
题目: Automatically Discovering and Learning New Visual Categories with Ranking Statistics
摘要:
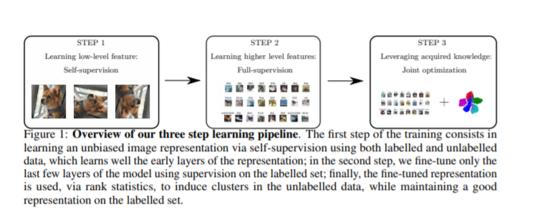
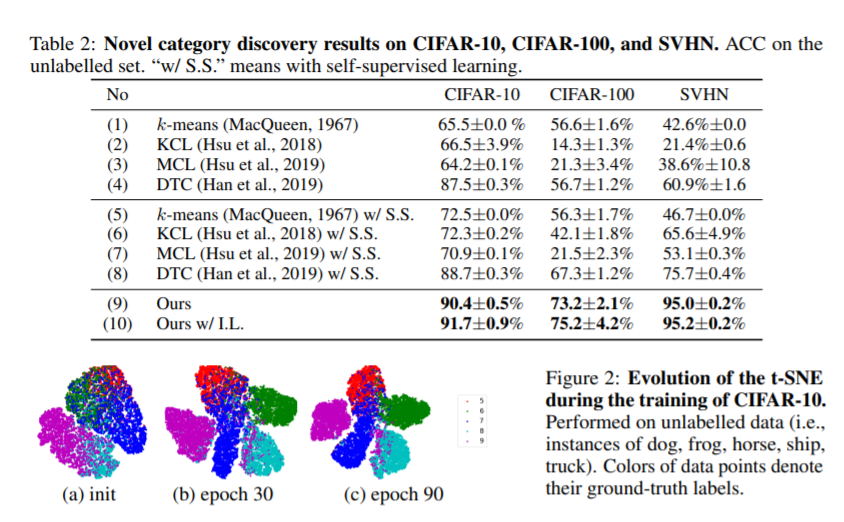
我们解决了在一个图像集合中发现新的类的问题,给出了其它类的标记示例。这种设置类似于半监督学习,但难度要大得多,因为新课程没有带标签的例子。因此,挑战在于如何利用标记图像中包含的信息来学习通用的聚类模型,并使用后者来识别未标记数据中的新类。在这项工作中,我们通过结合三个想法来解决这个问题:
- 使用标记数据引导图像表示的方法只会引入不必要的偏差,通过使用自监督学习对标记数据和未标记数据的并集从零开始训练表示,可以避免这种偏差;
- 利用秩统计将模型的标记类知识转化为未标记图像的聚类问题;
- 通过优化数据的标记子集和未标记子集的联合目标函数来训练数据表示,改进了标记数据的监督分类和未标记数据的聚类。我们在标准分类基准上评估我们的方法,并在新类别发现方面显著优于现有方法。
成为VIP会员查看完整内容
相关内容
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
14+阅读 · 2019年11月11日
Arxiv
4+阅读 · 2019年8月27日



相关VIP内容
专知会员服务
36+阅读 · 2020年3月12日
专知会员服务
14+阅读 · 2019年11月11日
相关资讯
相关论文
Arxiv
4+阅读 · 2019年8月27日