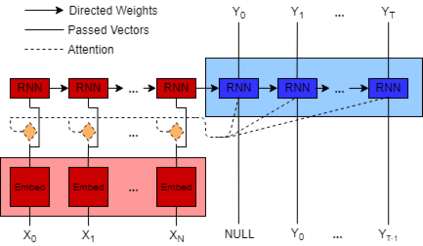
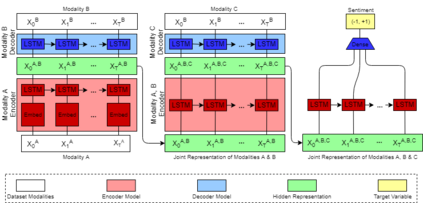
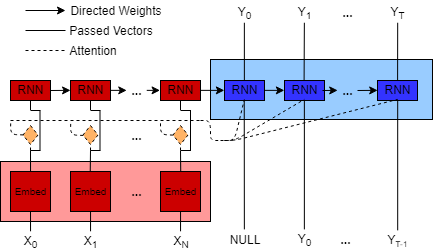
Multimodal machine learning is a core research area spanning the language, visual and acoustic modalities. The central challenge in multimodal learning involves learning representations that can process and relate information from multiple modalities. In this paper, we propose two methods for unsupervised learning of joint multimodal representations using sequence to sequence (Seq2Seq) methods: a \textit{Seq2Seq Modality Translation Model} and a \textit{Hierarchical Seq2Seq Modality Translation Model}. We also explore multiple different variations on the multimodal inputs and outputs of these seq2seq models. Our experiments on multimodal sentiment analysis using the CMU-MOSI dataset indicate that our methods learn informative multimodal representations that outperform the baselines and achieve improved performance on multimodal sentiment analysis, specifically in the Bimodal case where our model is able to improve F1 Score by twelve points. We also discuss future directions for multimodal Seq2Seq methods.
翻译:多式机器学习是一个核心研究领域,涉及语言、视觉和声学模式。多式学习的核心挑战涉及学习表现,能够处理和联系多种模式的信息。在本文件中,我们提出两种方法,即采用顺序顺序(Seq2Seq2Seq)方法,在不受监督的情况下学习联合多式表现:一种\textit{Seq2Seq2Seqmodality Transformation Production}和一种\textit{Seq2Seq2Seqmodility Transferation model}。我们还探讨这些后继模式的多式联运投入和产出的多种差异。我们利用CMU-MOSI数据集进行的多式情绪分析实验表明,我们的方法学习了信息丰富的多式联运表现,这些表现超越了基线,并在多式情绪分析上取得了更好的业绩,特别是在双式案例中,我们的模式能够将F1分数提高12分。我们还讨论了多式Seq2Seqeq方法的未来方向。