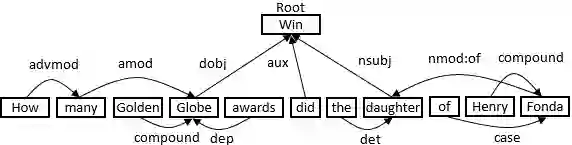
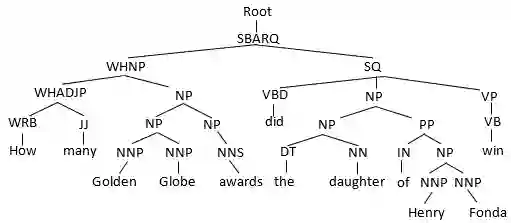
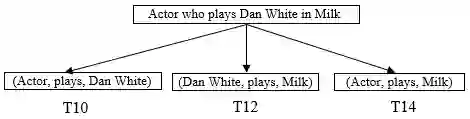
Question Answering (QA) systems provide easy access to the vast amount of knowledge without having to know the underlying complex structure of the knowledge. The research community has provided ad hoc solutions to the key QA tasks, including named entity recognition and disambiguation, relation extraction and query building. Furthermore, some have integrated and composed these components to implement many tasks automatically and efficiently. However, in general, the existing solutions are limited to simple and short questions and still do not address complex questions composed of several sub-questions. Exploiting the answer to complex questions is further challenged if it requires integrating knowledge from unstructured data sources, i.e., textual corpus, as well as structured data sources, i.e., knowledge graphs. In this paper, an approach (HCqa) is introduced for dealing with complex questions requiring federating knowledge from a hybrid of heterogeneous data sources (structured and unstructured). We contribute in developing (i) a decomposition mechanism which extracts sub-questions from potentially long and complex input questions, (ii) a novel comprehensive schema, first of its kind, for extracting and annotating relations, and (iii) an approach for executing and aggregating the answers of sub-questions. The evaluation of HCqa showed a superior accuracy in the fundamental tasks, such as relation extraction, as well as the federation task.
翻译:问题解答(QA)系统可以方便地获取大量知识,而不必了解知识的基本复杂结构; 研究界为关键的质量解析任务提供了临时解决办法,包括名称实体的识别和模糊、关系提取和查询建设; 此外,有些已整合和组成这些组成部分,以便自动和高效地执行许多任务; 然而,一般而言,现有解决办法仅限于简单和简短的问题,仍然没有解决由几个子问题构成的复杂问题; 如果需要综合来自非结构化数据来源的知识,即文本材料,以及结构化数据来源,即知识图表,那么对复杂问题的解析就会受到进一步挑战; 研究界为关键的质量解析提供了临时解决办法,包括名称实体的识别和模糊、关系提取复杂数据来源混合(结构化和结构化)的复杂问题; 然而,现有的解决办法仅限于简单和简短的问题,仍然没有解决由几个子问题构成的复杂问题; 如果需要综合数据来源(即文字资料库)和结构化数据来源(即知识图)的知识,以及结构化数据来源,即结构化数据来源,即知识图; 本文采用了一种方法(Hqqqa)处理复杂的复杂和结构关系中的新的全面计划,我们协助制定(一)的分解机制,作为基础的分解的分解),作为基础分析的分,作为基础的分,我们的任务。