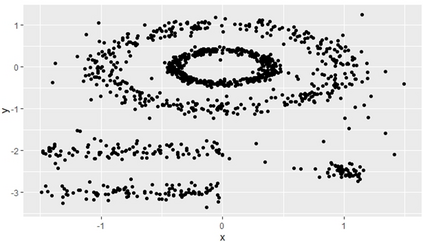
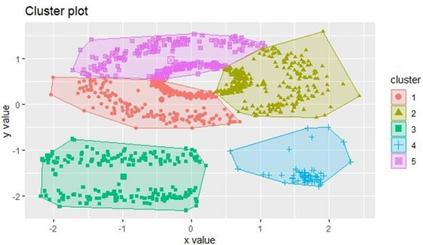
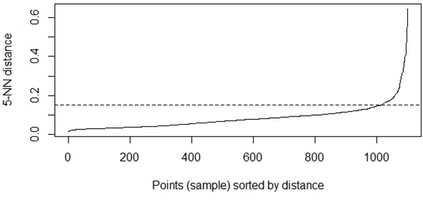
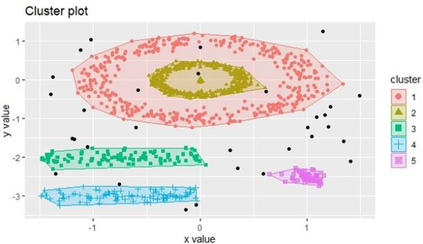
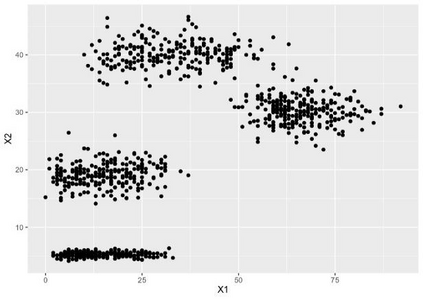
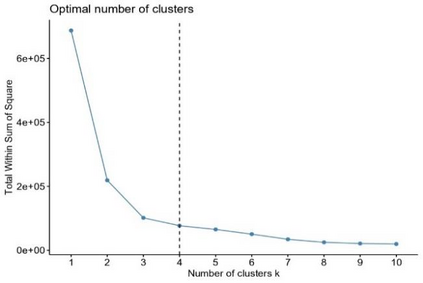
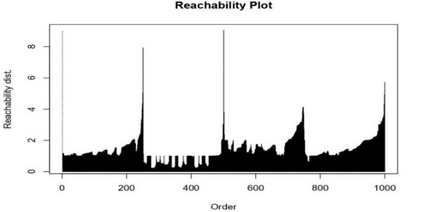
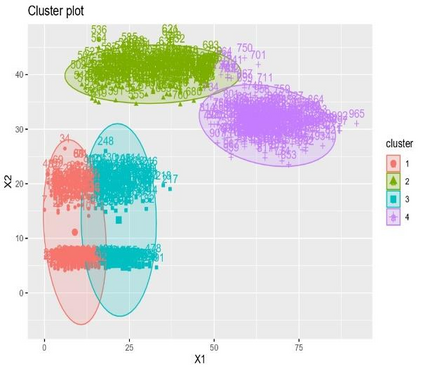
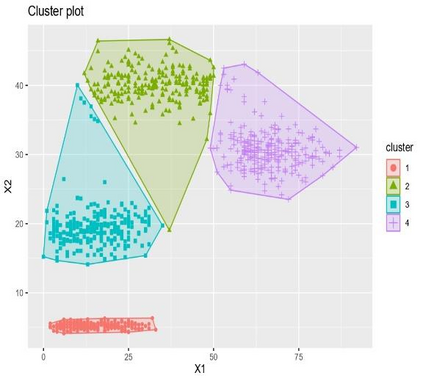
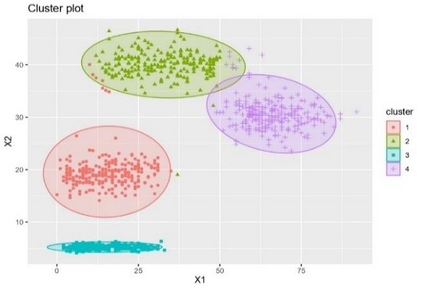
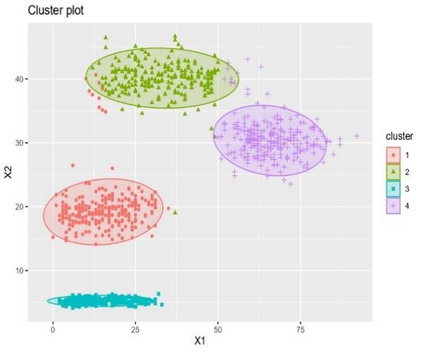
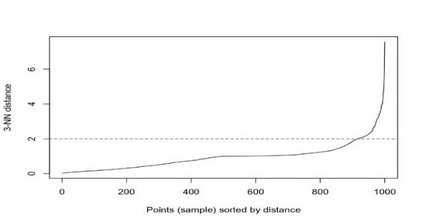
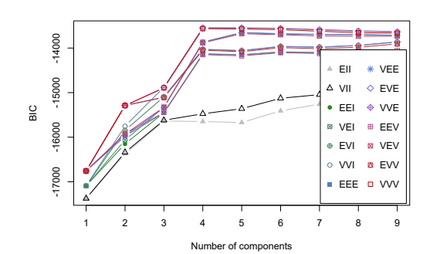
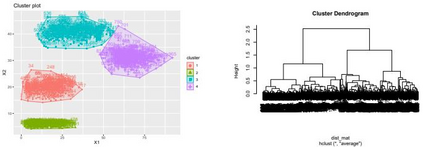
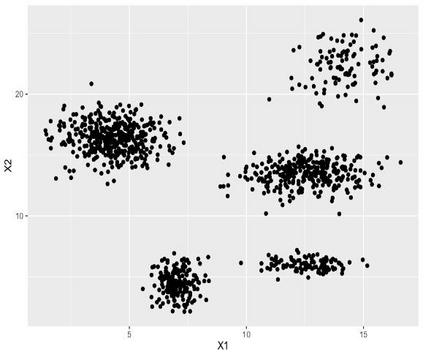
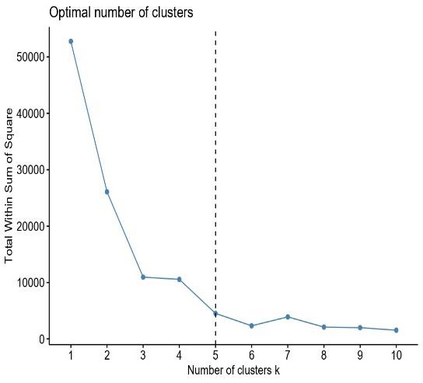
