样本贡献不均:Focal Loss和 Gradient Harmonizing Mechanism
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
本文主要介绍两个在目标检测中解决正负样本不平衡问题的方法,分别是发表在ICCV 2017上的Focal Loss for Dense Object Detection和AAAI 2019上的Gradient Harmonized Single-stage Detector。这两种方法都是通过调整每个样本的loss来解决不平衡问题。
作者 | BeyondTheData
来源 | https://zhuanlan.zhihu.com/p/55036597
已获作者授权,请勿二次转载

论文地址:http://openaccess.thecvf.com/content_ICCV_2017/papers/Lin_Focal_Loss_for_ICCV_2017_paper.pdf

论文地址:https://arxiv.org/pdf/1811.05181.pdf
这两种方法都是针对目标检测任务提出的,首先简要的介绍下背景。目标检测目前有两种主流方法,分别是two-stage和one-stage。two-stage的方法将目标检测分为两步,首先生成候选集合,该候选集合过滤了绝大多数的负样本,然后用一个分类器进行分类。代表性的工作有R-CNN,Fast R-CNN, Faster R-CNN和Mask R-CNN等等。one-stage的方法直接生成大量的图像区域然后直接进行分类,代表性的工作有OverFeat,SSD和YOLO。two-stage有最好的目标检测结果,但是one-stage速度更快。这两类方法都有类别不平衡的问题,two-stage通过Selective Search,EdgeBoxes,DeepMask和RPN等手段来解决类别不平衡,通常候选区域的个数为1-2k,在分类中可以固定foreground和background的比例或者用online hard example mining来维持样本的均衡。one-stage的方法会有100k个不同尺寸的location,在训练过程中容易被区分的background占了大多数,虽然可以用一些相似的启发式采样方法,但是这会早成训练的低效。为此,第一篇文章提出Focal loss,并且将其应用在one-stage的方法中,通过loss function来解决极端的类别不平衡问题(1:1000)。
Focal loss
首先回顾交叉熵损失函数。对二分类问题,交叉熵损失函数如下
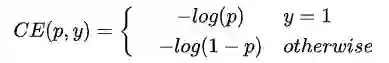
其中 

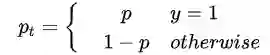
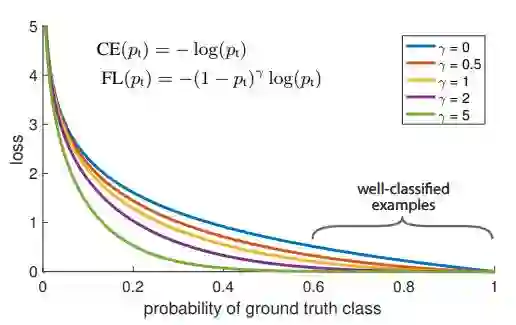
这样交叉熵可以写为 

为了解决类别不平衡,一种方法是引入一个权重因子 













作者在文中还提到了模型初始化。对于二分类,一般的模型初始化会使得正负样本的概率相等。由于类别不平衡,负样本的loss会占总体loss的很大比例。作者提出在训练初始阶段对正样本的概率估计“prior”的概念,用 


Gradient Harmonizing Mechanism(GHM)
Focal Loss虽然有很好的效果,但是loss中的两个超参需要精细的调整,除此之外,它也是一个不会随着数据分布变化的静态loss。在第二篇文章中,作者指出类别不平衡可以总结为“imbalance in difficulty”而“imbalance in difficulty”就是gradient norm分布的不平衡。如果一个正样本被分类正确,那么模型从该样本的梯度中受益很小,而一个误分类的样本对模型的影响很大。整体来看,数据巨大的负样本时容易被分类的,hard example通常是正样本。无论是hard/easy还是positive/negtive 不平衡,都可以用gradient norm来表示。如下图

左边是一个收敛模型的gradient norm的分布,中间是通过Focal Loss和GHM之后的梯度修正,右边是不同的gradient norm的梯度贡献。可以看出easy样本的梯度贡献会淹没hard样本。除此之外,作者还发现有非常大的gradient norm(very hard example)的占比比中间的样本要打,作者认为这些是outlier。通过对gradient norm的分析,作者提出Gradient Harmonizing Mechanism来对loss函数进行修正。作者提出针对分类loss的GHM-C和针对box regression的GHM-R,这两个loss均和训练中的梯度密度有关,而梯度密度是不断变化的,所以这两种loss是动态loss,这里我们只关注GHM-C。
作者用 

其中 


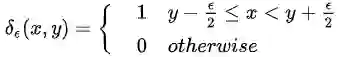







为了计算梯度密度,最简单的算法时间复杂度为 









近似的修正参数为

利用 

因为loss的计算是基于梯度密度函数,而梯度密度函数根据一个batch中的数据得到,一个batch的统计结果是有噪声的。与batch normalization相同,作者用Exponential moving average来解决这个问题,也就是


具体的实验结果和网络结构大家可以阅读论文,此处也不再提及。
总结
Focal Loss和Gradient Harmonizing Mechanism在目标检测中可以很好的处理类别不平衡问题,那么在其他领域是否也会有效果。比如在pairwise的推荐中,肯定也会有easy pair和hard pair,在一些业务场景下这些也是不平衡的,是否可以用这种方法来更好的提升效果,这个也待笔者尝试。
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个在看啦~