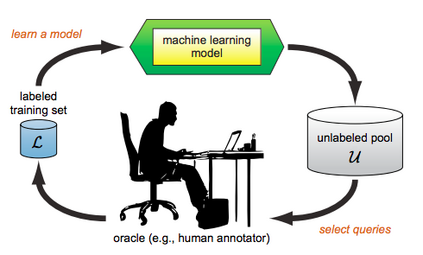
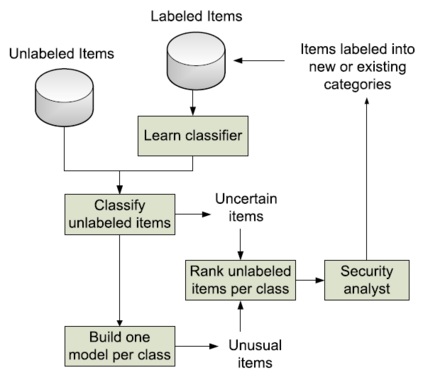
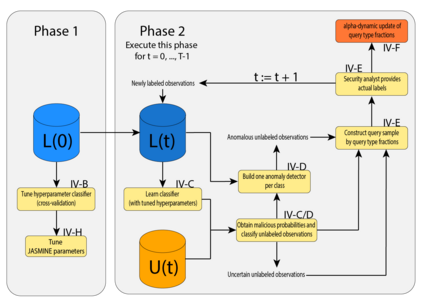
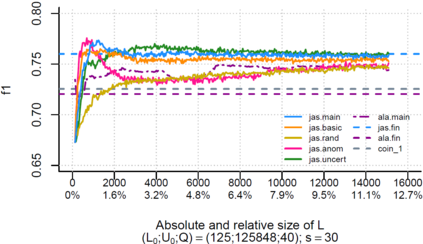
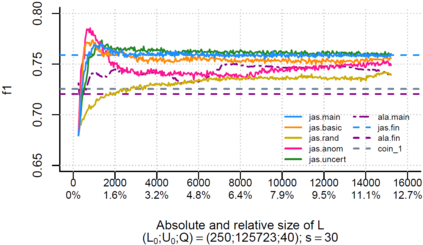
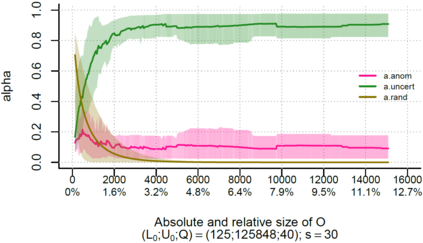
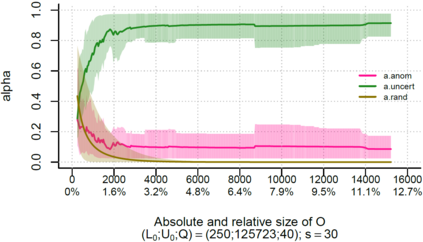
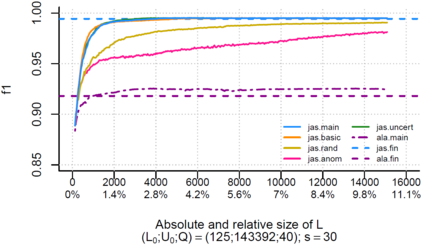
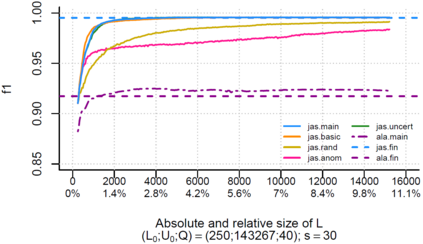
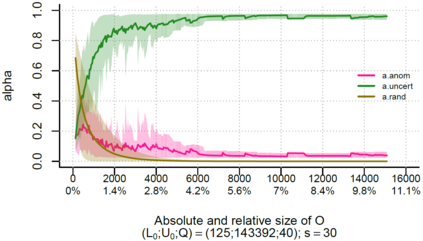
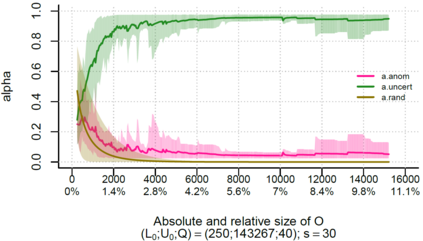
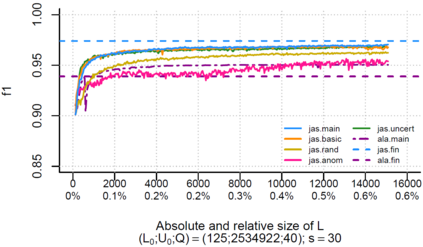
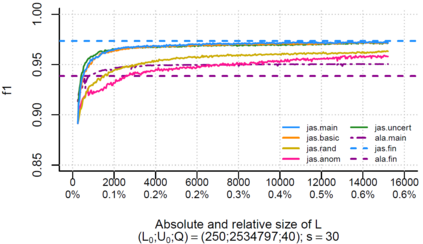
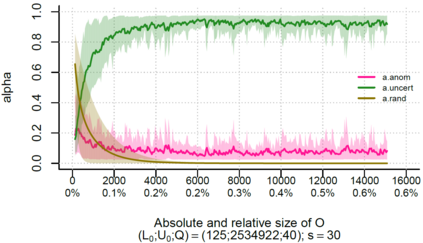
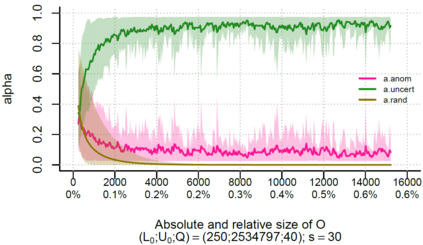
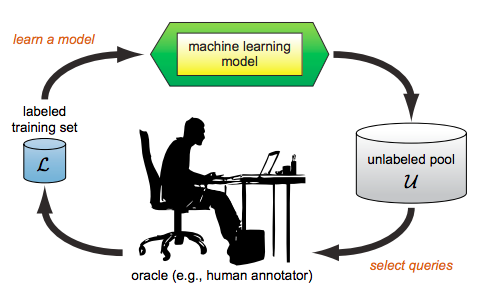
Over the past decade, the advent of cybercrime has accelarated the research on cybersecurity. However, the deployment of intrusion detection methods falls short. One of the reasons for this is the lack of realistic evaluation datasets, which makes it a challenge to develop techniques and compare them. This is caused by the large amounts of effort it takes for a cyber analyst to classify network connections. This has raised the need for methods (i) that can learn from small sets of labeled data, (ii) that can make predictions on large sets of unlabeled data, and (iii) that request the label of only specially selected unlabeled data instances. Hence, Active Learning (AL) methods are of interest. These approaches choose speci?fic unlabeled instances by a query