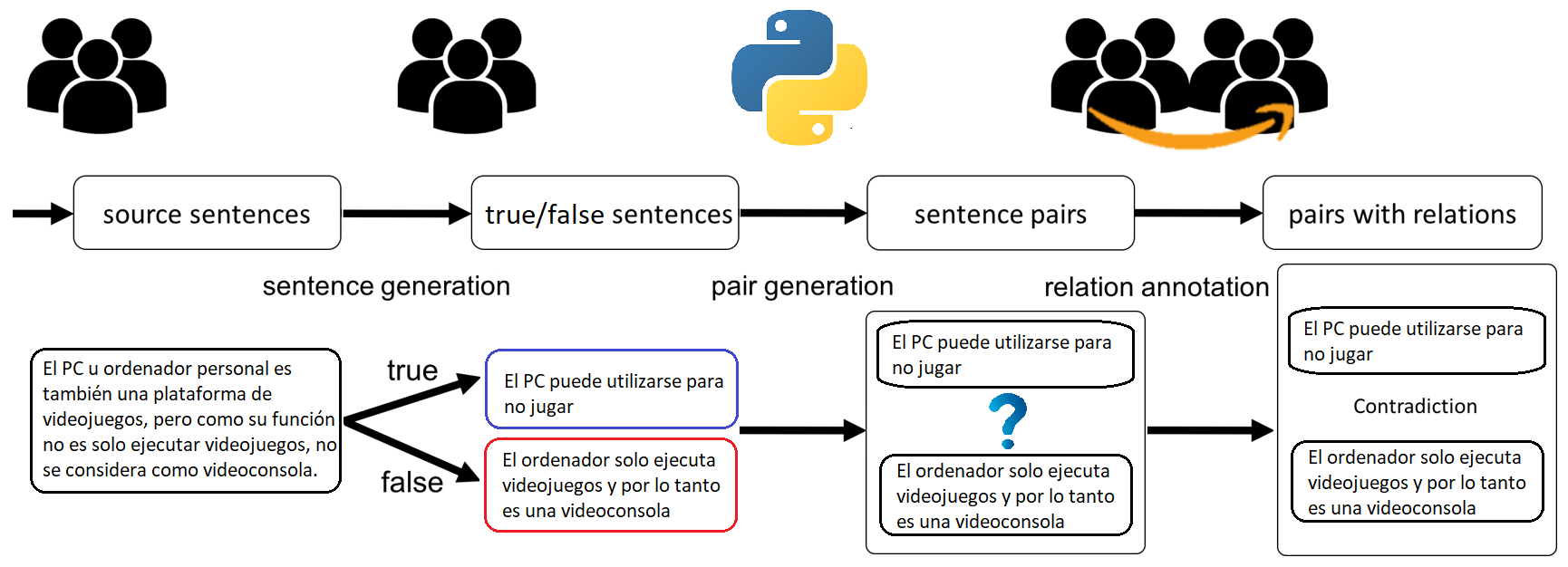
In this paper, we present InferES - an original corpus for Natural Language Inference (NLI) in European Spanish. We propose, implement, and analyze a variety of corpus-creating strategies utilizing expert linguists and crowd workers. The objectives behind InferES are to provide high-quality data, and, at the same time to facilitate the systematic evaluation of automated systems. Specifically, we focus on measuring and improving the performance of machine learning systems on negation-based adversarial examples and their ability to generalize across out-of-distribution topics. We train two transformer models on InferES (8,055 gold examples) in a variety of scenarios. Our best model obtains 72.8% accuracy, leaving a lot of room for improvement. The "hypothesis-only" baseline performs only 2%-5% higher than majority, indicating much fewer annotation artifacts than prior work. We find that models trained on InferES generalize very well across topics (both in- and out-of-distribution) and perform moderately well on negation-based adversarial examples.
翻译:在本文中,我们介绍欧洲西班牙语语言自然语言推断(NLI)的原始内容InferES。我们建议、实施和分析各种创造自然语言推断(NLI)的战略,利用专业语言学家和人群工人。InferES背后的目标是提供高质量的数据,同时便利对自动化系统进行系统的评估。具体地说,我们侧重于衡量和改进机器学习系统的绩效,以否定为根据的对抗性实例及其在分布范围以外各专题中加以普及的能力。我们培训了两种变压器模型,在各种假设中应用InferES(8 055金例),我们的最佳模型获得了72.8%的精度,留下了许多改进的余地。“只使用假肢”的基线比多数标准高出2%至5%,说明的人工制品比以前的工作少得多。我们发现,关于InferES的模型对不同专题(在分配和分配范围外)进行了广泛的普及,对否定性对准例子进行了中度井。