基础 | GRU神经网络
作者:黑龙江大学nlp实验室本科生甄冉冉
现在目前用的最多的三种神经网络是CNN,LSTM,GRU。其中,后两者都是RNN的变种,去年又给RNN发明了个SRU(优点是train RNN as fast as CNN),SRU以后再讲,目前先消化了这个GRU再说。
GRU,Gated Recurrent Unit,门控循环单元。意思大概理解就是在RNN上多加了几个门,目的和LSTM基本一样,为了加强RNN神经网络的记忆能力。
我们先来回忆下最初的SimpleRNN
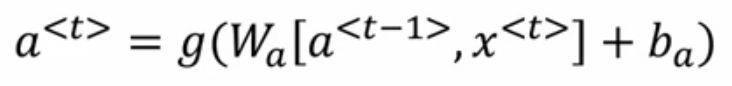
其中a是记忆单元,g是激活函数,x是输入,b偏执bias,t是时间点。
画图就是这样的:
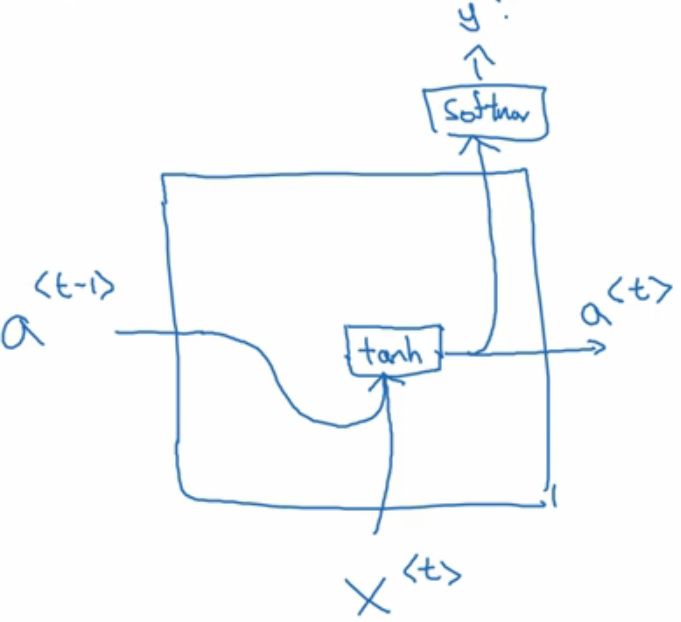
比如下面的一个机器翻译的例子。
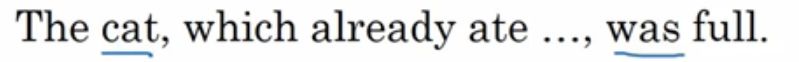
单数cat和was相聚甚远,如果考虑到SimpleRNN的长时间记忆会导致梯度消失的重大问题,有些人就在论文中提出了 GRU (Simplified)简化版。
首先,GRU的记忆单元是C

(也就是说上面的simpleRNN的a的功能给了C,主要是为了和LSTM区别开)
进入单元后,将用C~代替C:
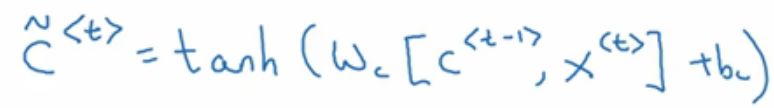
重点来了,GRU的真正重要的思想是有一个
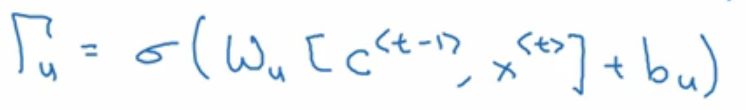
因为
我们假设cat,用一个bit记录这个特征,单数设为1,复数的话设为0。(真正网络中会有自己独特的特征记法)
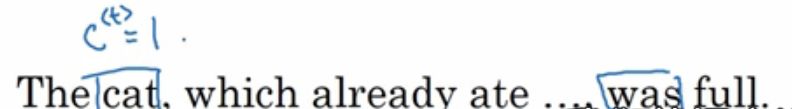
我们希望这个记忆单元C=1能一直保留到was那里,如

