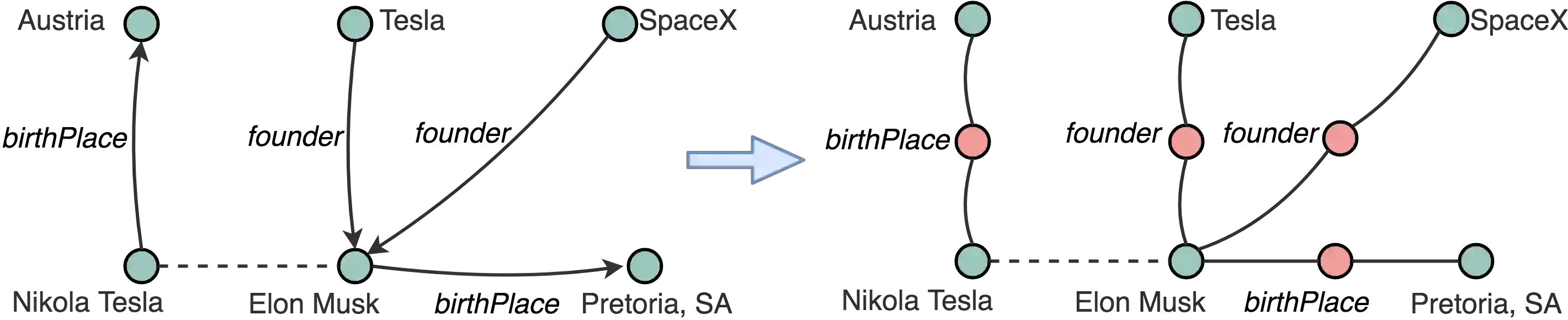
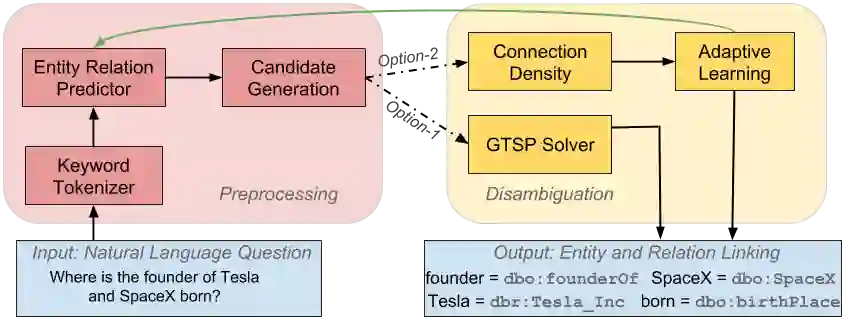
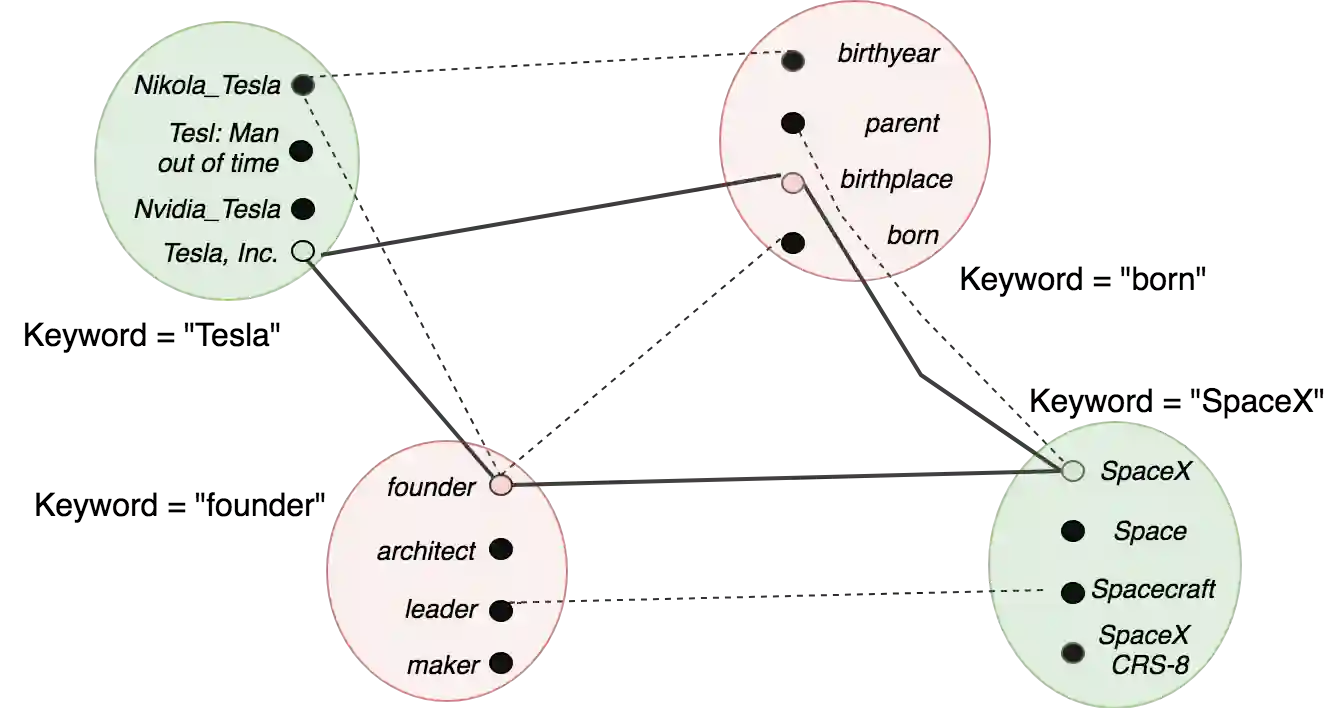
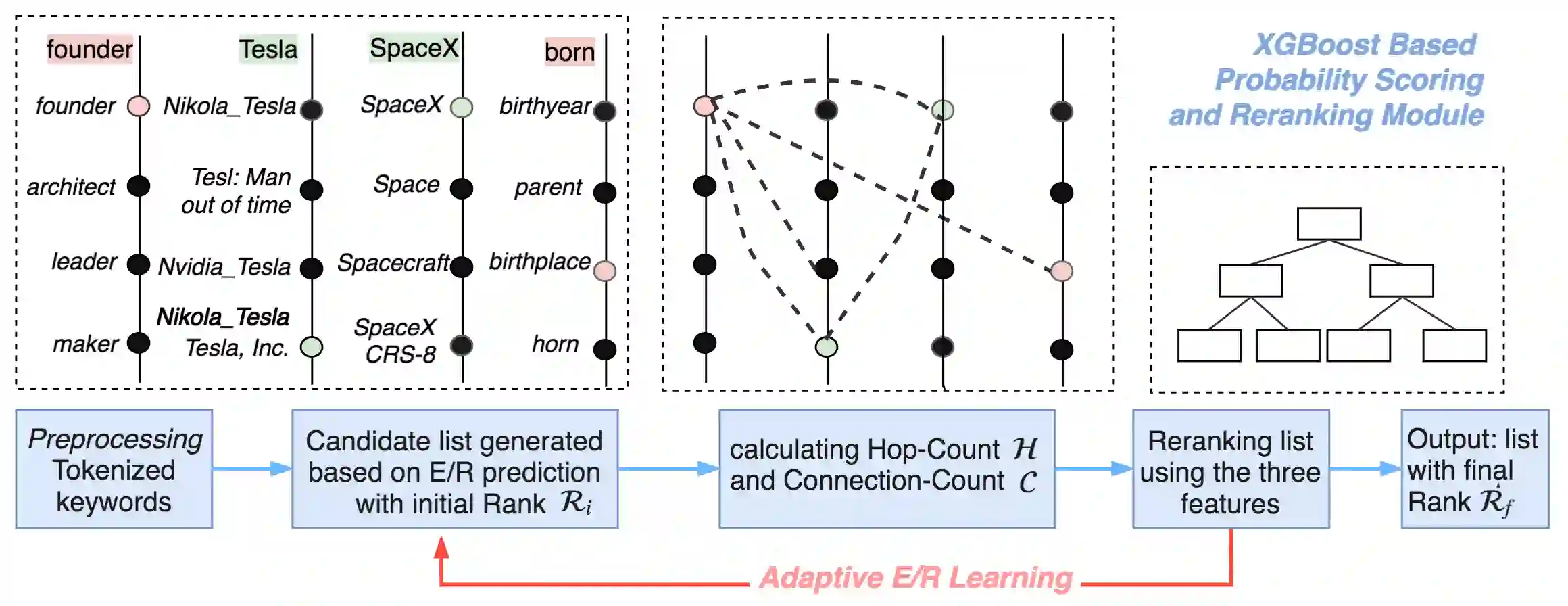
Many question answering systems over knowledge graphs rely on entity and relation linking components in order to connect the natural language input to the underlying knowledge graph. Traditionally, entity linking and relation linking have been performed either as dependent sequential tasks or as independent parallel tasks. In this paper, we propose a framework called EARL, which performs entity linking and relation linking as a joint task. EARL implements two different solution strategies for which we provide a comparative analysis in this paper: The first strategy is a formalisation of the joint entity and relation linking tasks as an instance of the Generalised Travelling Salesman Problem (GTSP). In order to be computationally feasible, we employ approximate GTSP solvers. The second strategy uses machine learning in order to exploit the connection density between nodes in the knowledge graph. It relies on three base features and re-ranking steps in order to predict entities and relations. We compare the strategies and evaluate them on a dataset with 5000 questions. Both strategies significantly outperform the current state-of-the-art approaches for entity and relation linking.
翻译:与知识图有关的许多解答系统都依赖于实体和关联部分,以便将自然语言输入与基本知识图连接起来。传统上,实体连接和关联是作为依附的相继任务或作为独立的平行任务进行的。在本文件中,我们提议了一个称为EARL的框架,将实体连接和关联作为联合任务。EARL执行两种不同的解决方案战略,我们在本文件中提供比较分析:第一个战略是将联合实体正规化,将任务关联作为通用旅行推销员问题(GTSP)的一个实例。为了计算可行,我们使用了近似GTSP解答器。第二个战略利用机器学习来利用知识图中节点之间的连接密度。它依靠三个基本特征和重新排列步骤来预测实体和关系。我们将这些战略与5000个数据集进行比较并评估。两种战略都大大超越了实体和关联当前的最新方法。