【泡泡图灵智库】重温视觉词袋模型:移动系统的分层定位体系结构
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Revisiting the Bag-of-Visual-Words model: A hierarchical localization architecture for mobile systems
作者:Loukas Bampis , Antonios Gasteratos
来源:IEEE Robotics and Autonomous System 113(2019)
编译:尹双双
审核:李永飞
提取码:p99e
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——Revisiting the Bag-of-Visual-Words model: A hierarchical localization architecture for mobile systems,该文章发表于IEEE Robotics and Autonomous System 113(2019)104-119。
为了提高移动平台的定位性能,本文提出了一种增强的视觉位置识别系统。我们的技术充分利用了连续输入的图像流,以便为匹配功能提供额外的信息。成熟的视觉词汇袋模型被应用到分层设计中,从一个自然场景的完整实体中获取视觉信息,并将其转化为描述,同时还保留了被探索世界的几何结构。我们将本文方法作为最先进的同步定位和构图算法的一部分进行了评估,并利用低功耗设备中的每个可用硬件模块开发并行化技术。所实现的算法已经在几个公开可用的数据集上进行了测试,这些数据集提供一致准确的定位结果,并防止了额外的几何验证可能导致的大部分冗余计算。
主要贡献
本文的主要创新之处在于将VWs(Visual Words)处理为描述的基本构建块,并将其逐渐扩展到更复杂的实体,每个实体都为匹配的功能提供了不同的属性。因此,vPR(Visual Place Recognition)系统的信息机制遵循自底向上的架构:
(1)局部特征提取;
(2)BoVW量化;
(3)组成结构感知的高层VWs群;
(4)单帧影像的描述;
(5)用连续的VWVs(Visual Word Vectors)描述物理场景。
算法流程
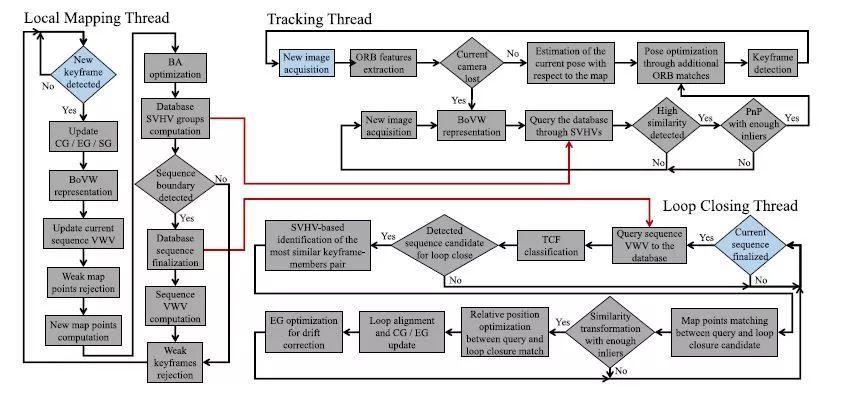
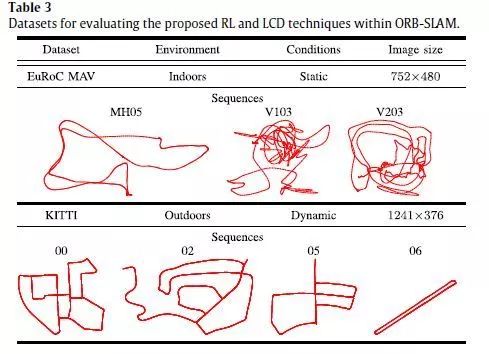
图1 本文定位系统框图。ORB-SLAM的每个并行线程的初始化块都用蓝色高亮显示。红色箭头对应于由本地映射线程共享的数据库度量。
为了提供一个有效的解决方案,我们将系统调整到ORB-SLAM体系结构中,并且只替换了生成VWVs和查询数据库的机制。因此,不需要额外的计算步骤,因为可以将局部特征、VWs和映射点视为预先计算的。我们的方法是在vwds的基本描述单元的基础上逐步构建的,并生成不同的工具来将结构信息合并到图像的匹配功能中,以及描述整个场景的特征。
