可逆神经网络(Invertible Neural Networks)详细解析:让神经网络更加轻量化

©作者 | 初识CV
单位 | 海康威视
研究方向 | 计算机视觉
前言
本文以可逆残差网络(The Reversible Residual Network: Backpropagation Without Storing Activations)作为基础进行分析。
-
因为编码和解码使用相同的参数,所以 model 是轻量级的。可逆的降噪网络 InvDN 只有 DANet 网络参数量的 4.2%,但是 InvDN 的降噪性能更好。 -
由于可逆网络是信息无损的,所以它能保留输入数据的细节信息。 无论网络的深度如何,可逆网络都使用恒定的内存来计算梯度。
下面是 Pytorch summary 的结果,Forward/backward pass size(MB): 218.59 就是需要保存的中间变量大小,可以看出这部分占据了很大部分显存(随着网络深度的增加,中间变量占据显存量会一直增加,resnet152(size=224)的中间变量更是占据总共内存的 606.6÷836.79≈0.725 )。如果不存储中间层结果,那么就可以大幅减少 GPU 的显存占用,有助于训练更深更广的网络。
import torch
from torchvision import models
from torchsummary import summary
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
vgg = models.vgg16().to(device)
summary(vgg, (3, 224, 224))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 1,792
ReLU-2 [-1, 64, 224, 224] 0
Conv2d-3 [-1, 64, 224, 224] 36,928
ReLU-4 [-1, 64, 224, 224] 0
MaxPool2d-5 [-1, 64, 112, 112] 0
Conv2d-6 [-1, 128, 112, 112] 73,856
ReLU-7 [-1, 128, 112, 112] 0
Conv2d-8 [-1, 128, 112, 112] 147,584
ReLU-9 [-1, 128, 112, 112] 0
MaxPool2d-10 [-1, 128, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 295,168
ReLU-12 [-1, 256, 56, 56] 0
Conv2d-13 [-1, 256, 56, 56] 590,080
ReLU-14 [-1, 256, 56, 56] 0
Conv2d-15 [-1, 256, 56, 56] 590,080
ReLU-16 [-1, 256, 56, 56] 0
MaxPool2d-17 [-1, 256, 28, 28] 0
Conv2d-18 [-1, 512, 28, 28] 1,180,160
ReLU-19 [-1, 512, 28, 28] 0
Conv2d-20 [-1, 512, 28, 28] 2,359,808
ReLU-21 [-1, 512, 28, 28] 0
Conv2d-22 [-1, 512, 28, 28] 2,359,808
ReLU-23 [-1, 512, 28, 28] 0
MaxPool2d-24 [-1, 512, 14, 14] 0
Conv2d-25 [-1, 512, 14, 14] 2,359,808
ReLU-26 [-1, 512, 14, 14] 0
Conv2d-27 [-1, 512, 14, 14] 2,359,808
ReLU-28 [-1, 512, 14, 14] 0
Conv2d-29 [-1, 512, 14, 14] 2,359,808
ReLU-30 [-1, 512, 14, 14] 0
MaxPool2d-31 [-1, 512, 7, 7] 0
Linear-32 [-1, 4096] 102,764,544
ReLU-33 [-1, 4096] 0
Dropout-34 [-1, 4096] 0
Linear-35 [-1, 4096] 16,781,312
ReLU-36 [-1, 4096] 0
Dropout-37 [-1, 4096] 0
Linear-38 [-1, 1000] 4,097,000
================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 218.59
Params size (MB): 527.79
Estimated Total Size (MB): 746.96
----------------------------------------------------------------

可逆神经网络
网络的输入、输出的大小必须一致。
网络的雅可比行列式不为 0。
1.1 什么是雅可比行列式?



