CVPR2020 | 北航提出通过由粗到精特征自适应进行跨域目标检测
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转载自:AI深度视线
作者团队:北京航空航天大学
引言

近年来,在基于深度学习的目标检测中见证了巨大的进步。但是,由于domain shift问题,将现成的检测器应用于未知的域会导致性能显著下降。为了解决这个问题,本文提出了一种新颖的从粗到精的特征自适应方法来进行跨域目标检测。
在粗粒度阶段,与文献中使用的粗糙图像级或实例级特征对齐不同,采用注意力机制提取前景区域,并通过多层对抗学习根据边缘分布对边缘区域进行对齐。
主要思路及贡献
针对的问题:
目前的CNN模型在直接应用于新场景时,由于存在所谓的"域移位"或"数据集偏置"现象,导致性能下降。
主要思路
本文作者提出了一个由粗到精的跨域目标检测的特征自适应框架。如下图所示:
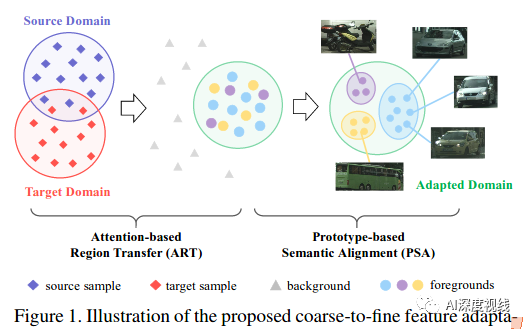
问题一:考虑到与背景相比,不同域之间的前景具有很多的共同特征。
作者提出了一个基于注意力的区域转移(ART)模块来突出前景的重要性,它以一种不区分类的粗糙方式工作。利用高级特征中的注意机制提取感兴趣的前景目标,并在特征分布对齐时对其进行标记。通过多层对抗性学习,利用复杂的检测模型可以实现有效的领域交叉。
问题二:对象的类别信息会进一步细化前面的自适应特征,在这种情况下,需要区分不同种类的前景目标。不过这在某些batch中可能会出现目标不匹配的情况,这使得UDA的语义匹配比较困难。
作者使用了一个基于原型的语义对齐(PSA)模块来构建跨域的每个类别的全局原型。原型在每次迭代中都进行自适应更新,从而抑制了假伪标签和类不匹配的负面影响。
主要贡献:
网络架构
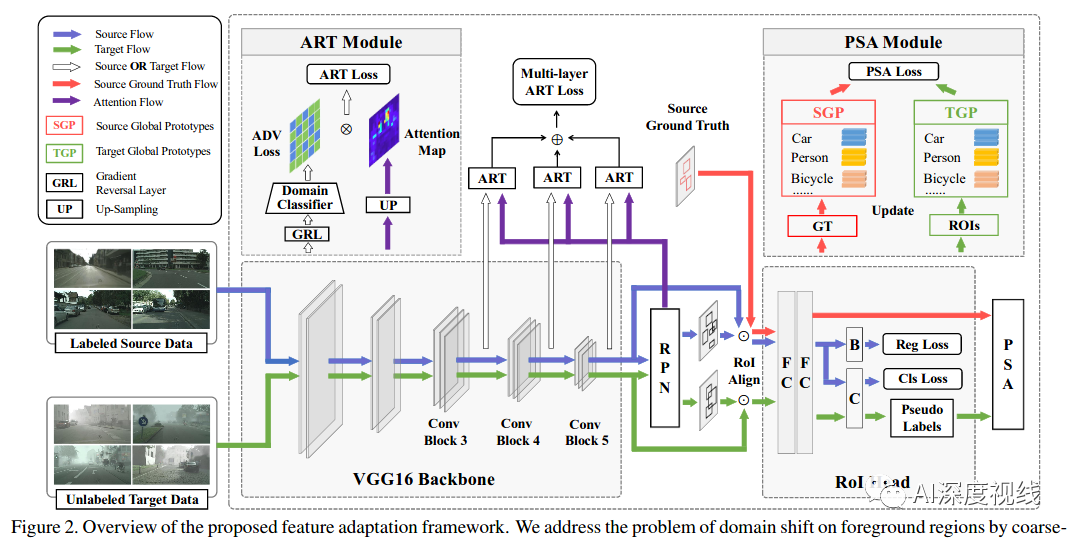
如上图所示,介绍了本文用于跨域对象检测的功能适配框架,包含一个检测网络和两个适配模块。
3.1 检测网络 backbone
作者选了功能强大的Faster R-CNN 作为基础检测器backbone。Faster R-CNN 是一个两阶段的检测器,由三个主要组件组成:1)提取图像特征的骨干网络G,2)同时预测对象范围和对象得分的区域提议网络(RPN),以及3)兴趣(RoI)头,包括边界框回归器B和分类器C以进行进一步细化.Faster R-CNN的整体损失函数定义为:
