加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
DETR简介
近年来,Transformer 成为了深度学习领域非常受欢迎的一种架构,它依赖于一种简单但却十分强大的机制——注意力机制,使得 AI 模型有选择地聚焦于输入的某些部分,因此推理更加高效。但令人意外的是,计算机视觉领域一直还未被 Transformer 所席卷。
为了填补这一空白,Facebook AI 的研究者推出了 Transformer 的视觉版本——Detection Transformer(DETR),用于目标检测和全景分割。与之前的目标检测系统相比,DETR 的架构进行了根本上的改变。这是第一个将 Transformer 成功整合为检测 pipeline 中心构建块的目标检测框架。
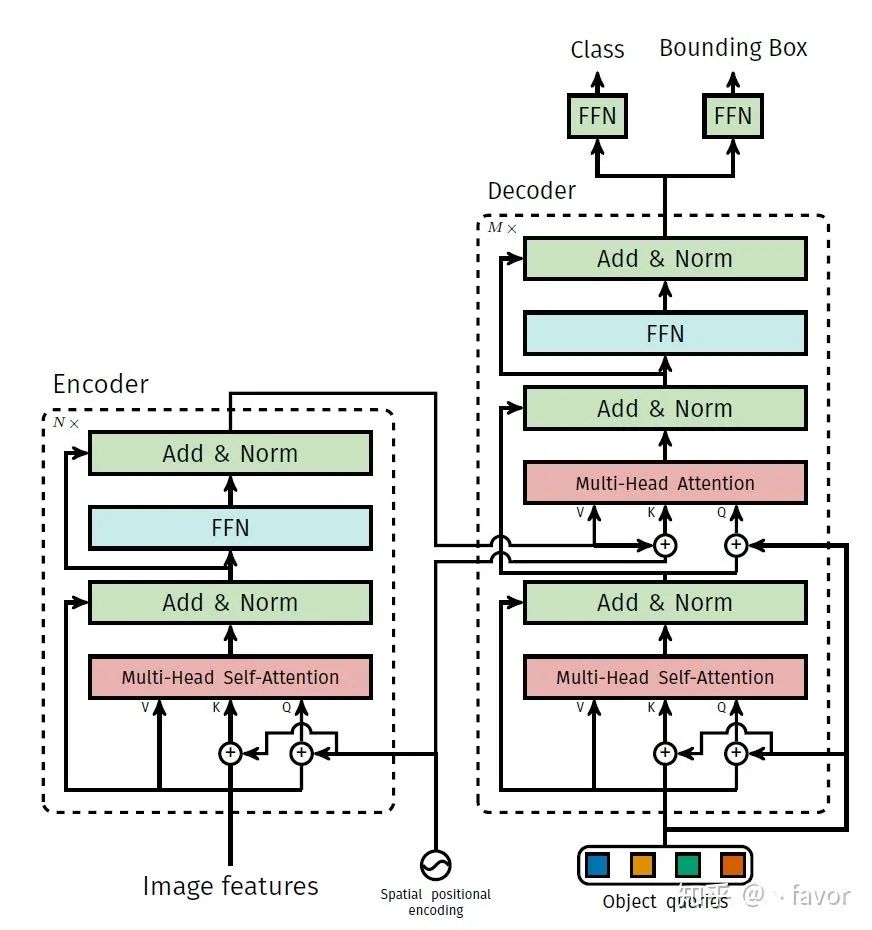
DETR 将目标检测任务视为一种图像到集合(image-to-set)的问题。给定一张图像,模型必须预测所有目标的无序集合(或列表),每个目标基于类别表示,并且周围各有一个紧密的边界框。这种表示方法特别适合 Transformer。因此,研究者使用卷积神经网络(CNN)从图像中提取局部信息,同时利用 Transformer 编码器-解码器架构对图像进行整体推理并生成预测。
在定位图像中的目标以及提取特征时,传统计算机视觉模型通常使用基于自定义层的复杂且部分手动操作的 pipeline。DETR 则使用更为简单的神经网络,它可以提供一个真正的端到端深度学习解决方案。
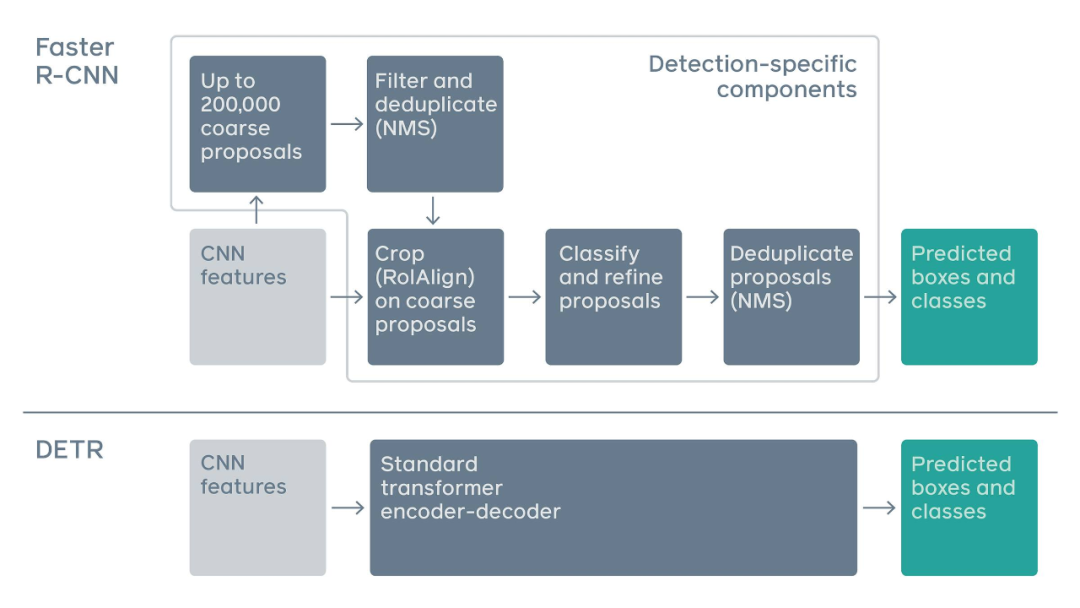
传统两阶段检测系统,如 Faster R-CNN,通过对大量粗糙候选区域的过滤来预测目标边界框。与之相比,DETR 利用标准 Transformer 架构来执行传统上特定于目标检测的操作,从而简化了检测 pipeline。
DETR 框架包含一个通过二分匹配做出独特预测的基于集合的全局损失,以及一个 Transformer 编码器-解码器架构。给定一个小集合固定的学得目标查询,DETR 对目标和全局图像背景的关系作出推理,从而直接并行输出最终的预测集。
DETR 的新型架构有助于提升计算机视觉模型的可解释性,并且由于其基于注意力机制,所以当它做预测时,很容易就能观察到网络正在查看图像的哪部分区域。
Facebook AI 的研究者也希望 DETR 可以促进目标检测领域的进展,并开发出处理双模态任务的新方法。
基于Transformer的目标检测效果究竟如何?
昨日DETR提出之后,就引起了计算机视觉圈广泛的讨论。赞赏者有之,批评者有之,下面我们就来看看来自知乎的观点:
https://www.zhihu.com/question/397624847/answer/1249866366
本文来自知乎问答,回答已获作者授权,著作权归作者所有,禁止二次转载。
给力就完事了。给力到ECCV under review的时候挂在arixv上公然放出submission id也不想喷它。毕竟看完这篇文章给我第一观感是“此处不留爷,自有留爷处”。
整体观感上,这篇文章真正妙用了Transformer,而不仅仅是说明self-attention能代替卷积,甚至做出了新高度。类似后者的文章有谷歌系列《Attention Augmented Convolutional Networks》——>《Stand-Alone Self-Attention in Vision Models》,用attention代替CNN这样。除此之外,文章也很有开路之风,实验上非常克制(没有trick注意没有trick),但是性能上对标Faster-Rcnn是完全没有问题的,同时又告诉你这个方法的limitation在哪里。这种文章中的大度风范即便是挂个submission id出来也找不到槽点。
再大致说一下文章内容。整体做法还真就像翻译的操作,这也能想到并且能work也是强。CNN backbone以及Transformer encoder就不介绍了,基本上就是提特征的重点就是positional embedding了,不过也是常规操作。重中只重就是在decoder上面。如何在没有anchor也不用nms的情况下得到结果呢?做法其实有点像翻译,只不过很抽象。图上的object queries实际上是N个emebding,更具体得说应该是N个实例query的embedding(我理解是这样),退一步不准确一点可以简单理解成位置。N是固定值但是emebding完之后N个quries都不太一样。所以差不多的意思就是告诉模型要100个实例,然后decoder根据encoder得到特征的位置和显著性decoder出100个抽象点代表instance,其中部分是前景instance,部分是背景instance,前景的就class+box loss,背景的就当背景。这就是训练过程。推理过程也就很简单了,前景的就直接用,背景的就丢掉。
这思路自然是强无敌了,毕竟我能想到的只是CNN+Transformer然后再回到传统检测那一套。除此之外,fair还很general的告诉了填坑者坑要怎么填。比如由于Transformer的特点对大目标检测很好但是对小目标检测不好;由于N的限制,每次只能检测100个;GFLOPs看着还行,但是速度却不怎么行之类的。并且瞄了一眼代码也是非常简洁,底下还有一句:欢迎魔改。
总而言之就是各种没毛病,a novel and solid work!
