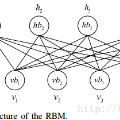
通过学习可观测数据的概率密度而随机生成样本的生成模型在近年来受到人们的广泛关注, 网络结构中包含多个隐藏层的深度生成式模型以更出色的生成能力成为研究热点, 深度生成模型在计算机视觉、密度估计、自然语言和语音识别、半监督学习等领域得到成功应用, 并给无监督学习提供了良好的范式. 本文根据深度生成模型处理似然函数的不同方法将模型分为三类: 第一类方法是近似方法, 包括采用抽样方法近似计算似然函数的受限玻尔兹曼机(Restricted Boltzmann machine, RBM)和以受限玻尔兹曼机为基础模块的深度置信网络(Deep belief network, DBN)、深度玻尔兹曼机(Deep Boltzmann machines, DBM)和亥姆霍兹机, 与之对应的另一种模型是直接优化似然函数变分下界的变分自编码器以及其重要的改进模型, 包括重要性加权自编码和可用于半监督学习的深度辅助深度模型; 第二类方法是避开求极大似然过程的隐式方法, 其代表模型是通过生成器和判别器之间的对抗行为来优化模型参数从而巧妙避开求解似然函数的生成对抗网络以及重要的改进模型, 包括WGAN、深度卷积生成对抗网络和当前最顶级的深度生成模型BigGAN; 第三类方法是对似然函数进行适当变形的流模型和自回归模型, 流模型利用可逆函数构造似然函数后直接优化模型参数, 包括以NICE为基础的常规流模型、变分流模型和可逆残差网络(i-ResNet), 自回归模型(NADE)将目标函数分解为条件概率乘积的形式, 包括神经自回归密度估计(NADE)、像素循环神经网络(PixelRNN)、掩码自编码器(MADE)以及WaveNet等. 详细描述上述模型的原理和结构以及模型变形后, 阐述各个模型的研究进展和应用, 最后对深度生成式模型进行展望和总结.