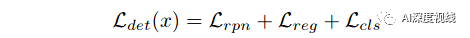
3.2 适配模块 Adaptation Modules
与大多数现有研究(通常会减少整个特征空间中的域偏移)不同,作者采用的方法是在各个域之间共享更多共同属性的前景上进行特征对齐。同时,与当前将所有目标的样本视为一个整体的方法相反,作者认为类别信息有助于完成此任务,从而突出显示每个类别的分布以进一步细化特征对齐。
为此,设计了两个自适应模块,即 基于注意力的区域转移(ART) 和 基于原型的语义对齐(PSA) ,以实现前景中从粗到精的知识转移。
3.2.1 ART:Attention-based Region Transfer
ART模块旨在引起更多关注,以在前景区域内对齐两个域之间的分布。它由两部分组成:域分类器和注意机制。
Domain 分类器
为了对齐跨域的特征分布,作者将多个域分类器D集成到主干网络G的最后三个卷积块中,在这里构建了一个二人极大极小博弈。具体来说,域分类器D试图区分特征来自哪个域,而主干网络G旨在混淆分类器。在实践中,G和D之间通过梯度反向层(Gradient Reverse Layer, GRL)进行连接,梯度反向层可以逆转流过G的梯度。当训练过程收敛时,G倾向于提取域不变的特征表示。在形式上,第l-th卷积块中对抗性学习的目标可以表示为:
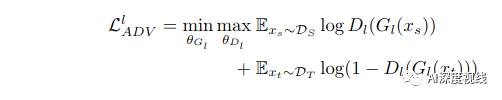
Attension 机制
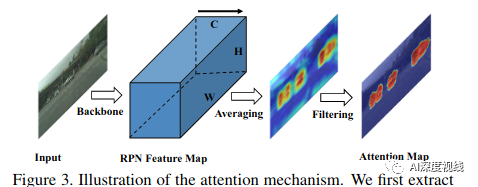
具体来说:
给定任意域中的图像x,将Frpn(x)∈RH×W×C作为FPN模块中卷积层的输出特征图,其中H×W和C分别为特征图的空间维数和通道数。
通过对激活值进行跨通道的平均来构建一个空间注意图。
过滤(设置为零)那些小于给定阈值的值,这些值更有可能属于背景区域。
由于注意图的大小与不同卷积块的特征不一致,采用双线性插值进行上采样,从而得到相应的注意图。
由于注意力地图可能并不总是那么准确,如果一个前地区域被误认为背景,它的注意力权重被设置为零,则无法起到效果。因此,这里在注意图中添加了一个跳跃连接以增强其性能。
注意图A(x)∈RH×W可以表示为:
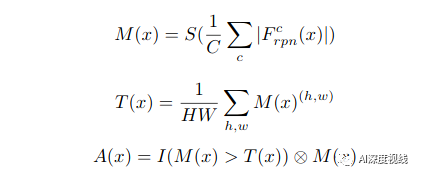
最终的ART模块的目标函数可以表示为:
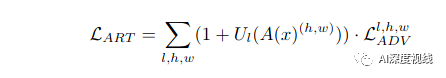
3.2.2 PSA:Prototype-based Semantic Alignment
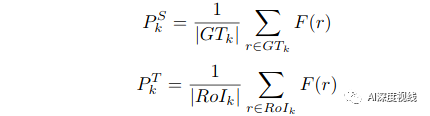
(1) 原型没有额外的可训练参数,可以在线性时间内计算出来;
(2) 伪标签的负面影响可以被原型生成时数量大得多的正确伪标签所抑制。
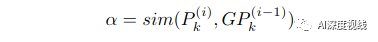
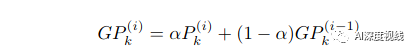
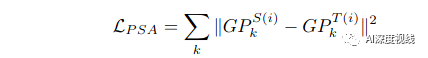
3.3 网络优化 Network Optimization
训练的伪代码如下图所示:

主要包括三个parts:
监督学习。监督检测损耗Ldet只适用于带标记的源域DS。
粗粒度的适应。利用注意机制来提取图像中的前景。然后,重点通过优化LART调整这些区域的特征分布。
细粒度的适应。首先,在目标域中预测伪标签。然后,进一步自适应地更新每个类别的全局原型。最后,通过优化LPSA实现了前台对象的语义对齐。
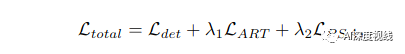
实验及结果
4.1 模型评估
在以下三种适应场景评估:
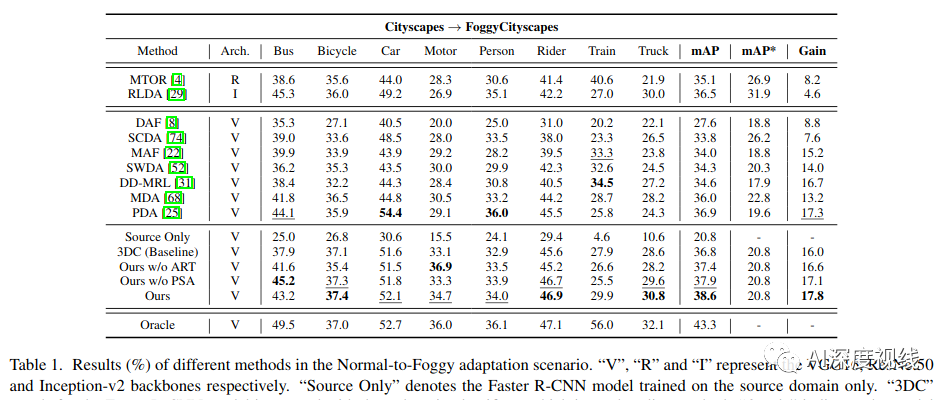
Normal-to-Foggy (Cityscapes→Foggy Cityscapes)
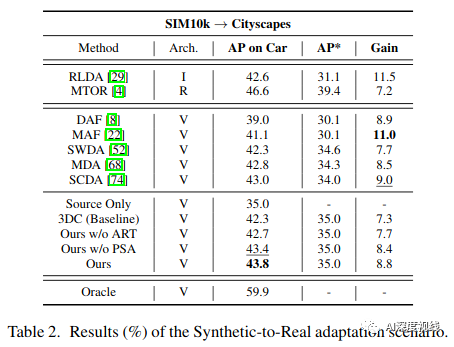
Synthetic-to-Real(SIM10k→Cityscapes)
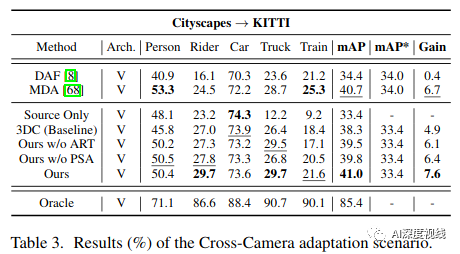
Cross-Camera(Cityscapes→KITTI).
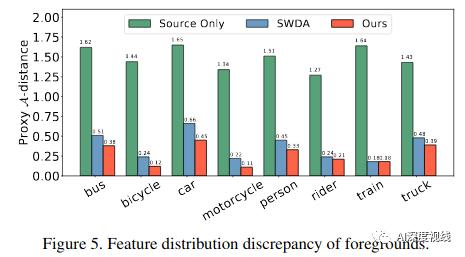
4.2 深入分析
前景特征分布差异
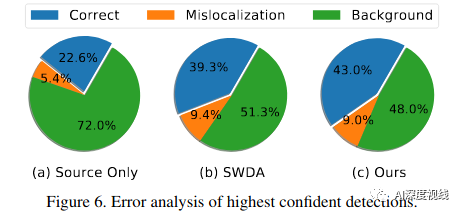
最高可信度检测的误差分析:
定性结果:

重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集3500人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!