function that are expected to improve overall classi?cation performance. The resulting query observations are labeled by a human expert and added to the labeled set. In this paper, we propose a new hybrid AL method called Jasmine. Firstly, it determines how suitable each observation is for querying, i.e., how likely it is to enhance classi?cation. These properties are the uncertainty score and anomaly score. Secondly, Jasmine introduces dynamic updating. This allows the model to adjust the balance between querying uncertain, anomalous and randomly selected observations. To this end, Jasmine is able to learn the best query strategy during the labeling process. This is in contrast to the other AL methods in cybersecurity that all have static, predetermined query functions. We show that dynamic updating, and therefore Jasmine, is able to consistently obtain good and more robust results than querying only uncertainties, only anomalies or a ?fixed combination of the two.
翻译:在过去的十年中,网络犯罪的出现扩大了网络安全研究的范围。然而,入侵探测方法的部署却不尽如人意。原因之一是缺乏现实的评估数据集,这使得开发技术和比较技术成为挑战。这是网络分析员对网络连接进行分类所需的大量努力造成的。这增加了对方法的需要:(一) 从少量标签数据中学习的静态数据,(二) 能够对大量未贴标签的数据作出预测,以及(三) 要求仅对专门选定的未贴标签数据实例进行标签。因此,积极学习(AL) 方法令人感兴趣。这些方法选择了光谱?没有标签的数据集,从而导致开发技术并比较。因此,对网络连接进行分类分析需要花费大量精力。这增加了对以下方法的需要:(一) 可以从少量标签标签数据中学习,(二) 能够对大量无标签的数据进行预测, (二) 并且我们建议一个新的混合的AL方法叫做“茉莉”。首先, 它确定每次观察是否适合进行查询, 也就是说, 是否能够加强类比较?因此, 积极学习(AL) 的(AL) AL) 方法能够显示这种精确度和(rent) roal) 和(ral) 排序之间的结果。