
题目: Web Data Extraction with Seed Samples
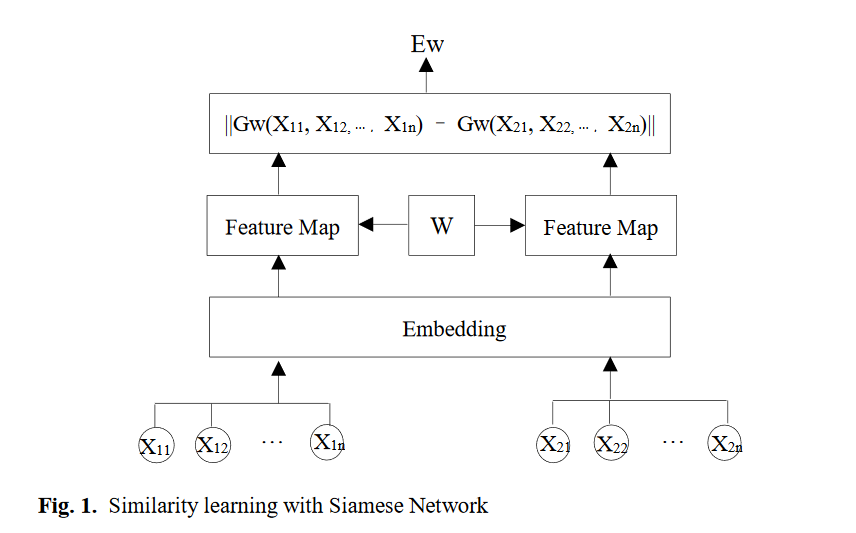
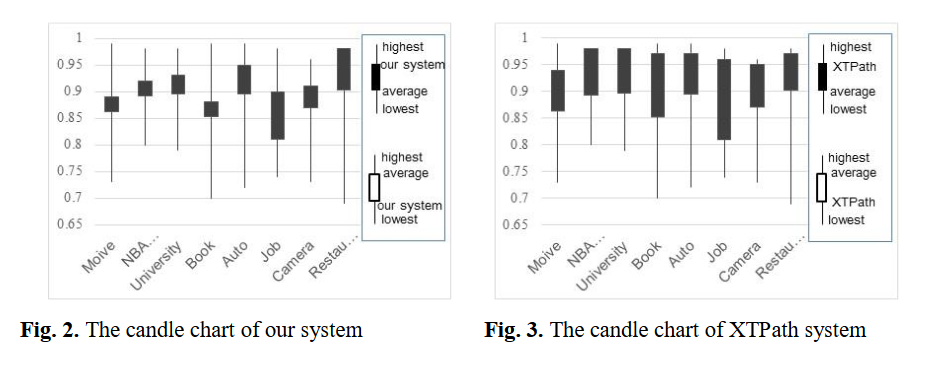
摘要: web包含了大量的半结构化数据,已经成为知识库填充的丰富资源。从庞大的网站中提取结构化数据已经吸引了大量的努力。本文提出了一种从种子样本中提取web数据的新方法。该方法利用具有种子样本的连体网络学习相似度度量。该方法从种子样本中建立提取模式,并通过相似性度量寻找越来越多的样本进行连续优化,在大规模网页上的实验表明了该方法的有效性和有效性。
作者简介: Jun Ma,分别在中国山东大学、日本茨城大学和日本九州大学获得学士、硕士和博士学位。现任山东大学计算机与科学技术学院副院长、计算机建筑研究所所长、中国计算机联合会会员、IEEE会员。他是《中国计算机杂志》、《软件杂志》和一些国际会议的编辑。国家高新技术研究开发计划(863)和国家自然科学基金评审员。拥有教育部、山东省劳动和科学委员会颁发的各类奖项/荣誉,主要包括国家教育部大学骨干教师基金(2001年)和山东大学的领导学者和有前途的骨干教师。个人主页:http://ir.sdu.edu.cn/~junma/~junma_en.htm
Jie Liu,中国天津南开大学获得计算机科学博士学位。南开大学计算机与控制工程学院教授。他的研究兴趣包括机器学习、模式识别、信息检索和数据挖掘。他在参考文献和期刊上发表过多篇论文,如KDD、AAAI、IJCAI、CIKM、ICDM、TKDE、TIST、KAIS、模式识别、信息科学、Springer WWW等。个人主页:http://jieliu.me/
成为VIP会员查看完整内容


相关内容

专知会员服务
85+阅读 · 2019年11月24日
Arxiv
4+阅读 · 2018年9月6日
Arxiv
5+阅读 · 2018年4月13日




相关VIP内容
专知会员服务
85+阅读 · 2019年11月24日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年9月6日
Arxiv
5+阅读 · 2018年4月13日