论文浅尝 | Learning with Noise: Supervised Relation Extraction

Luo B, Feng Y, Wang Z, et al. Learning withNoise: Enhance Distantly Supervised Relation Extraction with Dynamic TransitionMatrix[C]// Meeting of the Association for Computational Linguistics.2017:430-439.
链接:http://www.aclweb.org/anthology/P/P17/P17-1040.pdf
1. 动机
Distant supervision 是一种生成关系抽取训练集的常用方法。它把现有知识库中的三元组 <e1,r, e2> 作为种子,匹配同时含有 e1 和 e2 的文本,得到的文本用作关系 r 的标注数据。这样可以省去大量人工标记的工作。
但是这种匹配方式会产生很多噪音:比如三元组 <DonaldTrump, born-in, New York>,可能对齐到『Donald Trump was born in New York』,也可能对齐到『DonaldTrump worked in New York』。其中前一句是我们想要的标注数据,后一句则是噪音数据(并不表示born-in)。如何去除这些噪音数据,是一个重要的研究课题。
2. 前人工作
1、通过定义规则过滤掉一些噪音数据,缺点是依赖人工定义,并且被关系种类所限制。
2、Multi-instancelearning,把训练语句分包学习,包内取平均值,或者用 attention 加权,可以中和掉包内的噪音数据。缺点是受限于 at-least-one-assumption:每个包内至少有一个正确的数据。
可以看出前人主要思路是『去噪』,即降低噪声数据的印象。这篇文章提出用一个噪音矩阵来拟合噪音的分布,即给噪音建模,从而达到拟合真实分布的目的。
3. 模型
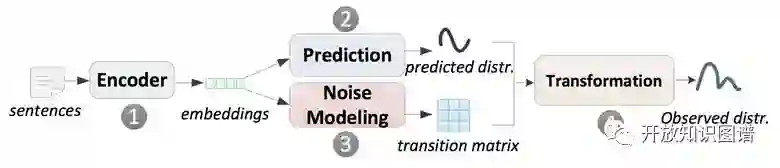
1、2是普通的关系抽取模型过程,3、4是噪音拟合的过程。
transition matrix 是一个转移矩阵,大小为n * n,n是关系种类的数目。T_ij 的元素的值是 p( j| i ),即该句子代表关系为 i,但被误判为j的概率。
这样我们就可以得到:
𝑃𝑟𝑒𝑑𝑖𝑐𝑡𝑒𝑑 𝑑𝑖𝑠𝑡𝑟𝑖𝑏𝑢𝑡𝑖𝑜𝑛 × 𝑇𝑟𝑎𝑠𝑖𝑡𝑖𝑜𝑛 𝑚𝑎𝑡𝑟𝑖𝑥=𝑂𝑏𝑠𝑒𝑟𝑣𝑒𝑑 𝑑𝑖𝑠𝑡𝑟𝑖𝑏𝑢𝑡𝑖𝑜𝑛
其中,predicted 是我们想要的真实分布,observed 是我们观测到的噪音分布,这样就可以用噪音数据进行联合训练了。
3.1 全局转移矩阵& 动态转移矩阵
Global transition matrix 在关系层面上定义一个特定的转移矩阵,比如
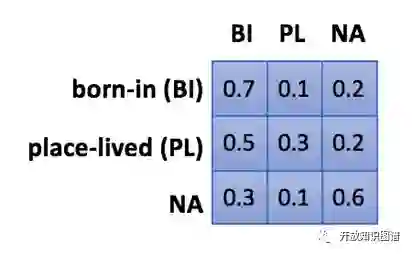
属于 A 关系的句子,被误判为 B 关系的概率是恒定的。
Dynamic transition matrix 是在句子层面上定义的,即使同属于 A 关系,a1 句子和 b1 句子被误判成 B 关系的概率也不同。比如下面两句话,带有 old house 的被误判成 born-in 的概率更大。

动态转移矩阵更有优势,粒度更细。
3.2. 训练方法
如果单纯用 observed 的 loss,会出现问题,因为在初始化的时候,我们并不能保证p一定拟合真实分布,转移矩阵也没有任何先验信息,容易收敛到局部最优。
因此,文中用 curriculum learning进行训练:
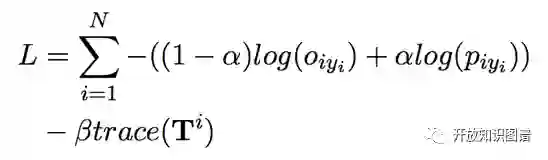
trace 是转移矩阵的迹,用于控制训练过程中噪音的作用,是矩阵的正则项。在没有噪音的情况下,矩阵是一个单位矩阵,迹最大,此时矩阵没有效果。迹越小,矩阵施加的效果越明显。
curriculum learning 的步骤:
初始阶段,alpha 为 1,beta 取一个很大的值,只学习 p 分布,让 p 获得关系判定的能力;
后续阶段,逐渐减小 alpha 和 beta,强化矩阵的作用,学习噪音分布 o,最后获得真实的 p 分布和噪音 o 分布。
这样通过调控过程,就可以避免学习出无意义的局部最优值了。
3.3.先验知识
可以给矩阵增加一些先验知识,比如在 timeRE 的数据集上,根据时间粒度,对数据集进行可信度划分,先训练可信数据,再训练噪音数据,这样可以优化最终的训练结果。
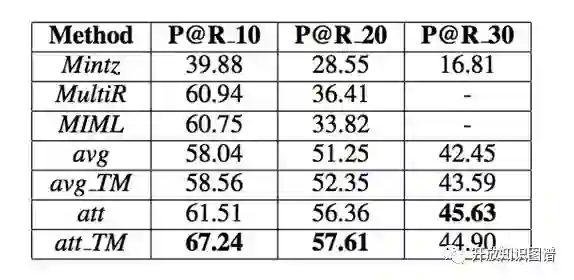
4. 实验结果
作者在 timeRE 和 entityRE(NYT) 上均进行了训练,取得了降噪的 state-of-art。具体分析结果可以参照论文。
笔记整理:王冠颖,浙江大学硕士,研究方向为知识图谱,关系抽取。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。