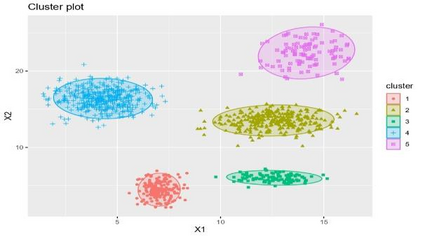
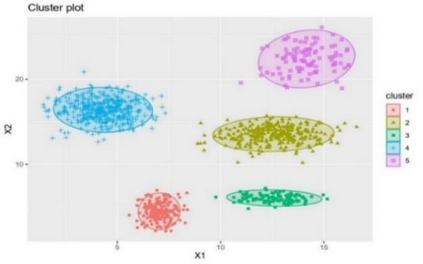
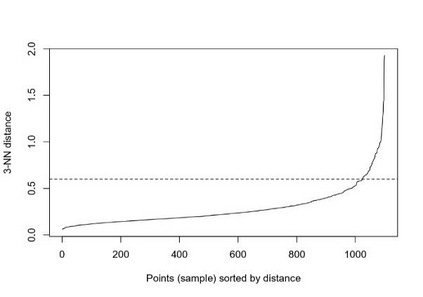
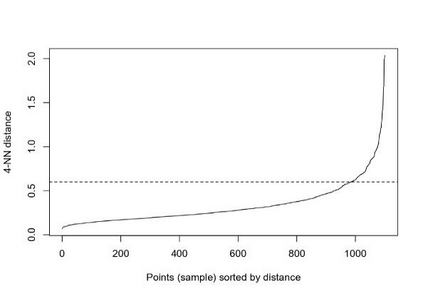
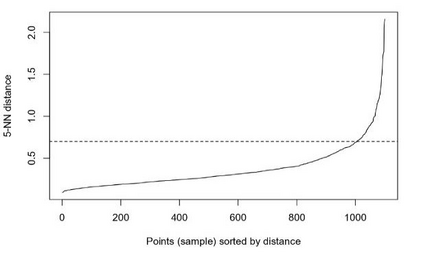
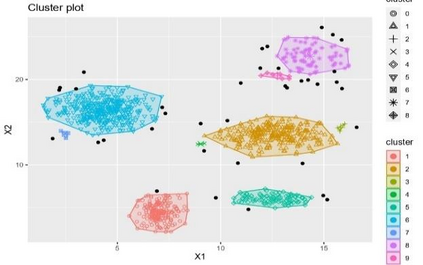
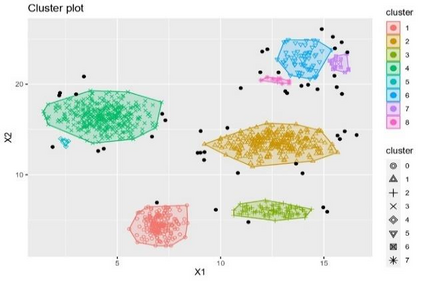
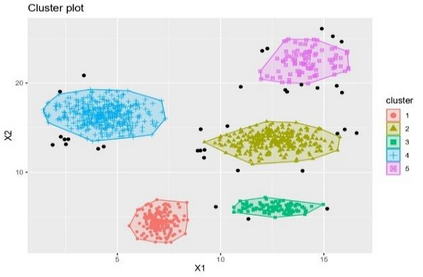
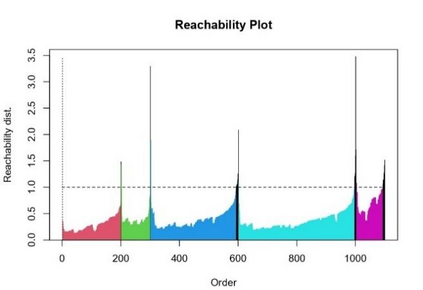
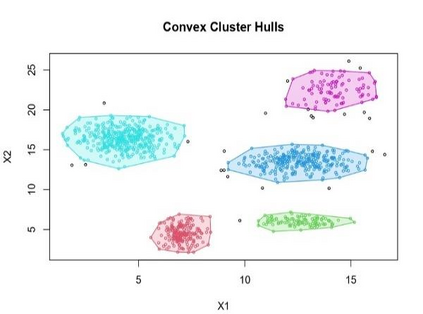
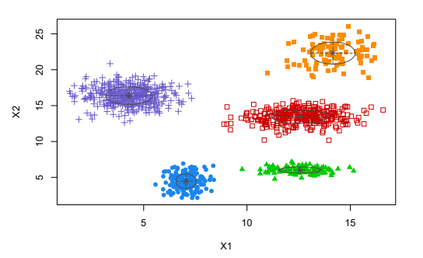
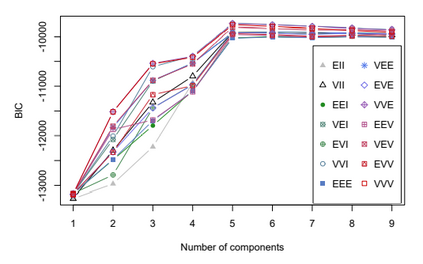
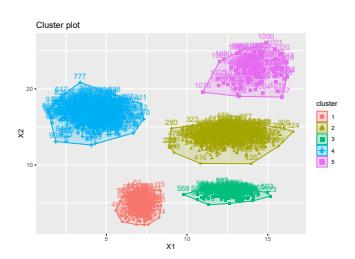
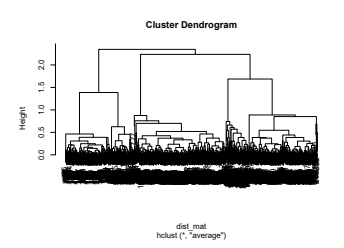
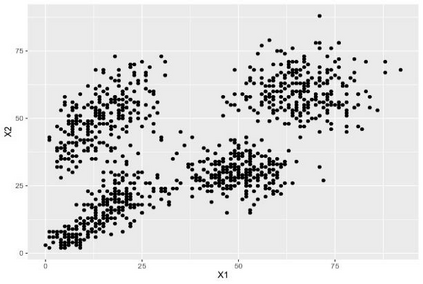
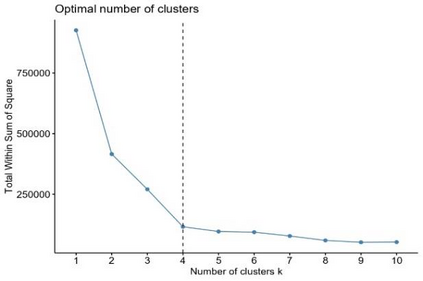
