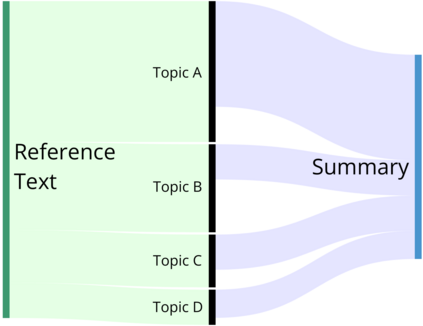
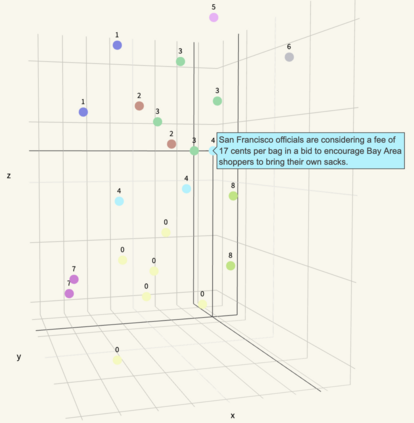
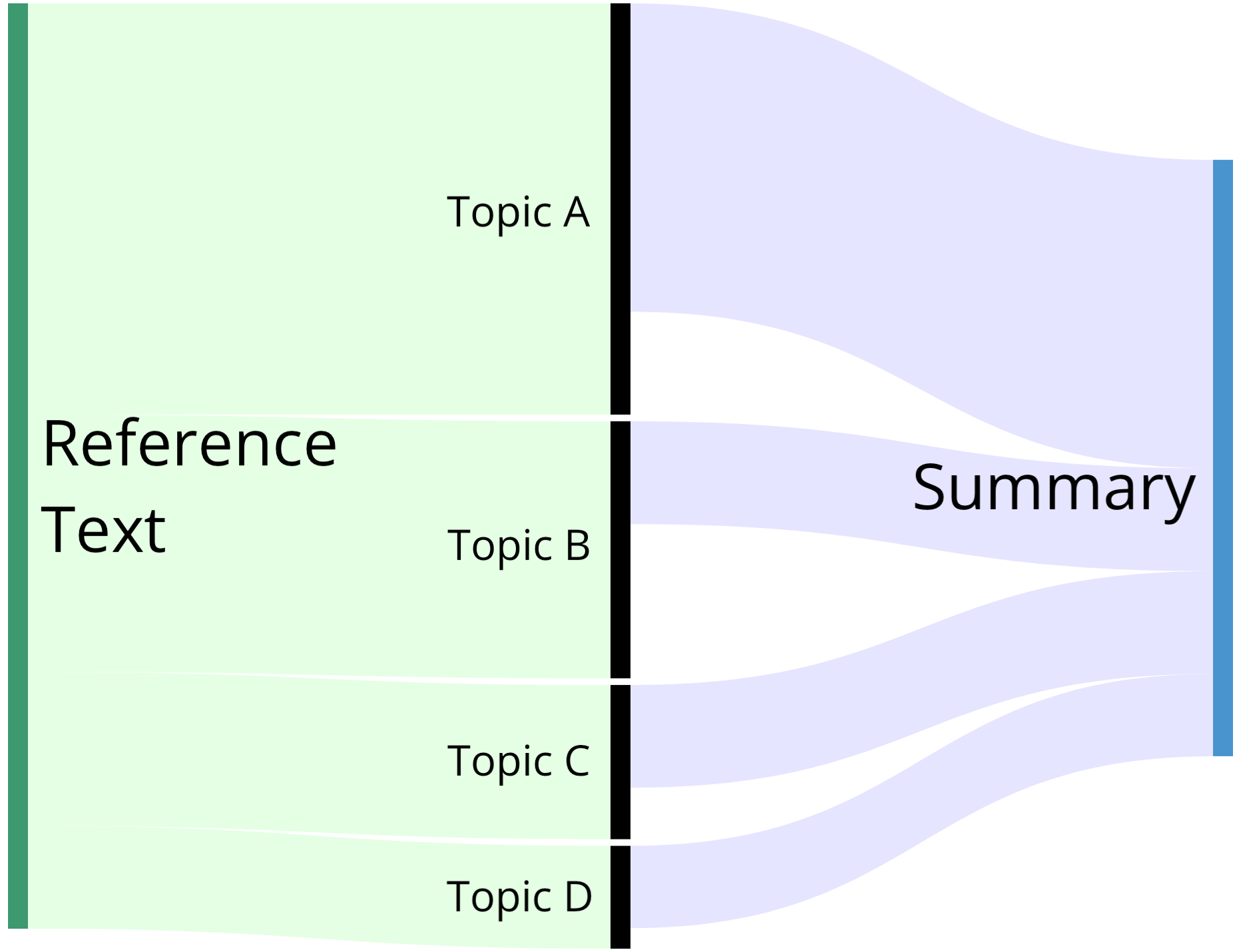
Despite extensive recent advances in summary generation models, evaluation of auto-generated summaries still widely relies on single-score systems insufficient for transparent assessment and in-depth qualitative analysis. Towards bridging this gap, we propose the multifaceted interpretable summary evaluation method (MISEM), which is based on allocation of a summary's contextual token embeddings to semantic topics identified in the reference text. We further contribute an interpretability toolbox for automated summary evaluation and interactive visual analysis of summary scoring, topic identification, and token-topic allocation. MISEM achieves a promising .404 Pearson correlation with human judgment on the TAC'08 dataset.
翻译:尽管在摘要生成模型方面最近取得了广泛进展,但自动生成摘要的评价仍然广泛依赖单极系统,不足以进行透明的评估和深入的定性分析。为弥合这一差距,我们提议采用多方面可解释的简要评价方法(MISEM),该方法的基础是将摘要的背景符号嵌入参考文本中所确定的语义专题,我们进一步为对摘要评分、专题识别和象征性专题分配进行自动简要评估和互动直观分析提供了可解释的工具箱。MISEM实现了有希望的404 Pearson与人类对TAC'08数据集的判断的相关性。