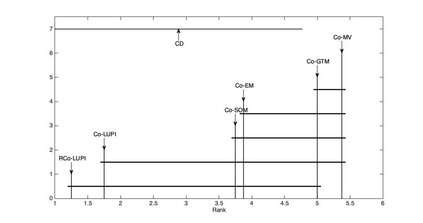
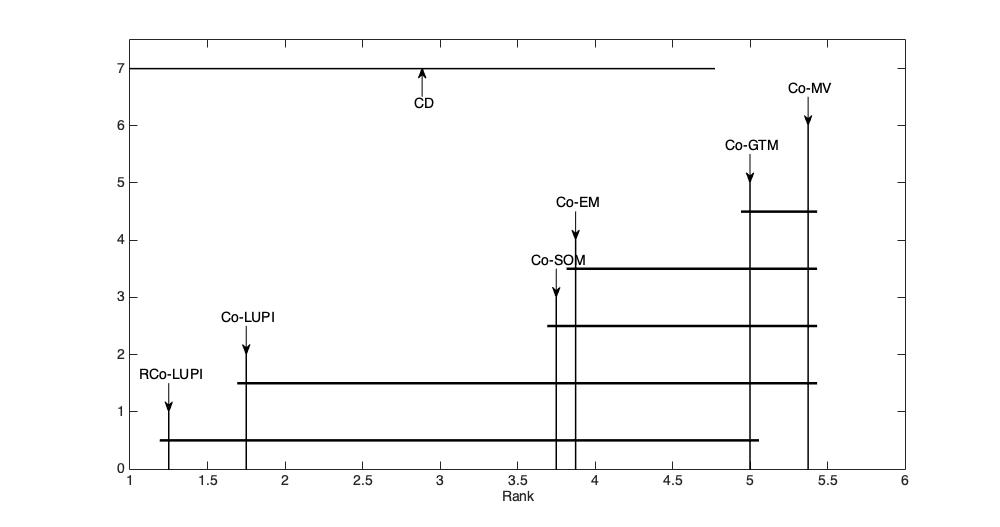
In the collaborative clustering framework, the hope is that by combining several clustering solutions, each one with its own bias and imperfections, one will get a better overall solution. The goal is that each local computation, quite possibly applied to distinct data sets, benefits from the work done by the other collaborators. This article is dedicated to collaborative clustering based on the Learning Using Privileged Information paradigm. Local algorithms weight incoming information at the level of each observation, depending on the confidence level of the classification of that observation. A comparison between our algorithm and state of the art implementations shows improvement of the collaboration process using the proposed approach.
翻译:在合作分组框架内,希望通过将若干组合解决方案(每个解决方案都有自己的偏差和不完善)结合起来,就能找到更好的整体解决方案,目标是每个本地计算(很可能适用于不同的数据集)都能从其他合作者的工作中受益,这一条专门用于基于 " 学习使用特权信息 " 范式的协作组合,根据观察分类的可信度,对每个观测层次上收到的信息进行本地算法加权。比较我们的算法和最新技术实施状况表明使用拟议方法改进了合作进程。