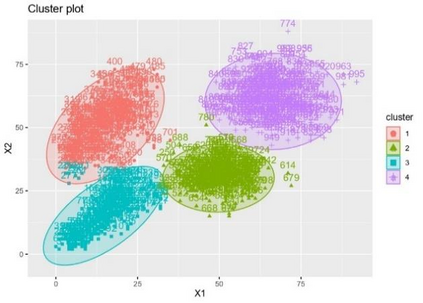
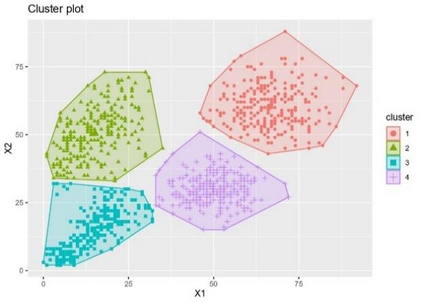
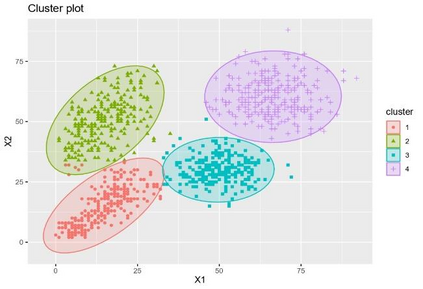
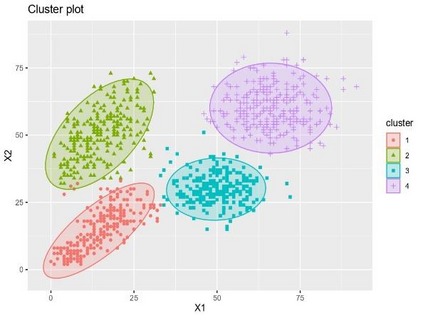
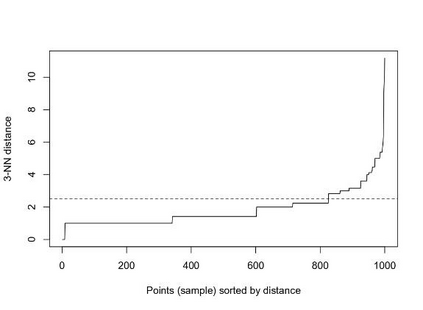
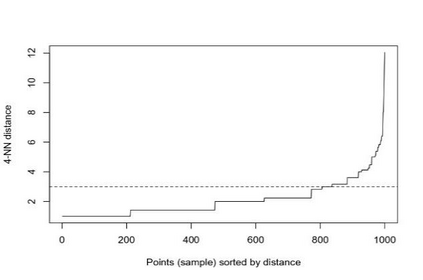
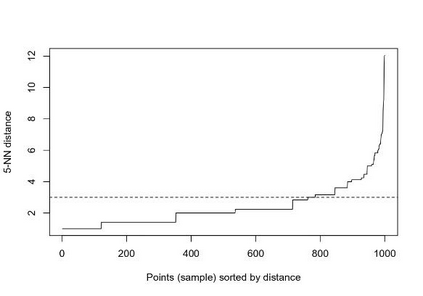
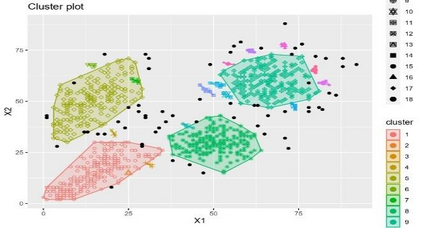
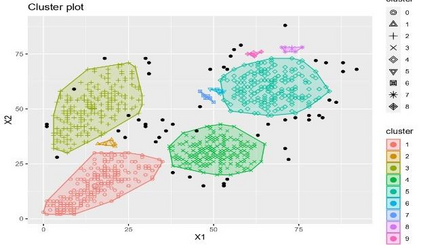
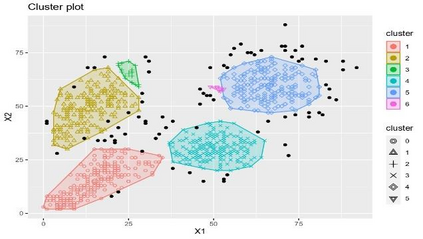
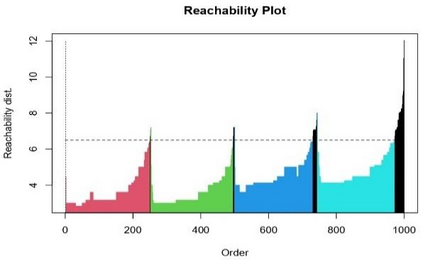
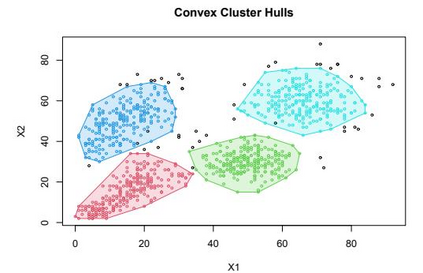
Clustering is an unsupervised machine learning methodology where unlabeled elements/objects are grouped together aiming to the construction of well-established clusters that their