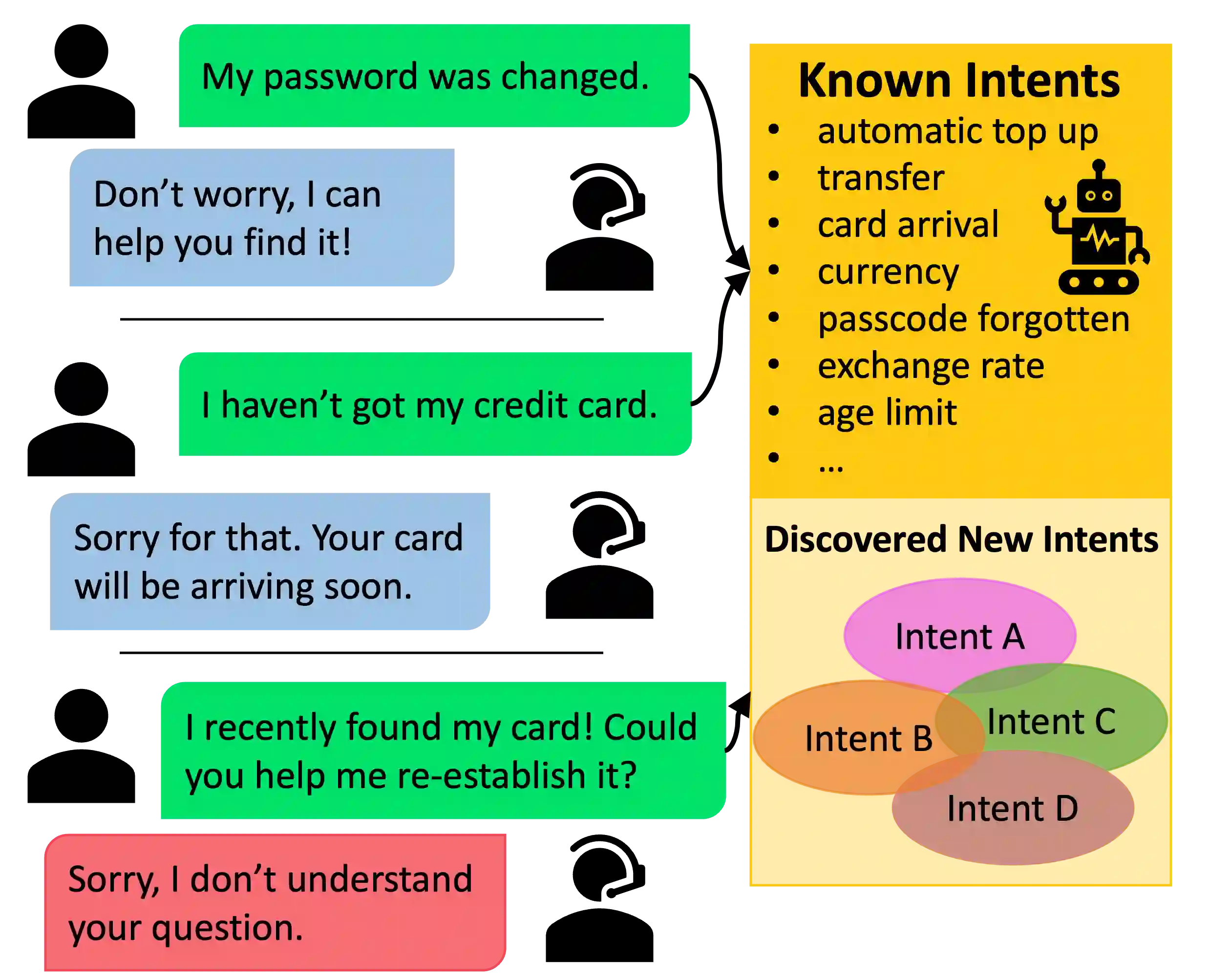
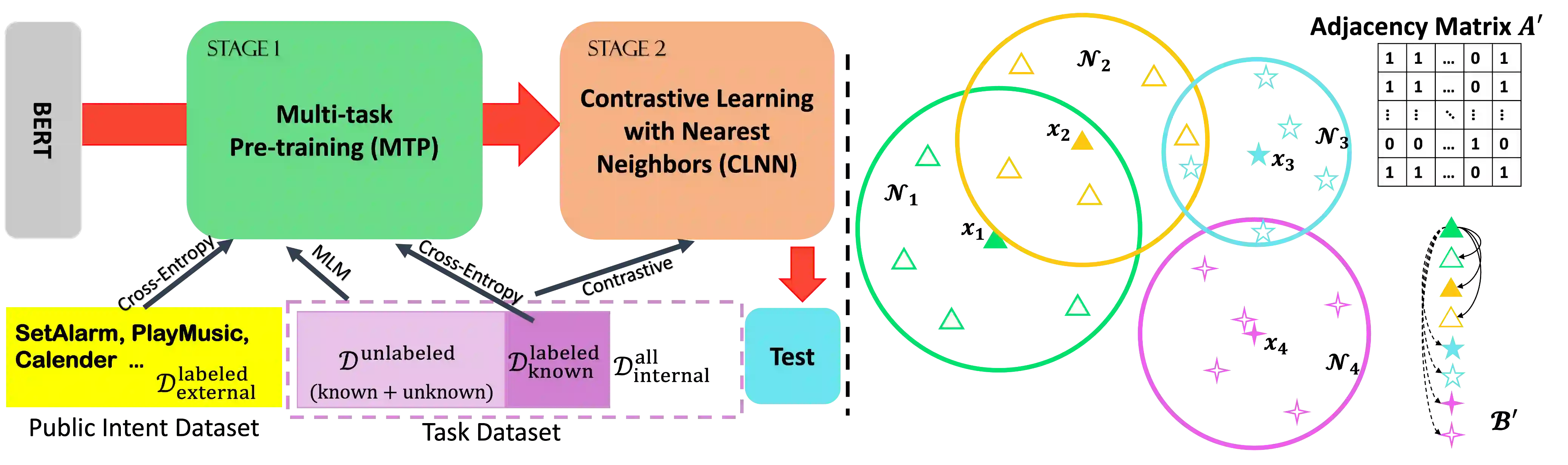
New intent discovery aims to uncover novel intent categories from user utterances to expand the set of supported intent classes. It is a critical task for the development and service expansion of a practical dialogue system. Despite its importance, this problem remains under-explored in the literature. Existing approaches typically rely on a large amount of labeled utterances and employ pseudo-labeling methods for representation learning and clustering, which are label-intensive, inefficient, and inaccurate. In this paper, we provide new solutions to two important research questions for new intent discovery: (1) how to learn semantic utterance representations and (2) how to better cluster utterances. Particularly, we first propose a multi-task pre-training strategy to leverage rich