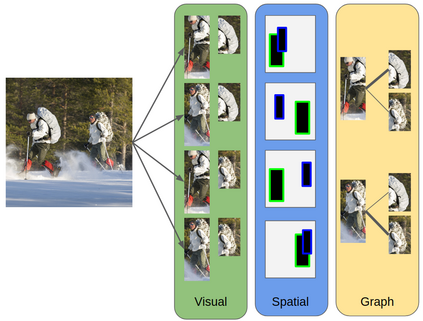
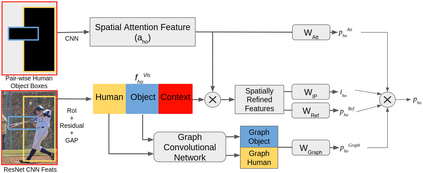
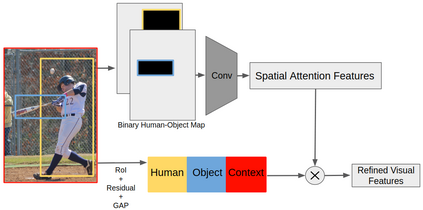
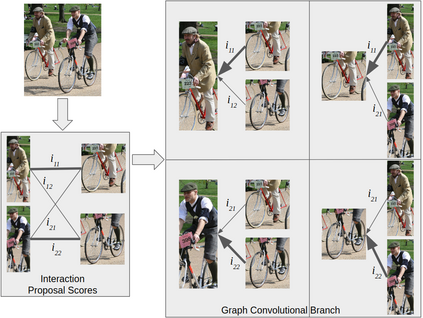
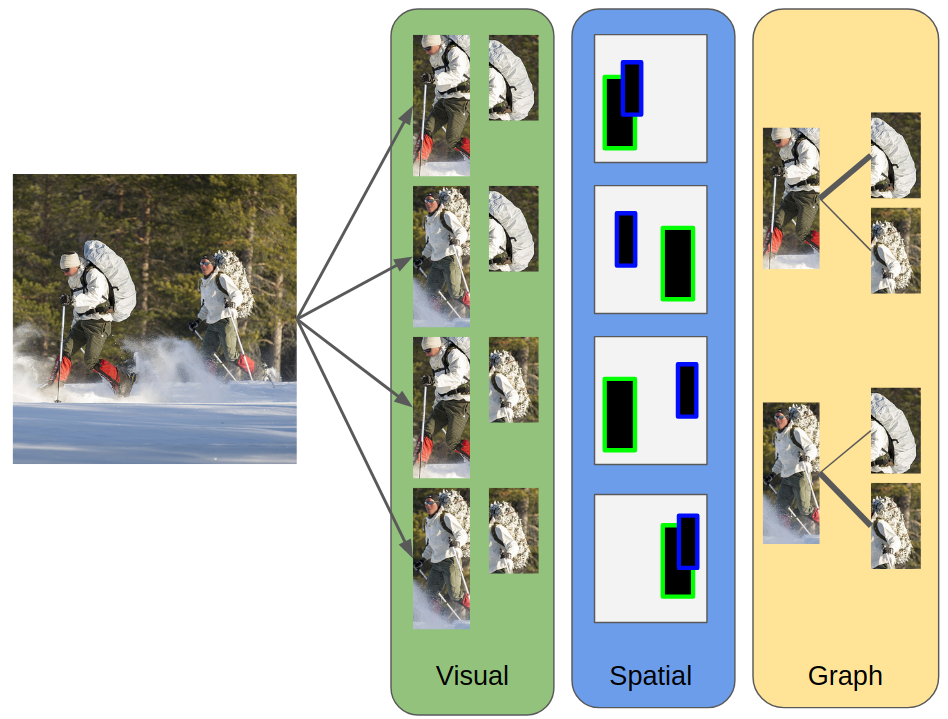
Comprehensive visual understanding requires detection frameworks that can effectively learn and utilize object interactions while analyzing objects individually. This is the main objective in Human-Object Interaction (HOI) detection task. In particular, relative spatial reasoning and structural connections between objects are essential cues for analyzing interactions, which is addressed by the proposed Visual-Spatial-Graph Network (VSGNet) architecture. VSGNet extracts visual features from the human-object pairs, refines the features with spatial configurations of the pair, and utilizes the structural connections between the pair via graph convolutions. The performance of VSGNet is thoroughly evaluated using the Verbs in COCO (V-COCO) and HICO-DET datasets. Experimental results indicate that VSGNet outperforms state-of-the-art solutions by 8% or 4 mAP in V-COCO and 16% or 3 mAP in HICO-DET.
翻译:全面的视觉理解需要能够有效地学习和利用物体相互作用的探测框架,同时对物体进行单独分析。这是人体-物体相互作用(HOI)探测任务的主要目标。特别是,物体之间的相对空间推理和结构联系是分析相互作用的基本线索,拟议的视觉-空间-大地网(VSGNet)结构对此作了规定。VSGNet从人体-物体对子中提取视觉特征,用对子的空间配置改进功能,并通过图解组合利用对子之间的结构联系。VSGNet的性能利用COCO(V-COCO)和HICO-DET数据集中的Verbs进行彻底评估。实验结果表明,VSGNet在V-CO-CO和HiCO-DET中比最新工艺解决方案高出8%或4 mAP,在HiCO-DET中超过16%或3 mAP。