysterious "implicit bias" of gradient descent in deep learning.
翻译:在许多深层次的学习假设中,网络参数比培训实例要多一些。在这种情况下,往往可以发现一些网络,完全可以推断数据。这意味着,使用过的学习算法在选定的网络中产生隐含的偏差。本文的目的是在某种简化的线性网络设置中,即深层矩阵因子化,说明这种隐含的偏差的性质。我们严格分析香草梯度梯度下降的动态。我们描述的是地面真象的动态行为和相应的叶素值与真实值的趋同。因此,对于确切的定时间隔而言,所选的梯度梯度偏移值的有效等级接近于低水平的地面光线性矩阵预测的有效等级。这样,早期停止梯度下降会产生常规化的解决方案,可用于分解,例如。特别是,除了最初的迭变步骤之外,我们矩阵的有效等级是单质的,表明“矩阵隐含地梯度的梯度下降,以采取精确的阶梯度的阶梯度观察方法,我们仍认为,在一种相似的阶梯度矩阵中,我们一般的测测测测得的是,这种测得的底的梯性模型结果。