1.2 雅可比行列式与神经网络的关系
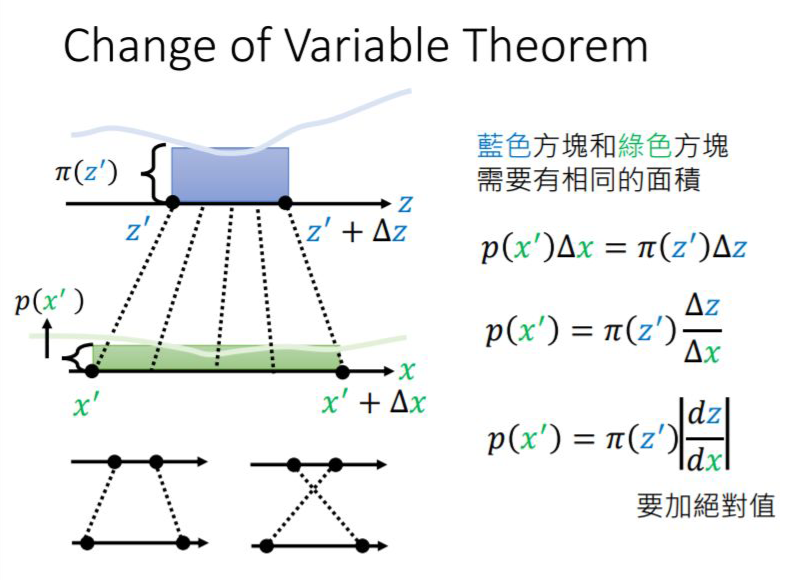
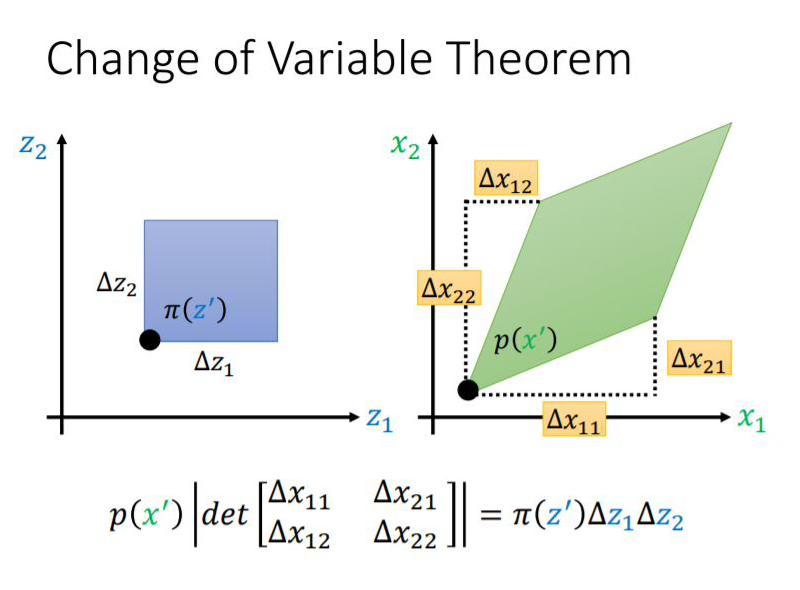
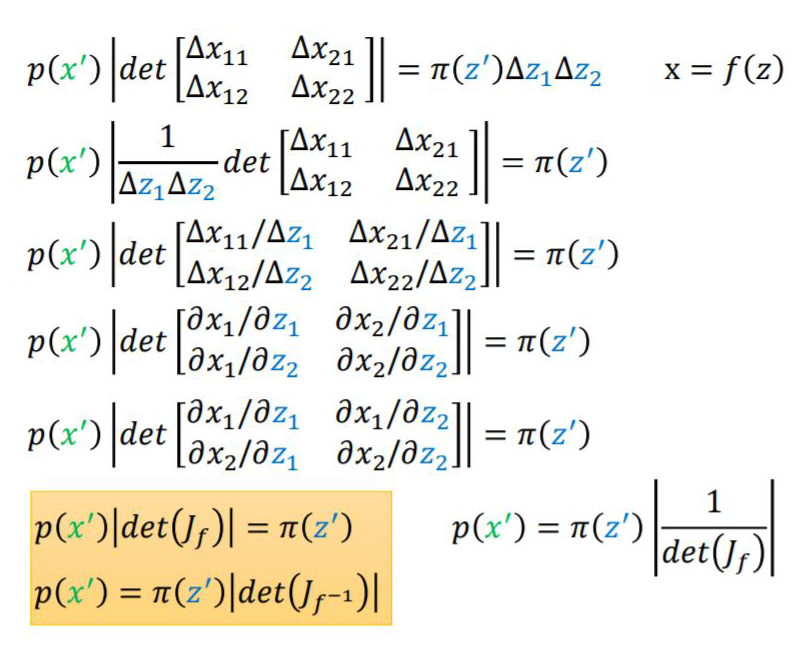
顺便提一下,flow-based Model 优化的损失函数如下:
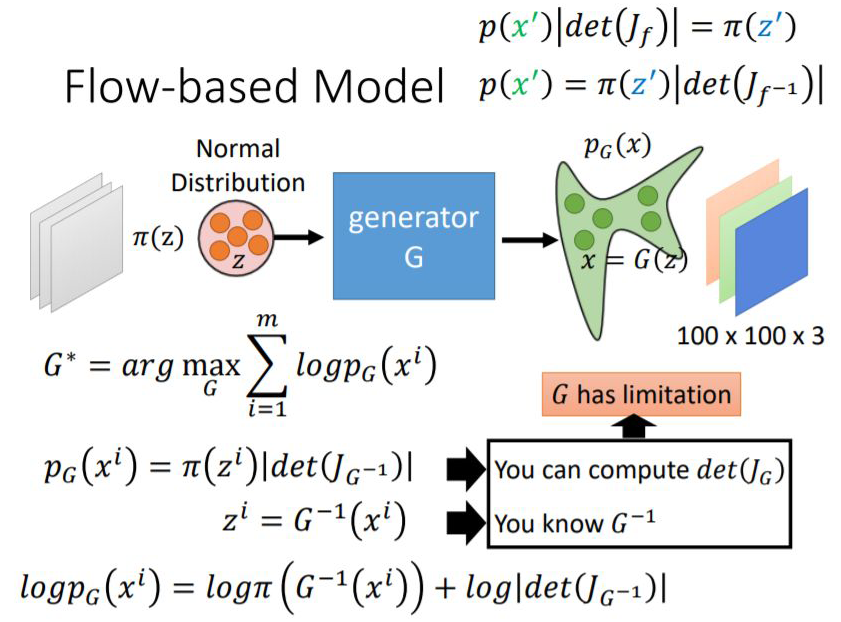
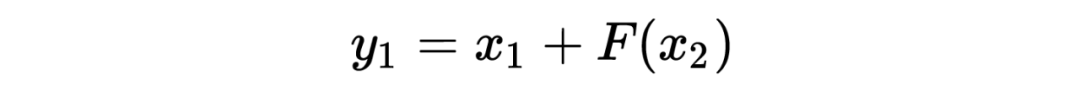
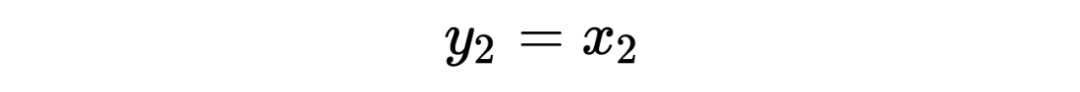
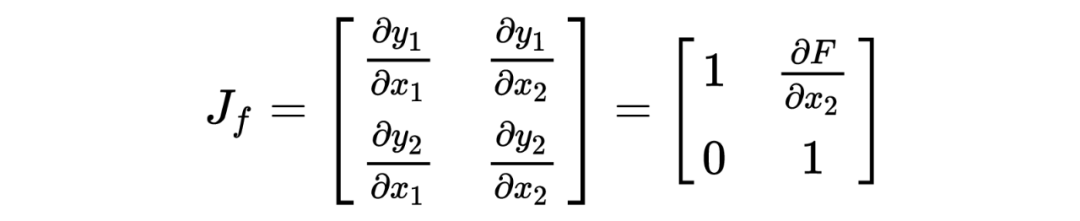
1.3 可逆残差网络(Reversible Residual Network)

