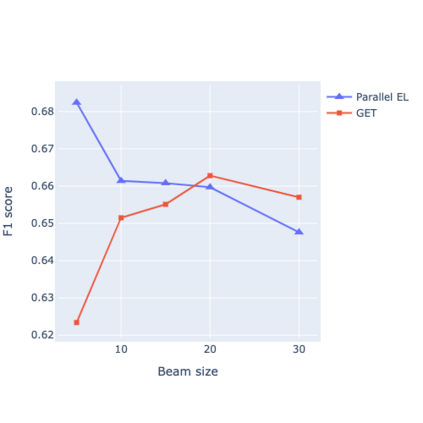
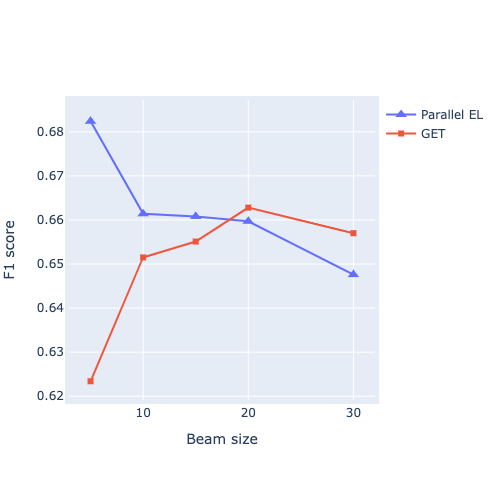
Detection and disambiguation of all entities in text is a crucial task for a wide range of applications. The typical formulation of the problem involves two stages: detect mention boundaries and link all mentions to a knowledge base. For a long time, mention detection has been considered as a necessary step for extracting all entities in a piece of text, even if the information about mention spans is ignored by some downstream applications that merely focus on the set of extracted entities. In this paper we show that, in such cases, detection of mention boundaries does not bring any considerable performance gain in extracting entities, and therefore can be skipped. To conduct our analysis, we propose an "Entity Tagging" formulation of the problem, where models are evaluated purely on the set of extracted entities without considering mentions. We compare a state-of-the-art mention-aware entity linking solution against GET, a mention-agnostic sequence-to-sequence model that simply outputs a list of disambiguated entities given an input context. We find that these models achieve comparable performance when trained both on a fully and partially annotated dataset across multiple benchmarks, demonstrating that GET can extract disambiguated entities with strong performance without explicit mention boundaries supervision.
翻译:文本中所有实体的探测和模糊是一系列广泛应用的关键任务。 问题的典型提法涉及两个阶段: 探测提及边界, 将所有实体都与知识库联系起来。 长期以来, 将提及探测视为在文本中提取所有实体的必要步骤, 即使提及范围的信息被一些仅仅侧重于一组抽取实体的下游应用所忽视。 本文显示, 在这类情况下, 发现提及边界不会在提取实体中带来任何相当大的绩效收益, 因此可以跳过。 为了进行分析, 我们建议对问题进行“ 强度拖曳” 的提法, 即对模型只对一组抽取实体进行评价, 而没有考虑提及。 我们比较了将解决方案与Get挂钩的、 提及- 不可忽视的顺序到顺序的状态实体模型, 仅输出一个带有投入背景的、 模糊实体清单。 我们发现, 在经过全面、 部分附加说明的多个基准数据的培训后,这些模型都取得了相似的业绩。 我们发现, Get Get in disguidate exprecrestrate destrate destrate destrateblement amber