unlabeled data along with external labeled data for representation learning. Then, we design a new contrastive loss to exploit self-supervisory signals in unlabeled data for clustering. Extensive experiments on three intent recognition benchmarks demonstrate the high effectiveness of our proposed method, which outperforms state-of-the-art methods by a large margin in both unsupervised and semi-supervised scenarios. The source code will be available at \url{https://github.com/zhang-yu-wei/MTP-CLNN}.
翻译:新的意图发现旨在从用户的言语中发现新的意图类别,以扩大一套支持的意图类别;这是发展和服务扩展实际对话系统的关键任务;尽管这个问题很重要,但这个问题在文献中仍未得到充分探讨;现有方法通常依赖大量贴标签的言语,并采用假标签标签标签式的学习和集群方法,这些语言是标签密集、低效和不准确的。在本文件中,我们为两个新的意图发现的重要研究问题提供了新的解决办法:(1) 如何学习语义表达和(2) 如何改进集群表达方式。特别是,我们首先提出一个多任务前培训战略,利用丰富的无标签数据与外部标签式的数据一起进行代表性学习。然后,我们设计新的对比性损失,以利用未贴标签式数据中的自我监督信号进行集群。关于三个意向确认基准的广泛试验表明我们拟议方法的高度效力,该方法在未经监督的和半监督的情景下,以大幅度来完善状态-艺术方法。源代码将在未受监督的和半监督的情景中提供。