论文标题:
The Reversible Residual Network: Backpropagation Without Storing Activations
论文链接:
https://arxiv.org/abs/1707.04585
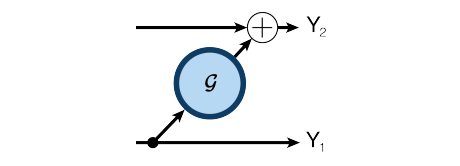
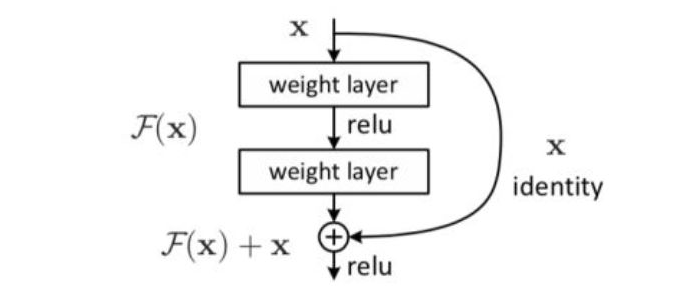
多伦多大学的 Aidan N.Gomez 和 Mengye Ren 提出了可逆残差神经网络,当前层的激活结果可由下一层的结果计算得出,也就是如果我们知道网络层最后的结果,就可以反推前面每一层的中间结果。这样我们只需要存储网络的参数和最后一层的结果即可,激活结果的存储与网络的深度无关了,将大幅减少显存占用。令人惊讶的是,实验结果显示,可逆残差网络的表现并没有显著下降,与之前的标准残差网络实验结果基本旗鼓相当。
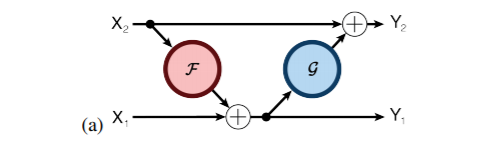
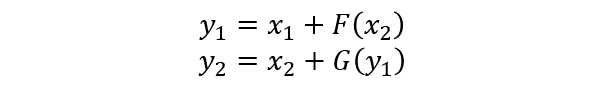
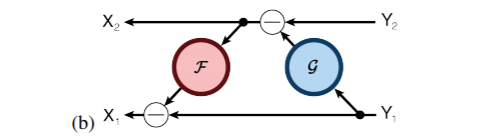
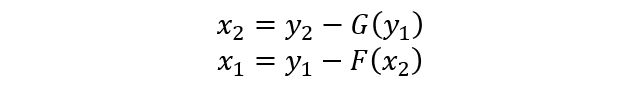
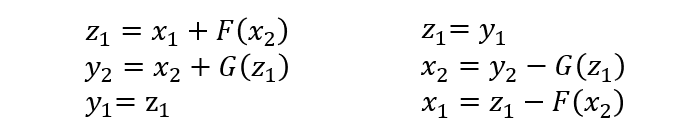

