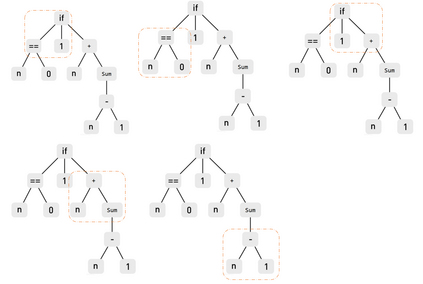
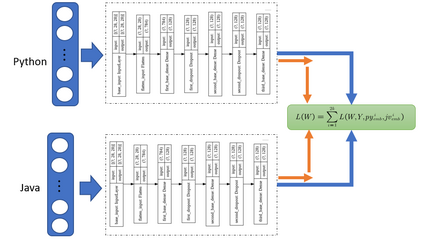
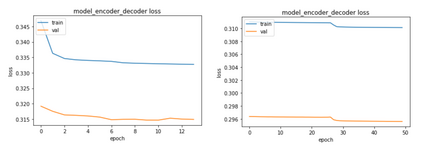
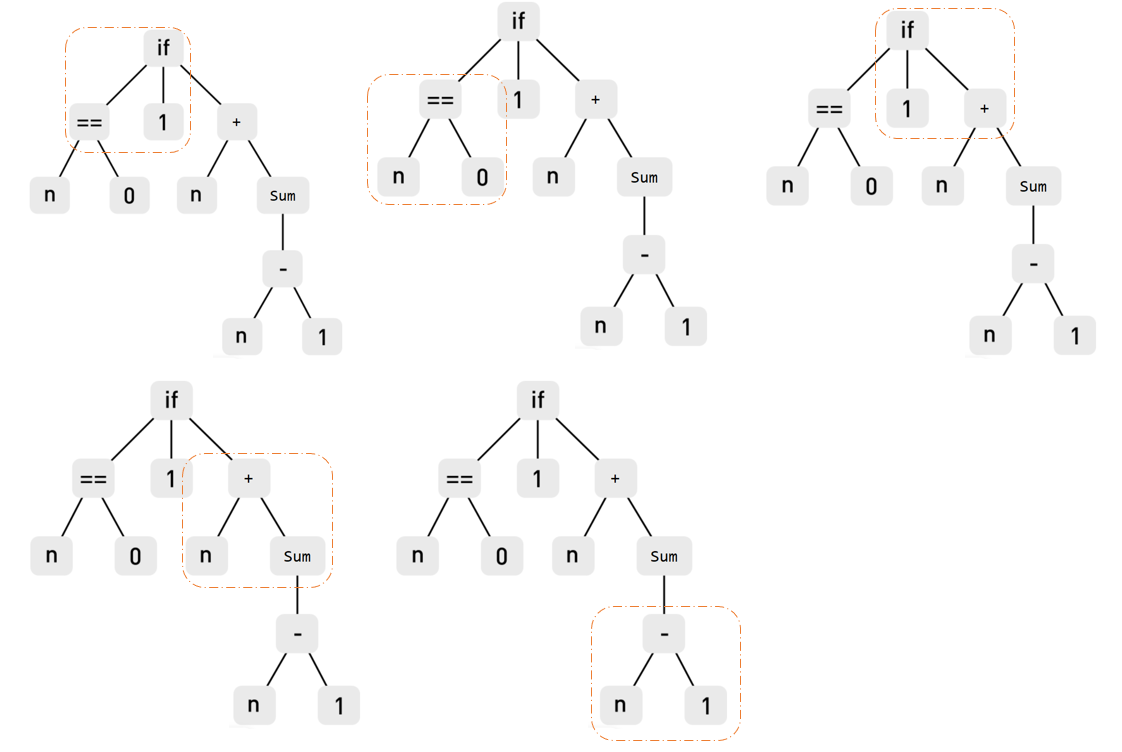
Software clones are beneficial to detect security gaps and software maintenance in one programming language or across multiple languages. The existing work on source clone detection performs well but in a single programming language. However, if a piece of code with the same functionality is written in different programming languages, detecting it is harder as different programming languages have a different lexical structure. Moreover, most existing work rely on manual feature engineering. In this paper, we propose a deep neural network model based on source code AST embeddings to detect cross-language clones in an end-to-end fashion of the source code without the need of the manual process to pinpoint similar features across different programming languages. To overcome data shortage and reduce overfitting, a Siamese architecture is employed. The design methodology of our model is twofold -- (a) it accepts AST embeddings as input for two different programming languages, and (b) it uses a deep neural network to learn abstract features from these embeddings to improve the accuracy of cross-language clone detection. The early evaluation of the model observes an average precision, recall and F-measure score of $0.99$, $0.59$ and $0.80$ respectively, which indicates that our model outperforms all available models in cross-language clone detection.
翻译:软件克隆有助于用一种编程语言或多种语言探测安全漏洞和软件维护。关于源克隆探测的现有工作运行良好,但使用一种单一编程语言。然而,如果用不同的编程语言写出一个功能相同的代码,则由于不同的编程语言具有不同的编程语言结构,发现起来难度更大。此外,大多数现有工作依赖人工特征工程。在本文件中,我们提议了以源代码AST嵌入为基础的深神经网络模型,以源代码的端至端方式探测跨语言克隆,而无需人工程序来确定不同编程语言的类似特征。为了克服数据短缺和减少超配,将使用一个暹米结构。我们模型的设计方法有双重性 -- -- (a) 它接受AST嵌入两种不同的编程语言,以及(b) 它使用深层的神经网络来学习这些嵌入的抽象特征,以提高跨语言克隆探测的准确性。对模型的早期评估显示平均精确度、回和F计量得分为0.99美元、0.59美元和0.80美元。