elements are classified according to their similarity. The goal of this process is to provide a useful aid to the researcher that will help her/him to identify patterns among the data. Dealing with large databases, such patterns may not be easily detectable without the contribution of a clustering algorithm. This article provides a deep description of the most widely used clustering methodologies accompanied by useful presentations concerning suitable parameter selection and initializations. Simultaneously, this article not only represents a review highlighting the major elements of examined clustering techniques but emphasizes the comparison of these algorithms' clustering efficiency based on 3 datasets, revealing their existing weaknesses and capabilities through accuracy and complexity, during the confrontation of discrete and continuous observations. The produced results help us extract valuable conclusions about the appropriateness of the examined clustering techniques in accordance with the dataset's size.
翻译:集束是一种无人监督的机器学习方法,将未贴标签的元素/对象组合在一起,目的是构建成熟的组群,使其元素按照相似性分类。这一过程的目的是向研究人员提供有用的帮助,帮助她/他辨别数据中的模式。在处理大型数据库时,如果没有集成算法的帮助,这种模式可能不容易被探测出来。这一条深入描述了最广泛使用的组群方法,并伴有关于适当参数选择和初始化的有用演示。同时,这一条不仅代表一项审查,突出已检查的组群技术的主要内容,而且强调根据3套数据集比较这些算法的组群效率,在离散和连续观测的对立期间,通过准确性和复杂性显示其现有的弱点和能力。所产生的结果帮助我们得出关于已审查的组群技术是否适合数据集大小的宝贵结论。