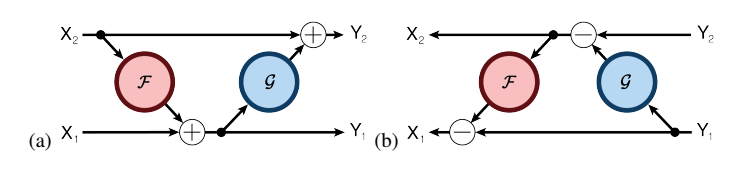
其编码公式如下:
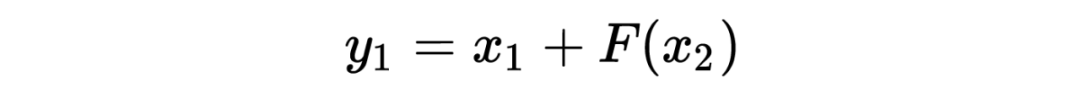
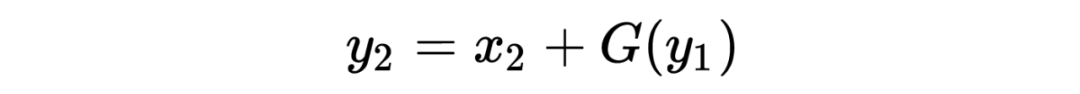
其解码公式如下:
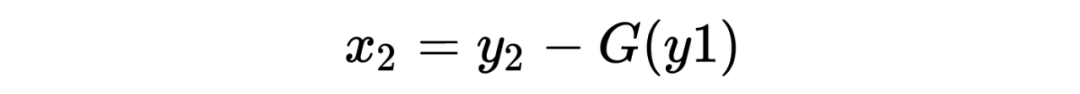
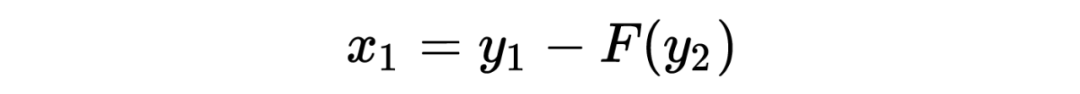
为了计算雅可比矩阵,我们更直观的写成下面的编码公式:
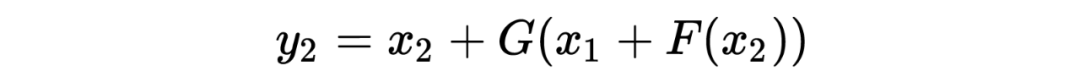
它的雅可比矩阵为:
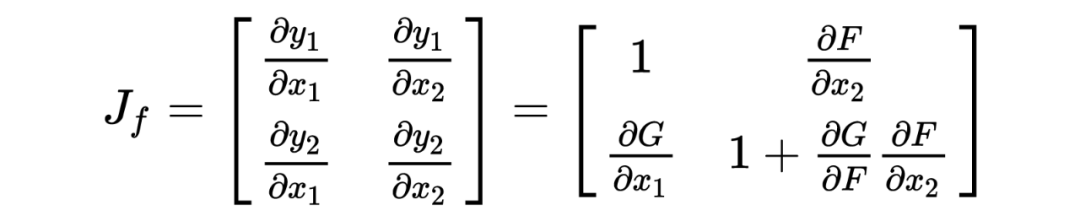
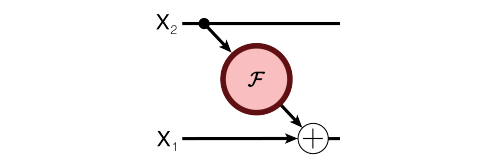
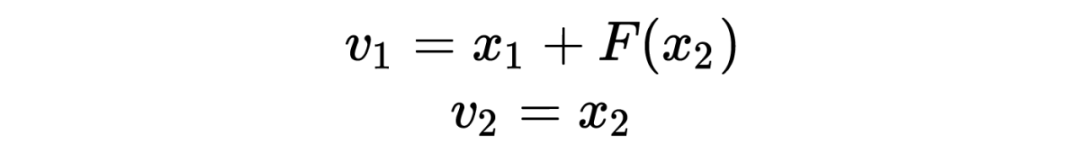
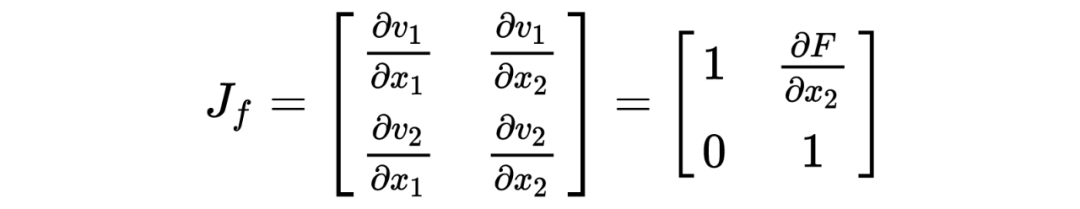
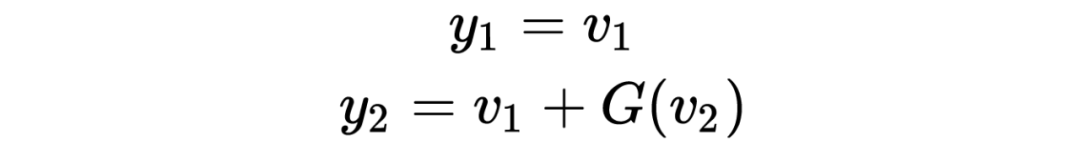