即使不是1,实际上也不可能不变是1的,但是只要和1别差距太大就行。其他的特征让C中用其他的参数记录就行,别影响我cat的就行。
那么怎么才能保证cat的特征单元不变呢?这就用到下一个门了:
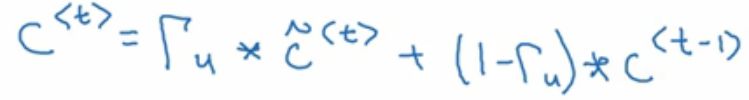
看上面的公式,我们想,怎么才能让C_t依然等于C_t-1时刻呢?那么就是
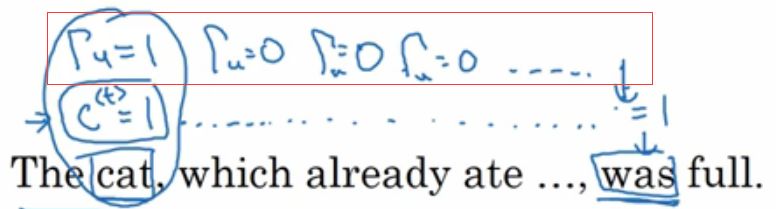
这个时候时间到了was这里时,C中还记着cat单数的事呢。而实际上,
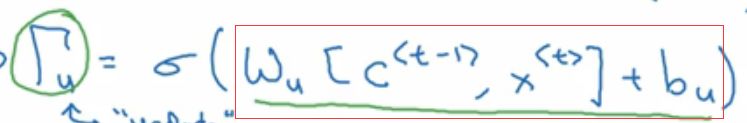
是个负很大的数,也就是经过sigmoid后接近0了。所以,上述的情况是可以的。
到这里,这个简化版的GRU基本讲完了,看看可视化单元:
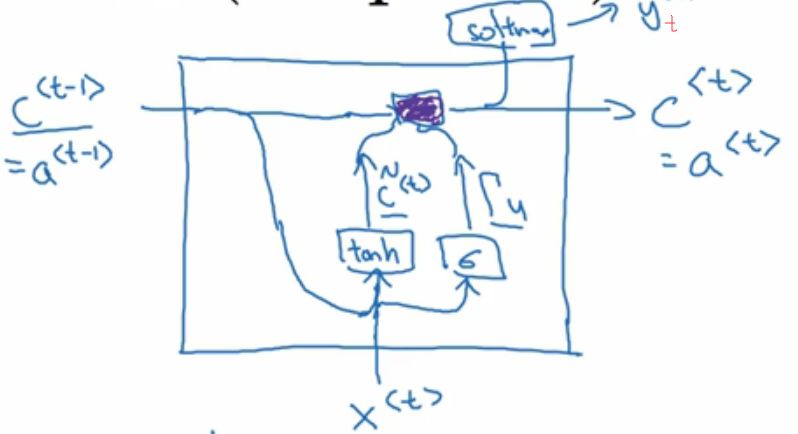
公式为:
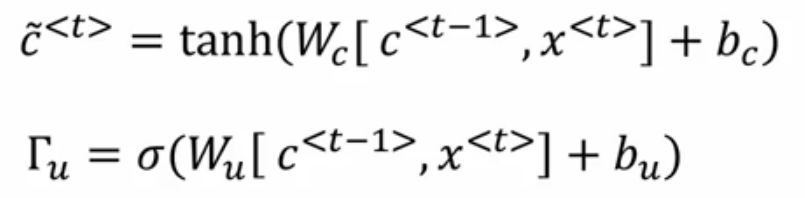
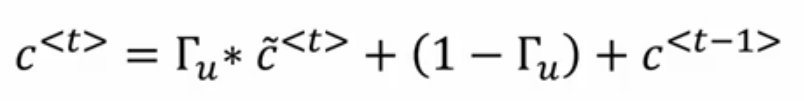
是不是也看到简化俩字了?
是的没错,经过研究者的不断探究,终于研究出来一种适合几乎各种研究实验的新型GRU网络是这样的:
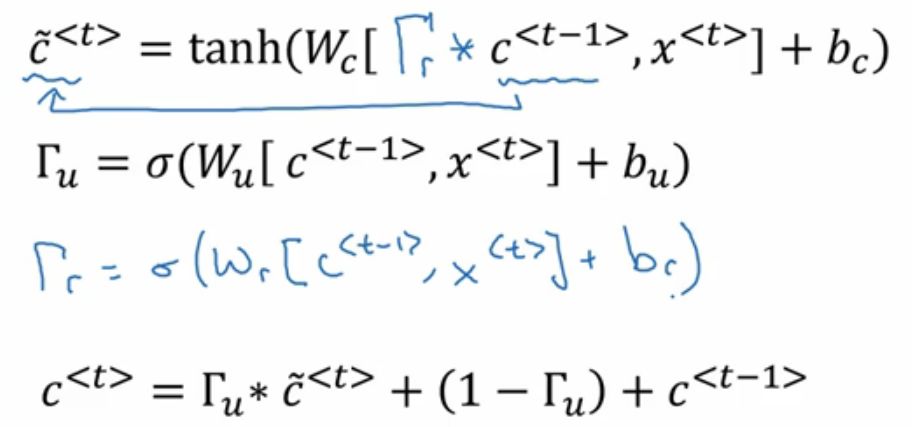
这个GRU可以经过经过更加深度的训练而保持强壮记忆力!
这里的第一个公式:
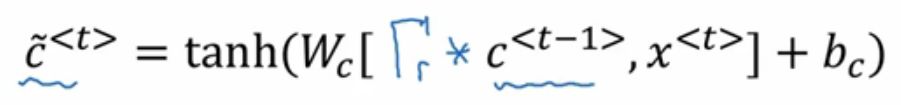

而这个
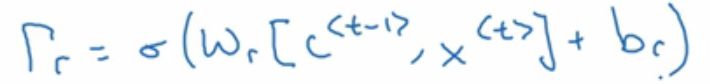
解释了
好啦,这里就真的讲完了。







