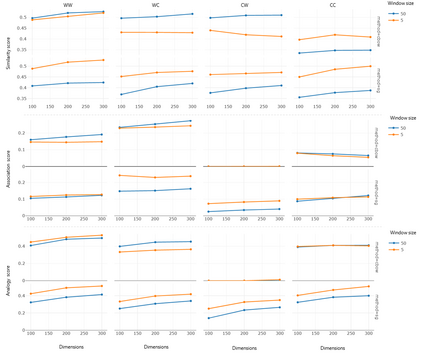
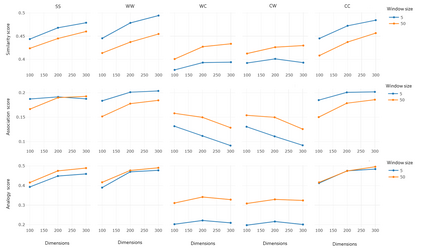
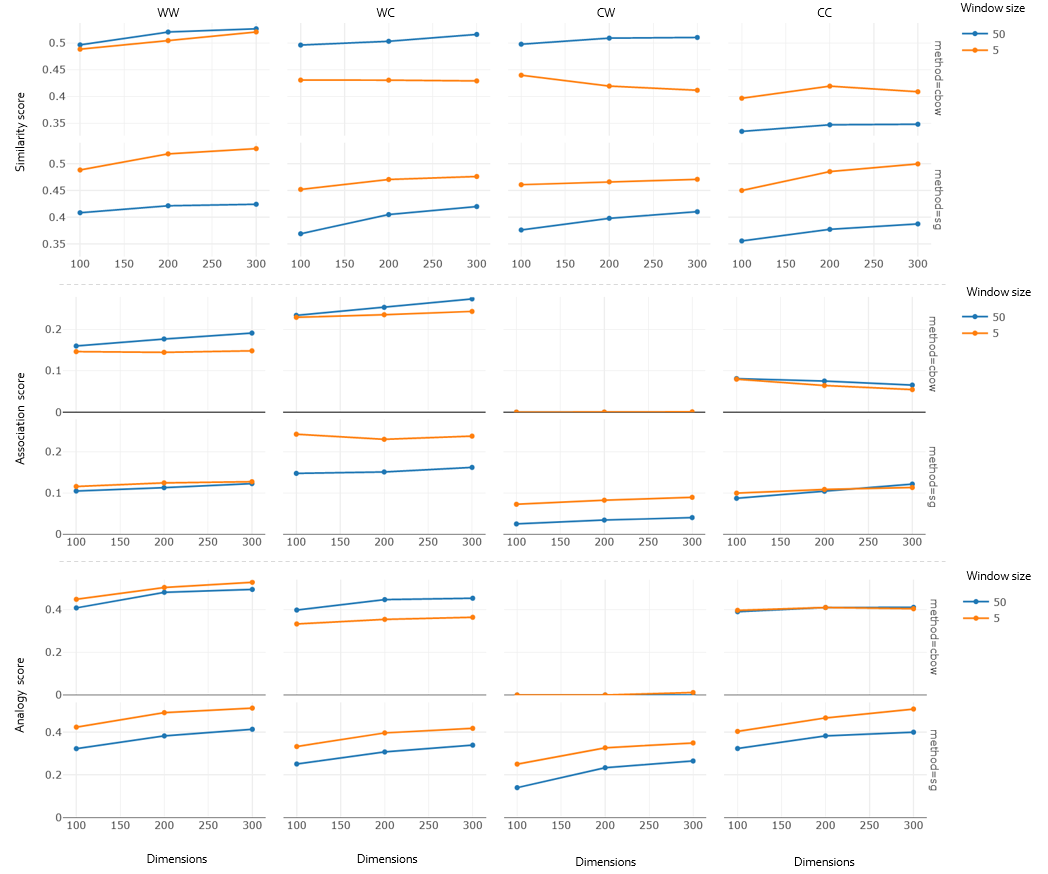
Recent word embeddings techniques represent words in a continuous vector space, moving away from the atomic and sparse representations of the past. Each such technique can further create multiple varieties of embeddings based on different settings of hyper-parameters like embedding dimension size, context window size and training method. One additional variety appears when we especially consider the Dual embedding space techniques which generate not one but two-word embeddings as output. This gives rise to an interesting question - "is there one or a combination of the two word embeddings variety, which works better for a specific task?". This paper tries to answer this question by considering all of these variations. Herein, we compare two classical embedding methods belonging to two different methodologies - Word2Vec from window-based and Glove from count-based. For an extensive evaluation after considering all variations, a total of 84 different models were compared against semantic, association and analogy evaluations tasks which are made up of 9 open-source linguistics datasets. The final Word2vec reports showcase the preference of non-default model for 2 out of 3 tasks. In case of Glove, non-default models outperform in all 3 evaluation tasks.
翻译:最近的嵌入字技术代表着连续矢量空间中的单词, 远离原子和稀疏的过去表达方式。 每一种这样的技术都可以进一步根据超参数的不同设置, 创建多种嵌入式。 例如嵌入维度大小、 上下文窗口大小和培训方法。 当我们特别考虑“ 双嵌入空间技术” 时, 产生一个而不是两个字嵌入输出。 这就产生了一个有趣的问题 : “ 是存在一个还是结合两个词嵌入式, 这对于特定任务效果更好? ” 。 本文试图通过考虑所有这些变异来回答这个问题。 这里, 我们比较了两种属于两种不同方法的经典嵌入式方法 - Word2Vec 和 Glove 。 在考虑所有变异之后进行的广泛评估中, 总共84种不同的模型与由9个开放源语言数据集组成的语系、 关联和类比评价任务。 Word2vec 最终的报告展示了所有3项任务中的非默认模型的偏好。