https://www.zhihu.com/question/397692959/answer/1249687016
本文来自知乎问答,仅用于学术分享
,著作权归
作者所有。
这是一篇很出色的工作。因为检测的输出是不定长的,所以用类似翻译的网络真的太妙了!之前的检测都要额外输出很多东西。将来肯定也有人用相似的思路去做姿态之类的应用。
不过,显存占用也挺劝退的,每块V100(32G显存)只能放下四张图片的batch,64个batch是用了16块V100实现的。在 V100/A100/相同量级的显卡 普及之前,或者这类模型被简化之前,这个工作注定是普通炼丹群众无法follow的。
关于transformer的原理,这篇文章描述的挺好的:
https://jalammar.github.io/illustrated-transformer/
Toyota Technological Institute at Chicago · 计算机视觉
https://www.zhihu.com/question/397624847/answer/1250073418
本文来自知乎问答,回答已获作者授权,著作权归作者所有,禁止二次转载。
3. 代码好简单(我fmass就是不用detectron2(开玩笑的));
5. 把panoptic也塞进来实在太厉害了,感觉一篇paper塞了两篇的东西;
6. 我就说怎么塞的进来。原来arxiv版本不止14页,估计submit的版本只有detection;
7. 只要你比别人的epoch多个20倍,你就能比别人效果好;
8. 跟小伙伴讨论了一下。觉得文章里说fpn能解决小物件可能是骗人的。因为连panoptic都做了,fpn怎么可能没做。
1. transformer encoder很有用。
faster-rcnn里面也请塞塞试试。
(当然啦反正本质上idea都是non-local,gcn什么的,但是经验证明transformer这个设计的结构是真的万能);
2. 第一反应还是会被直接回归box吓到,毕竟主流方法根本扔不掉anchor。就算centernet也是基于center回归hw(但是center本身不是回归的,同时center也可以认为是anchor)。这里是直接连center也回归了,真是牛啊,只要你能训练500epoch你啥不能回归;
3. object query也是不讲道理。虽然可以跟anchor联系在一起(别的回答有说),但是你再看看,他其实就是为了用transformer做set prediction,他就是一个必要的component,不需要一定有啥含义,他学出来是什么就是什么;
4. 本质上做的事情就是拿transformer decoder做set predictor,然后把这个idea用到object detection(把object detection看作set prediction task好像也不是首创吧)。但是这中间迈得步子有点大。怎么说呢,告诉我用transformer来做detection,我也想到改怎么做合适,因为会被以前的set prediction和detection的思维定势限制住,所以真的是看的时候感觉哐哐哐锤我脑门。(当然也可能是我不是太聪明);
5. 就是看set prediction这个task(disclaimer:没有追的很仔细),elucidating image-to-set这片paper也都没有用到parallel decoding的,还是考虑的把set prediciton变成一个sequence generation+auto-regressive。用object queries+parallel decoding已经是属于一个新的用法了吧。(当然啦,翻译里面有non-autogressive,但是那个setting和set prediciton不一样,怎么说呢,告诉我我能connect上,但是让我自己正向的想我想不到)
而且实际上,对set prediction, non-autogressive要比autoregressive的方法要更make sense多。
6. 这个panoptic segmentation也是好看,简单直接。
7. end to end是真的暴力。如果是我我能到map25我觉得都已经很满足了,竟然能暴力的堆到42,瑞思白 (如果pcv能跑500个epoch就好了)。
在极市平台后台回复
DETR
,即可获取论文下载链接,阅读更多论文细节。
推荐阅读:
![]()
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:AI移动应用-小极-北大-深圳),即可申请加入AI移动应用极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ ![]()