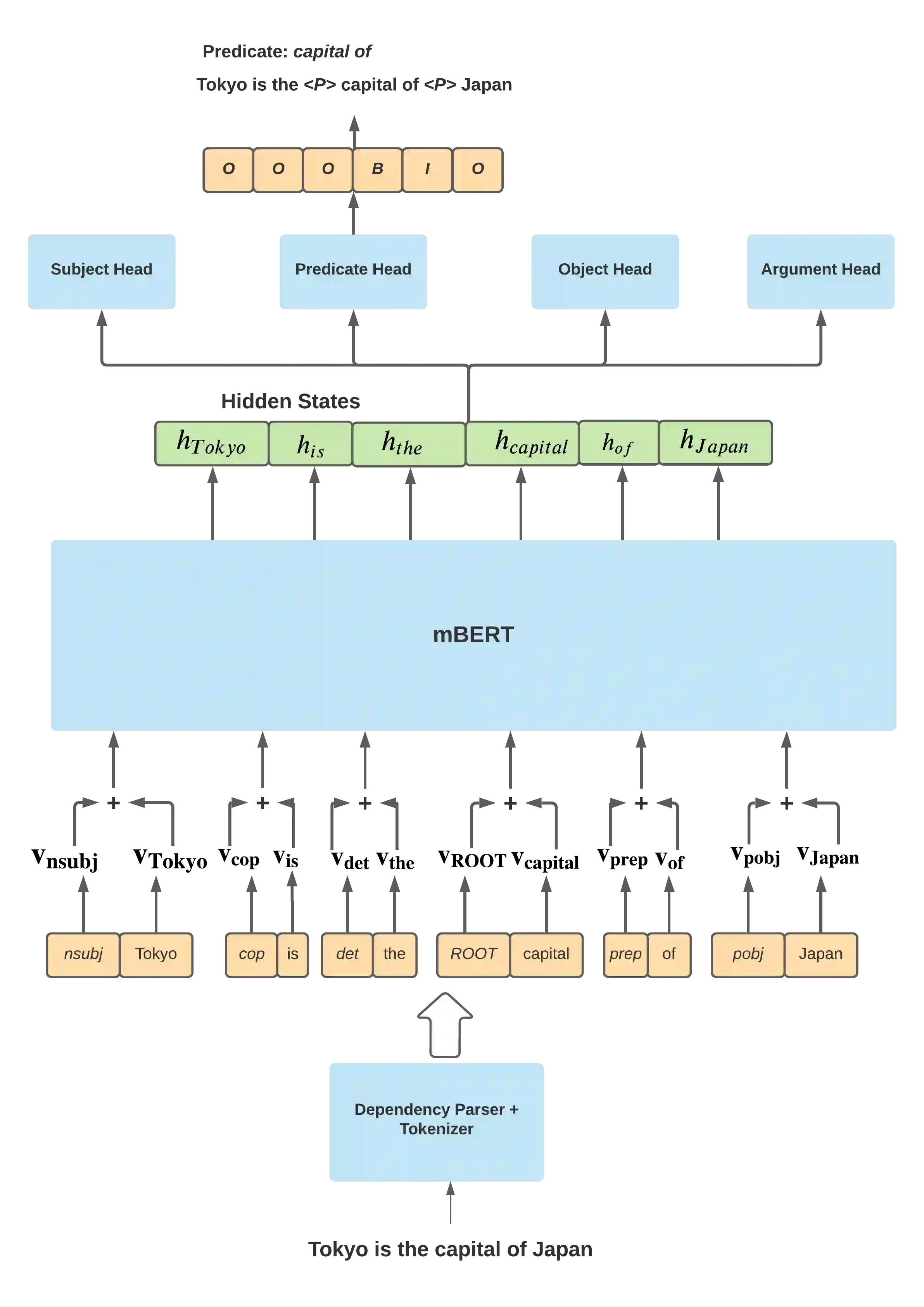
In this paper we investigate a simple hypothesis for the Open Information Extraction (OpenIE) task, that it may be easier to extract some elements of an triple if the extraction is conditioned on prior extractions which may be easier to extract. We successfully exploit this and propose a neural multilingual OpenIE system that iteratively extracts triples by conditioning extractions on different elements of the triple leading to a rich set of extractions. The iterative nature of MiLIE also allows for seamlessly integrating rule based extraction systems with a neural end-to-end system leading to improved performance. MiLIE outperforms SOTA systems on multiple languages ranging from Chinese to Galician thanks to it's ability of combining multiple extraction pathways. Our analysis confirms that it is indeed true that certain elements of an extraction are easier to extract than others. Finally, we introduce OpenIE evaluation datasets for two low resource languages namely Japanese and Galician.
翻译:在本文中,我们调查了开放信息提取(OpenIE)任务的一个简单假设,即如果以先前的提取为条件,而这种提取可能比较容易提取,那么可以更容易地提取一些三重元素。我们成功地利用了这一假设,并提议了一个神经多语言的 OpenIE 系统,通过对导致大量提取的三重元素进行调试,反复提取三重元素。MiLIE的迭接性质还允许将基于规则的提取系统与神经端对端系统进行无缝的整合,从而导致性能的改善。MILIE在从中文到加利西亚语的多种语言上优于SOTA系统,这要归功于它结合多种提取路径的能力。我们的分析证实,某些提取要素确实比其他方法更容易提取。最后,我们为两种低资源语言(日语和加利西亚语)引入了OpenIE评价数据集。