反向传播(BP)算法
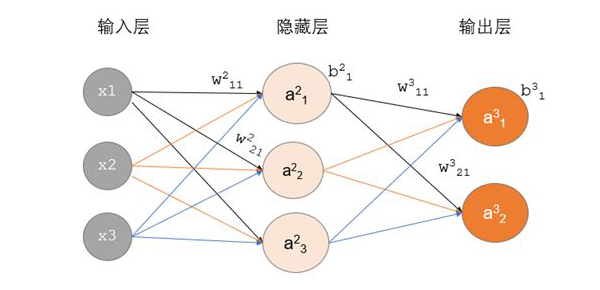
-
x1,x2,x3:表示 3 个输入层节点。 -
:表示从 t-1 层到 t 层的权重参数,j 表示 t 层的第 j 个节点,i 表示 t-1 层的第 i 个节点。 -
:表示 t 层的第 i 个激活后输出结果。 -
g(x):表示激活函数。
正向传播计算过程:
隐藏层(网络的第二层)

输出层(网络的最后一层)
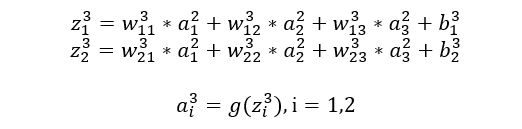
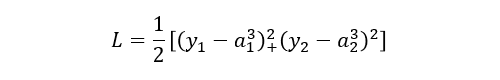
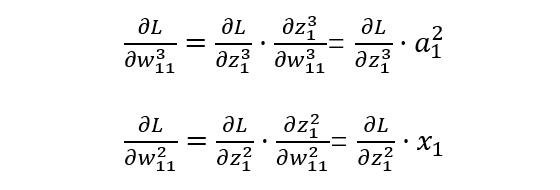
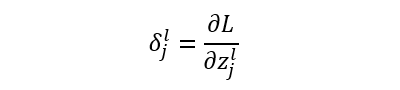
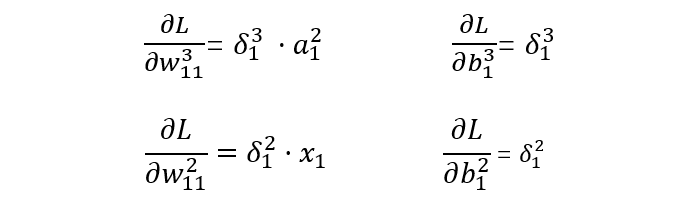
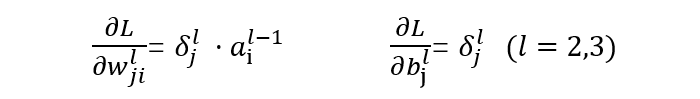
输出层

隐藏层
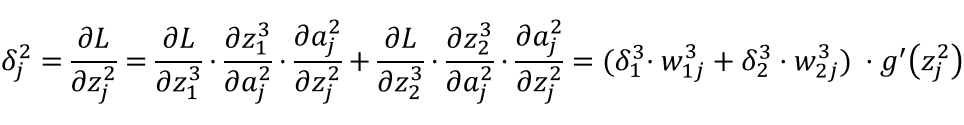
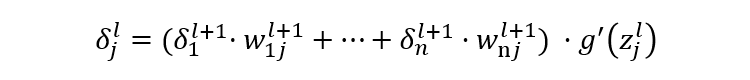

残差网络(Residual Network)
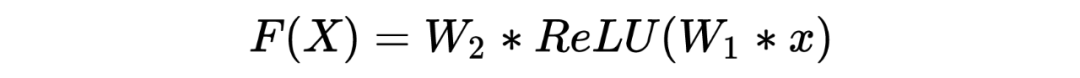

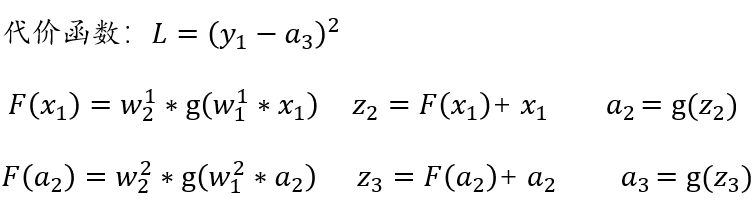
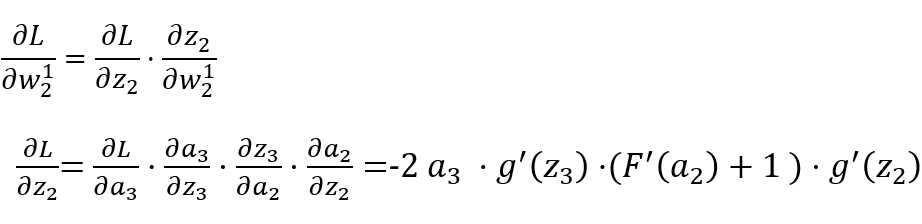

参考文献

独家定制「炼丹贴纸」
限量 200 份!
扫码回复「贴纸」
立即免费参与领取
👇👇👇

🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧

登录查看更多
相关内容
专知会员服务
17+阅读 · 2020年6月4日
专知会员服务
26+阅读 · 2020年3月26日
专知会员服务
34+阅读 · 2020年2月27日
Arxiv
17+阅读 · 2021年3月23日




相关VIP内容
专知会员服务
17+阅读 · 2020年6月4日
专知会员服务
26+阅读 · 2020年3月26日
专知会员服务
34+阅读 · 2020年2月27日
相关资讯
相关论文
Arxiv
17+阅读 · 2021年3月23日