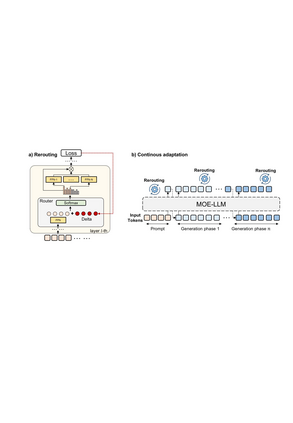
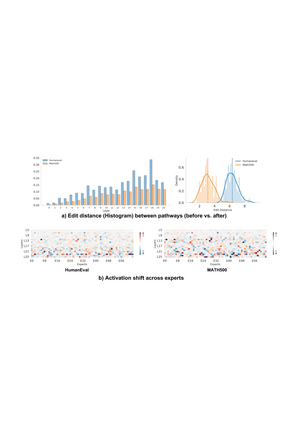
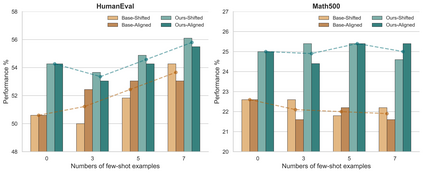
Mixture-of-Experts (MoE) models achieve efficient scaling through sparse expert activation, but often suffer from suboptimal routing decisions due to distribution shifts in deployment. While existing test-time adaptation methods could potentially address these issues, they primarily focus on dense models and require access to external data, limiting their practical applicability to MoE architectures. However, we find that, instead of relying on reference data, we can optimize MoE expert selection on-the-fly based only on input context. As such, we propose \textit{a data-free, online test-time framework} that continuously adapts MoE routing decisions during text generation without external supervision or data. Our method cycles between two phases: During the prefill stage, and later in regular intervals, we optimize the routing decisions of the model using self-supervision based on the already generated sequence. Then, we generate text as normal, maintaining the modified router until the next adaption. We implement this through lightweight additive vectors that only update router logits in selected layers, maintaining computational efficiency while preventing over-adaptation. The experimental results show consistent performance gains on challenging reasoning tasks while maintaining robustness to context shifts. For example, our method achieves a 5.5\% improvement on HumanEval with OLMoE. Furthermore, owing to its plug-and-play property, our method naturally complements existing test-time scaling techniques, e.g., achieving 6\% average gains when incorporated with self-consistency on DeepSeek-V2-Lite.
翻译:暂无翻译