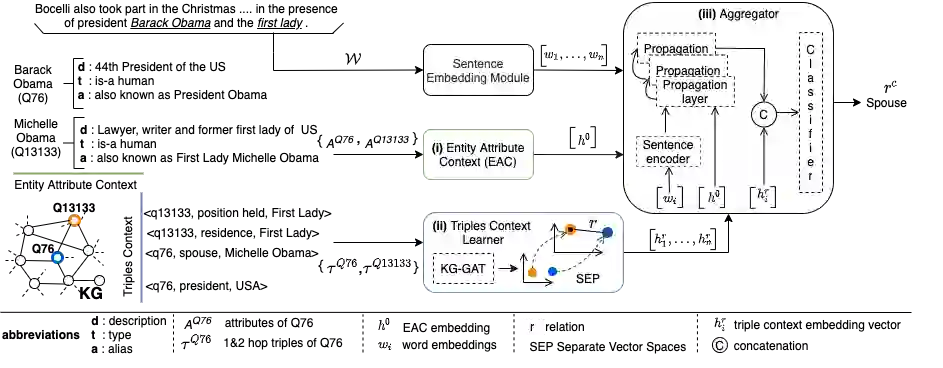
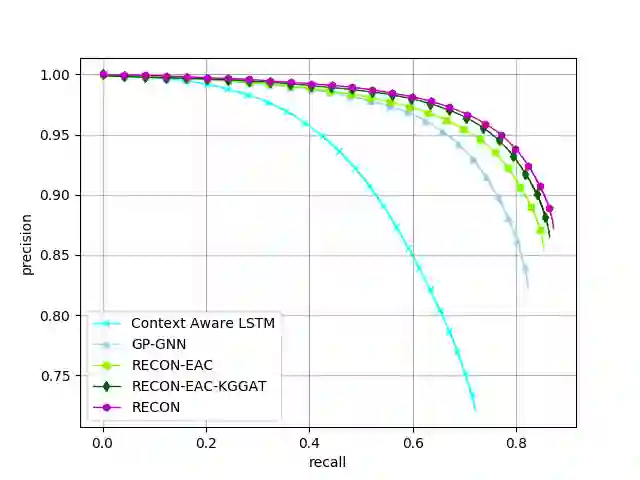
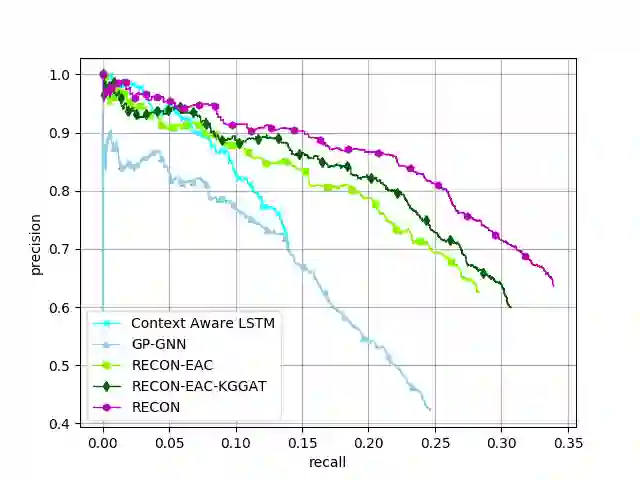
In this paper, we present a novel method named RECON, that automatically identifies relations in a sentence (sentential relation extraction) and aligns to a knowledge graph (KG). RECON uses a graph neural network to learn representations of both the sentence as well as facts stored in a KG, improving the overall extraction quality. These facts, including entity attributes (label, alias, description, instance-of) and factual triples, have not been collectively used in the state of the art methods. We evaluate the effect of various forms of representing the KG context on the performance of RECON. The empirical evaluation on two standard relation extraction datasets shows that RECON significantly outperforms all state of the art methods on NYT Freebase and Wikidata datasets. RECON reports 87.23 F1 score (Vs 82.29 baseline) on Wikidata dataset whereas on NYT Freebase, reported values are 87.5(P@10) and 74.1(P@30) compared to the previous baseline scores of 81.3(P@10) and 63.1(P@30).
翻译:在本文中,我们提出了一个名为RECON的新颖方法,该方法自动识别句子(名义关系提取)中的关系,并与知识图表(KG)相一致。RECON使用一个图形神经网络来学习对KG中储存的句子和事实的表述,从而提高了总体提取质量。这些事实,包括实体属性(标签、别名、描述、实例)和事实三重,没有在最新方法中共同使用。我们评估了代表KG背景的各种形式对RECON绩效的影响。对两个标准关系提取数据集的经验评估表明,RECON明显地超越了NYT Freebase和Wikigata数据集的所有先进方法。RECON报告Wikicadata数据集87.23 F1评分(Vs 82.29基线),而在NYT Freebase,所报告的数值为87.5分(P@10)和74.1分(P@30),而以前的基线评分分别为81.3分(P@10)和63.1分(P@30)。