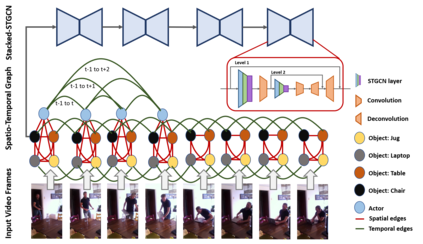
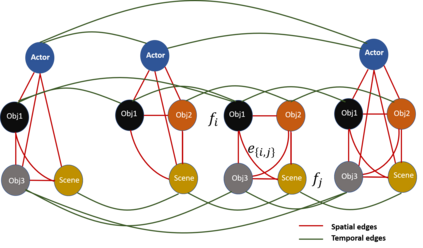
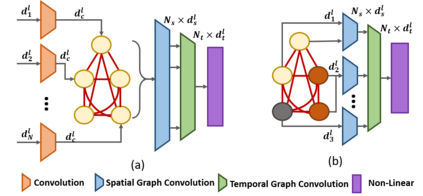
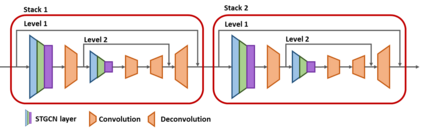
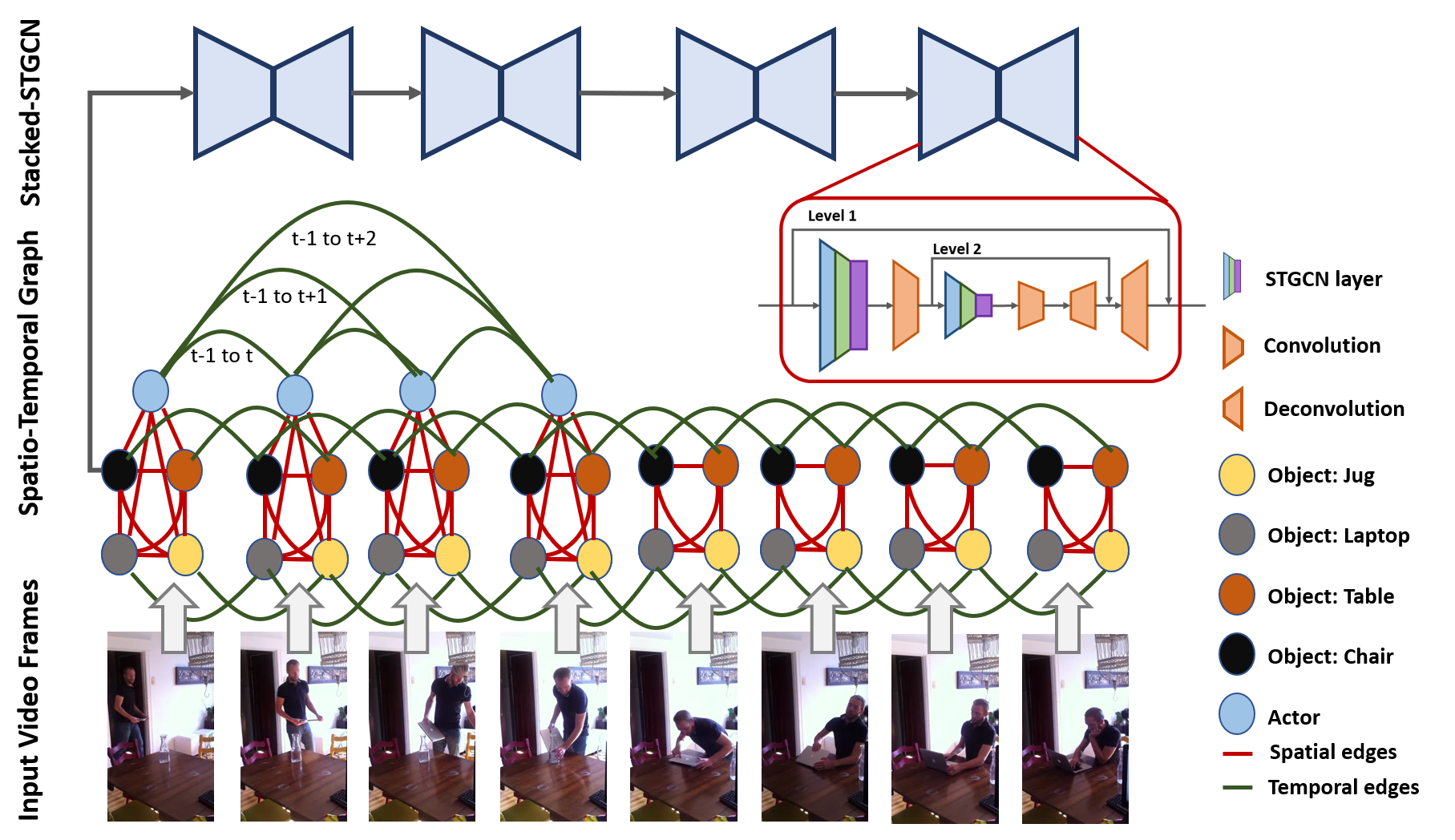
We propose novel Stacked Spatio-Temporal Graph Convolutional Networks (Stacked-STGCN) for action segmentation, i.e., predicting and localizing a sequence of actions over long videos. We extend the Spatio-Temporal Graph Convolutional Network (STGCN) originally proposed for skeleton-based action recognition to enable nodes with different characteristics (e.g., scene, actor, object, action, etc.), feature descriptors with varied lengths, and arbitrary temporal edge connections to account for large graph deformation commonly associated with complex activities. We further introduce the stacked hourglass architecture to STGCN to leverage the advantages of an encoder-decoder design for improved generalization performance and localization accuracy. We explore various descriptors such as frame-level VGG, segment-level I3D, RCNN-based object, etc. as node descriptors to enable action segmentation based on joint inference over comprehensive contextual information. We show results on CAD120 (which provides pre-computed node features and edge weights for fair performance comparison across algorithms) as well as a more complex real-world activity dataset, Charades. Our Stacked-STGCN in general achieves 4.1% performance improvement over the best reported results in F1 score on CAD120 and 1.3% in mAP on Charades using VGG features.
翻译:我们提出新的Spactio-Spacio-Termologal Convolution Networks (Stacked-STGCN),用于行动分割,即预测和在长视频中将一系列行动进行本地化。我们推广最初为基于骨架的行动识别而提议的Spatio-Topio-Termologal Convolution Network(STGCN), 以便让具有不同特点(如场景、行为体、目标、动作等)、 长度各异的特征描述器和任意的时际边缘连接能够考虑到与复杂活动通常相关的大图解变。我们进一步向STGCN 引入堆叠式沙眼结构, 以利用编码-Descoder-decoder设计的优势来提高一般化性能和本地化准确性能。我们探索各种描述符,如框架级的甚低频级的MGGGGG、部分I3D、RCNN(RCN) 对象等,作为根据对综合背景信息的共同推断进行行动分解,使行动分解。我们CAD120(提供预先设定的NPC节点特征特征特征和边缘特性特征和边重度),在CADRADRADDM 的成绩上,并进行最佳业绩分析中,并进行最佳业绩分析。