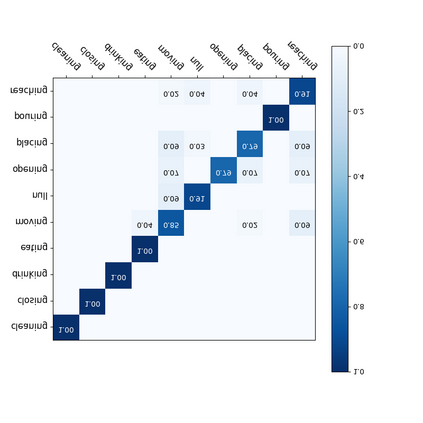
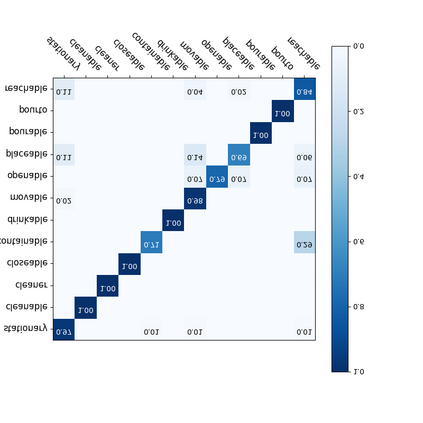
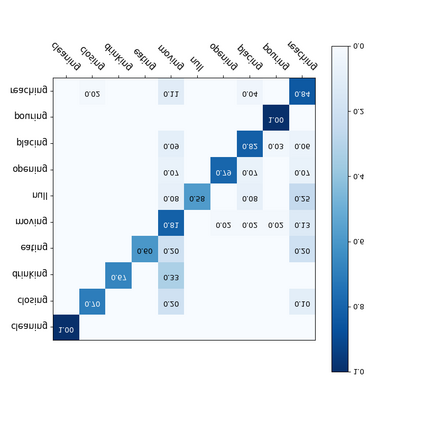
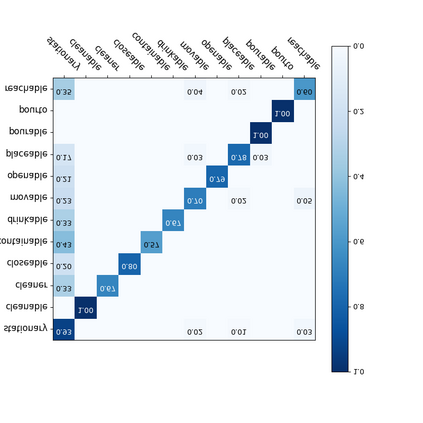
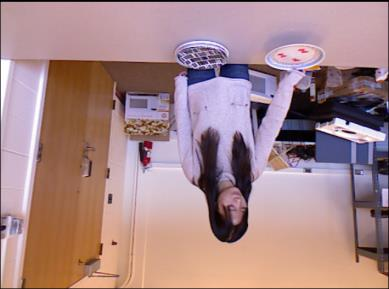
For a given video-based Human-Object Interaction scene, modeling the spatio-temporal relationship between humans and objects are the important cue to understand the contextual information presented in the video. With the effective spatio-temporal relationship modeling, it is possible not only to uncover contextual information in each frame but also to directly capture inter-time dependencies. It is more critical to capture the position changes of human and objects over the spatio-temporal dimension when their appearance features may not show up significant changes over time. The full use of appearance features, the spatial location and the semantic information are also the key to improve the video-based Human-Object Interaction recognition performance. In this paper, Spatio-Temporal Interaction Graph Parsing Networks (STIGPN) are constructed, which encode the videos with a graph composed of human and object nodes. These nodes are connected by two types of relations: (i) spatial relations modeling the interactions between human and the interacted objects within each frame. (ii) inter-time relations capturing the long range dependencies between human and the interacted objects across frame. With the graph, STIGPN learn spatio-temporal features directly from the whole video-based Human-Object Interaction scenes. Multi-modal features and a multi-stream fusion strategy are used to enhance the reasoning capability of STIGPN. Two Human-Object Interaction video datasets, including CAD-120 and Something-Else, are used to evaluate the proposed architectures, and the state-of-the-art performance demonstrates the superiority of STIGPN.
翻译:对于基于视频的人类- 时间互动场景, 模拟人与对象之间的时空关系是理解视频中背景信息的重要提示。 通过有效的时空空间关系建模, 不仅可以在每个框中发现背景信息, 还可以直接捕捉时际依赖性。 当人和对象的外观特征可能不会随时间变化而出现显著变化时, 捕捉在空间- 时空维度上的人和对象的位置变化更为关键。 充分利用外观特征、 空间位置和语义信息也是改进视频- 人类- 对象互动互动互动互动的识别功能的关键 。 在本文中, Spatio- 时空互动图分析网络( STIGN) 不仅可以在每个框中发现背景中发现背景中的背景信息, 直接捕捉到由人和对象组成的图表。 这些节点与两种类型的关系是:(i) 模拟人类与互动对象之间的空间关系, 在每个框中, 空间- 图像- 图像- 图像- 图像- 和图像- 图像- 图像- 图像- 图像- 图像- 图像- 图像- 系统- 系统- 和图像- 图像- 图像- 图像- 图像- 图像- 图像- 系统- 图像- 系统- 和图像- 图像- 图像- 图像- 图像- 图像- 图像- 图像- 系统- 系统- 图像- 图像- 图像- 系统- 系统- 系统- 和图像- 图像- 系统- 系统- 系统- 系统- 图像- 系统- 系统- 系统- 系统- 系统- 系统- 系统- 系统- 系统- 系统- 系统- 系统- 系统- 系统- 和图像- 系统- 系统- 系统- 和互动- 系统- 系统- 系统- 系统- 系统- 系统- 系统- 、 和图像- 系统- 、 系统- 、 、 、 、 和图像- 、 、 、 、 和图像- 系统- 和图像- 和图像- 系统- 系统- 系统- 系统- 和图像- 、 、 、 、 、