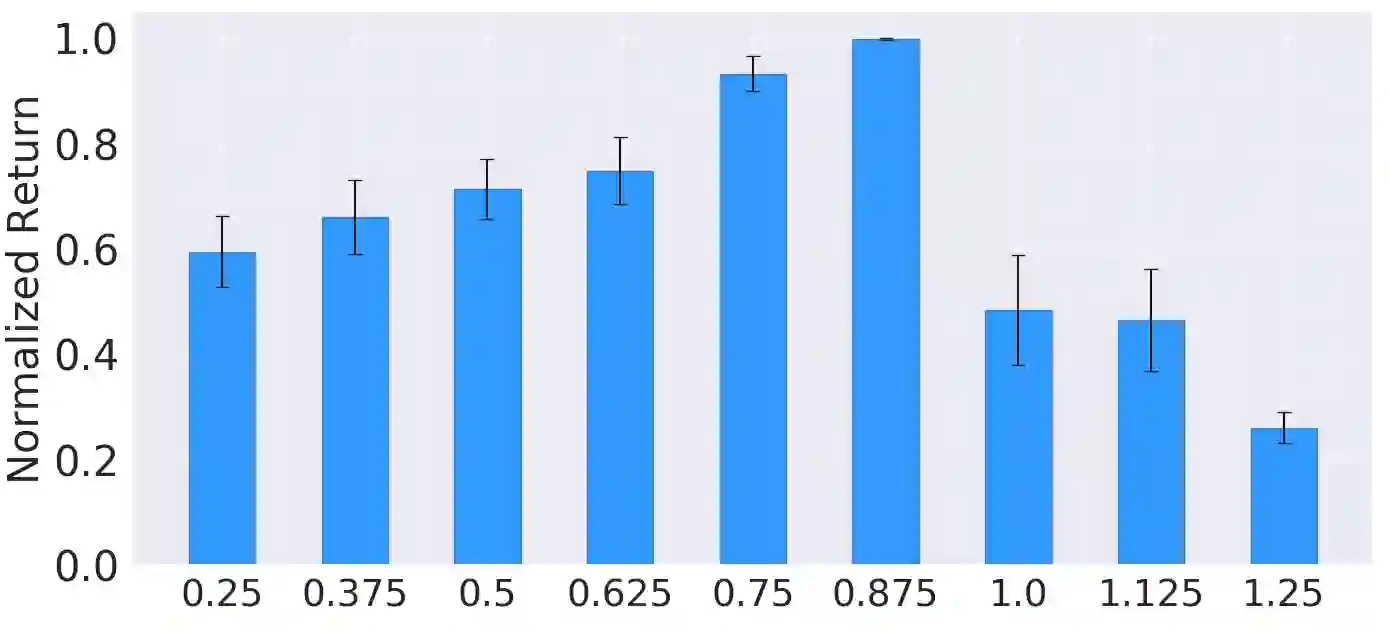
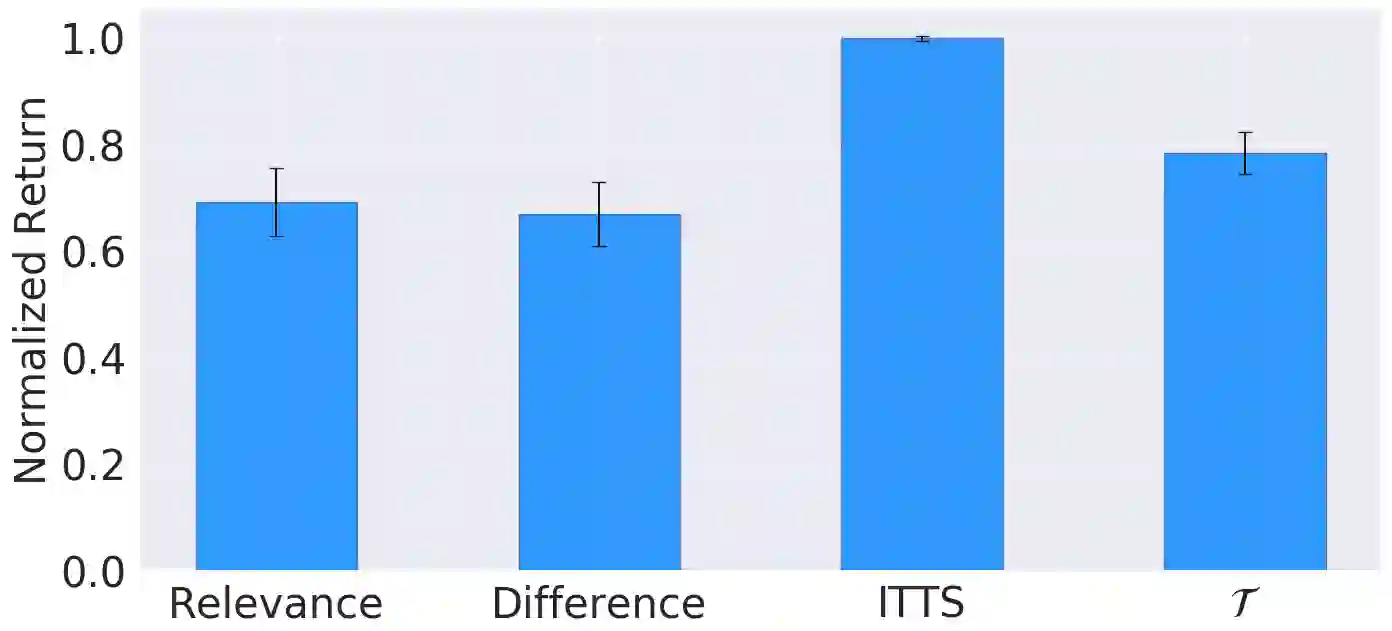
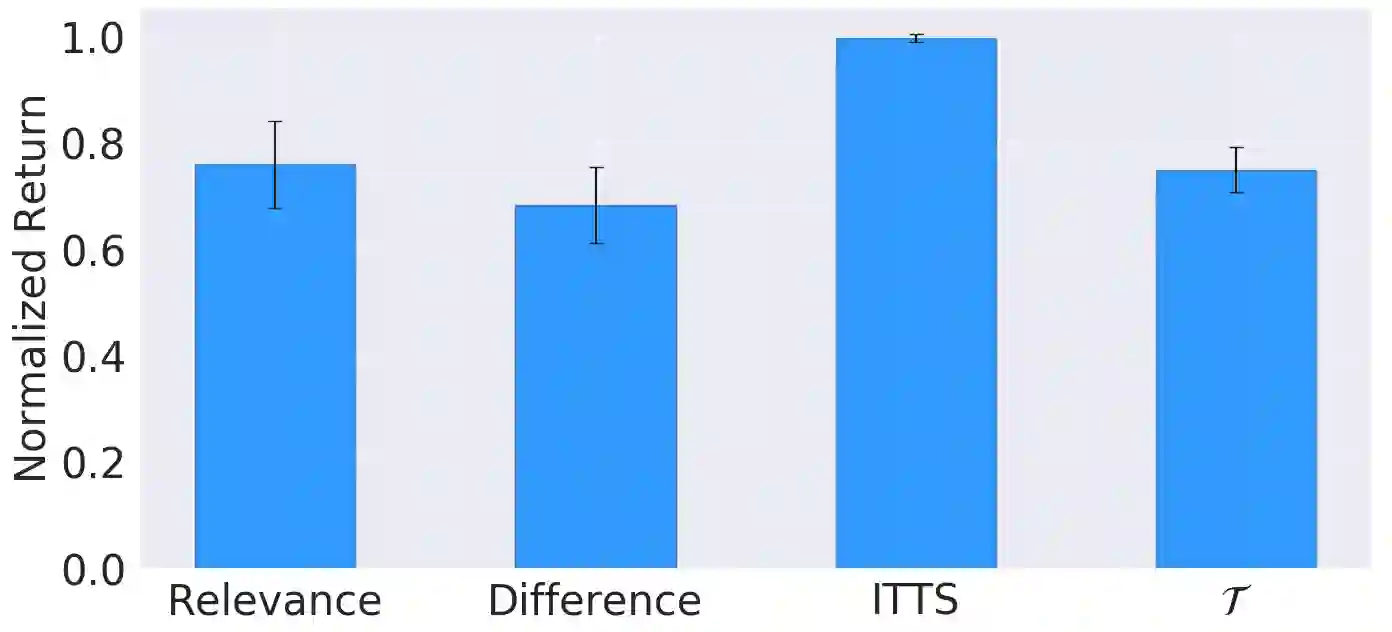
In Meta-Reinforcement Learning (meta-RL) an agent is trained on a set of tasks to prepare for and learn faster in new, unseen, but related tasks. The training tasks are usually hand-crafted to be representative of the expected distribution of test tasks and hence all used in training. We show that given a set of training tasks, learning can be both faster and more effective (leading to better performance in the test tasks), if the training tasks are appropriately selected. We propose a task selection algorithm, Information-Theoretic Task Selection (ITTS), based on information theory, which optimizes the set of tasks used for training in meta-RL, irrespectively of how they are generated. The algorithm establishes which training tasks are both sufficiently relevant for the test tasks, and different enough from one another. We reproduce different meta-RL experiments from the literature and show that ITTS improves the final performance in all of them.
翻译:在元加强学习(meta-RL)中,一个代理机构接受了一系列任务的培训,以准备和学习更快的新任务、隐形任务和相关任务。培训任务通常是手工制作的,以代表测试任务的预期分配,因此全部用于培训。我们显示,如果适当选择培训任务,如果有一套培训任务,学习可以更快和更有效(导致更好地执行测试任务)。我们根据信息理论提出了任务选择算法,即信息理论任务选择(ITTS),该算法优化了用于元研究培训的一套任务,而不论这些任务是如何产生的。算法确定了哪些培训任务与测试任务充分相关,而且彼此差异也很大。我们从文献中复制了不同的元-RL实验,并表明ITTS改进了所有这些任务的最后性能。