
主题: Locally Differentially Private (Contextual) Bandits Learning
摘要:
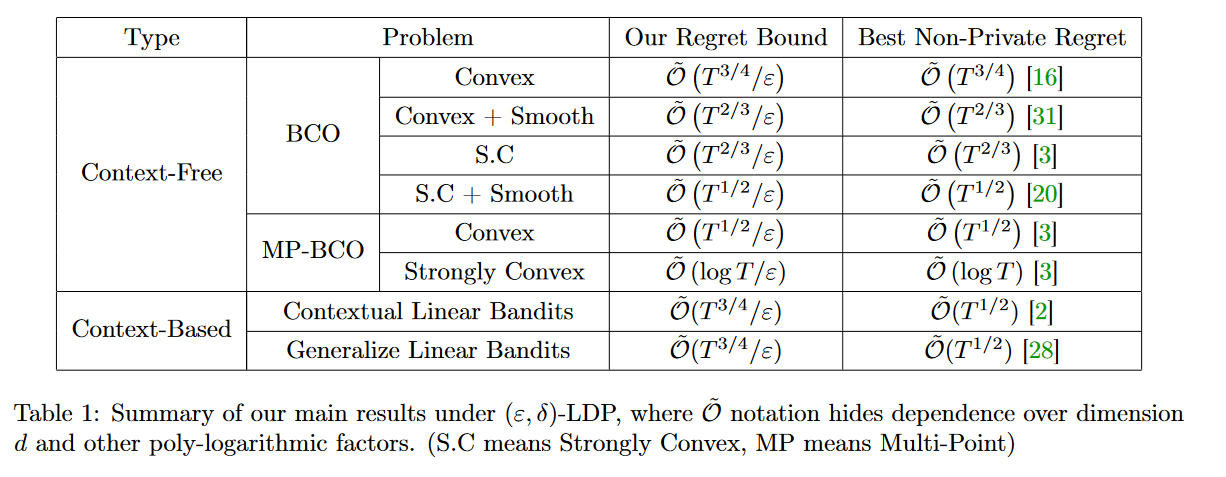
首先,我们提出了一种简单的黑盒归约框架,该框架可以解决带有LDP保证的大量无背景的bandits学习问题。根据我们的框架,我们可以通过单点反馈(例如 private bandits凸优化等)改善private bandits学习的最佳结果,并在LDP下获得具有多点反馈的BCO的第一结果。 LDP保证和黑盒特性使我们的框架在实际应用中比以前专门设计的和相对较弱的差分专用(DP)上下文无关强盗算法更具吸引力。此外,我们还将算法扩展到在(ε,δ)-LDP下具有遗憾约束ō(T~3/4 /ε)的广义线性bandits,这被认为是最优的。注意,给定DP上下文线性bandits的现有Ω(T)下界,我们的结果表明LDP和DP上下文bandits之间的根本区别。
成为VIP会员查看完整内容
相关内容

专知会员服务
54+阅读 · 2020年3月5日
专知会员服务
36+阅读 · 2019年11月15日
Arxiv
5+阅读 · 2020年4月2日
Arxiv
20+阅读 · 2020年3月10日
Arxiv
5+阅读 · 2018年9月17日
相关主题
相关VIP内容
专知会员服务
54+阅读 · 2020年3月5日
专知会员服务
36+阅读 · 2019年11月15日
相关资讯
相关论文
Arxiv
5+阅读 · 2020年4月2日
Arxiv
20+阅读 · 2020年3月10日
Arxiv
5+阅读 · 2018年9月17日