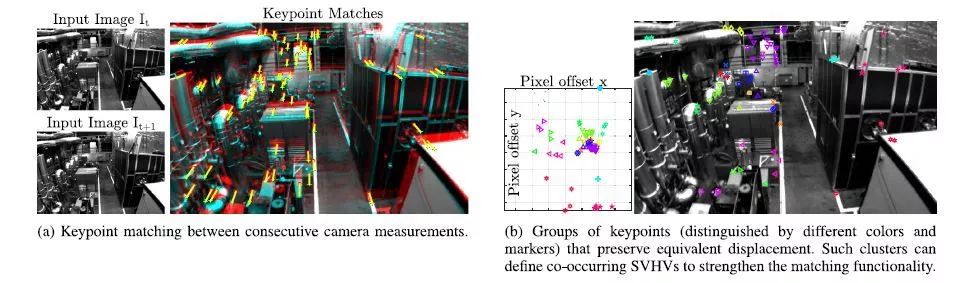
图2. 利用二维信息及其匹配的像素偏移量在连续帧之间对检测到的VWs进行聚类。
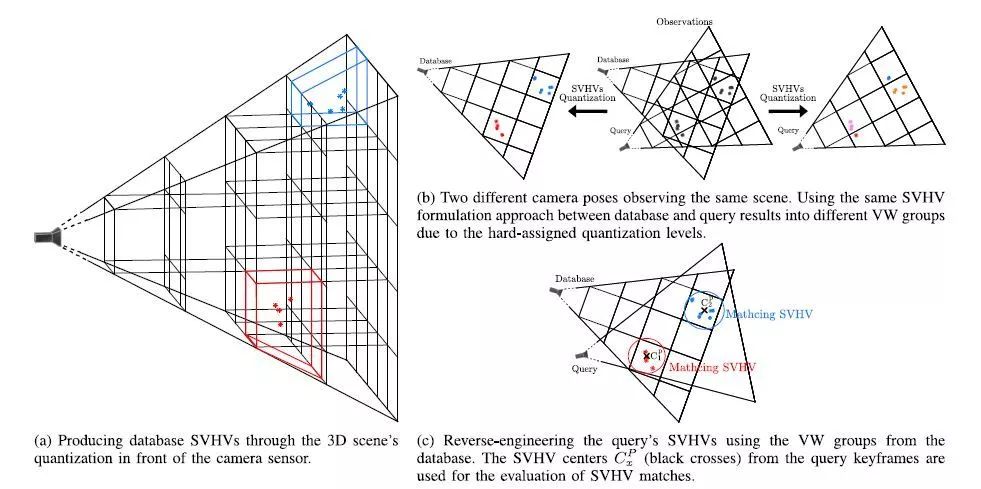
图3. 使用来自ORB-SLAM的三维信息,并与查询关键帧匹配,构造数据库SVHVs。星号表示观察到的地图点。不同的颜色对应不同的SVHVs。
1.通过结构感知视图不变的高阶视觉单词(SVHVs)
如图2,通过简单地从一张图像中聚类相邻的关键点,并不能保持相同的属性,因为当将不同深度的对象投影到相同的相机帧中时,仍然可以观察到距离较近的对象。与其他基于视觉短语的检索技术相比,计算出的组具有更好的旋转和尺度不变性。可以将这样一个关键点集群的BoVW表示为一个高阶VW,或结构感知的视图不变的高阶视觉单词(SVHVs),它利用环境的结构来识别一个重新游览过的地方。
在这项工作中,我们对ORB-SLAM计算每个地图点的三维位置的过程进行拓展,形成数据库SVHVs。每当局部映射线程处理一个新的关键帧K时,使用固定的量化级别/步长对摄像机前的三维世界进行量化,以减少计算量,从而对可观察到的映射点进行聚类(图3(a))。在N0个计算的SVHVs中,每个都包含一个它们VW成员(wi,i∈[1,Nv])的多重集,表示为Gj={wi1,wi2,wi3,....},j∈[1,N0]。然后将出现的Gj分给关键帧K作为Bk=<G1,G2,...GN0>。
在某些情况下,由于量化级别是硬分配的,所以在观察同一场景时,上述聚类输出可能会根据摄像机的姿态而变化(图5(b))。因此,在查询事件期间,将使用数据库VW组作为种子重新评估集群。为了计算查询关键帧(Kq)和数据库条目(Kq)之间的相似性度量,需要估计匹配的SVHV群集。对每个VW wx∈Kq和Gy∈Kd的Bd,共存的SVHV用下式计算:

上式中,cx表示一个不一致性系数:

px表示通过Kq得到的wx的3D位置,同时存在的SVHV Qy只有在欧几里德距离小于标准差的2倍(rc=2.0)时才会与wx更新。公式(2)和(3)负责检测相邻查询VWs的组,这些组同时是一个公共数据库SVHV的成员。最后,利用余弦相似度评分:
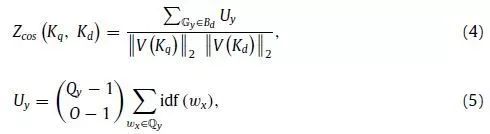
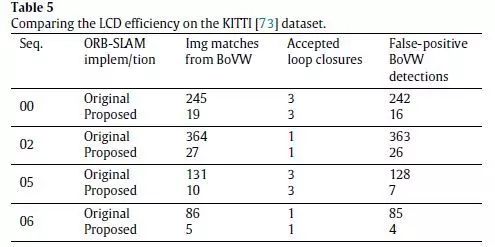
2.序列分割和序列图
我们采用了基于环境相似性一致的遍历路径的动态分割方法。这样,获得的图像根据其内容进行分组。为了实现这一点,我们跟踪一个逐渐增长的信号(C),该信号存储连续相机之间的可见测量值,并在表示序列边界的尺度空间域中检测局部极值。
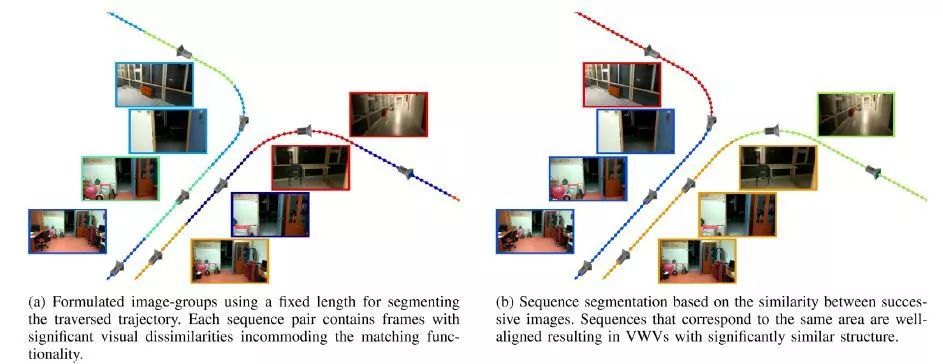
图4. 当系统两次访问同一区域时,正确的序列分割的重要性。相机姿态和示例图像根据它们所属的序列进行颜色编码。
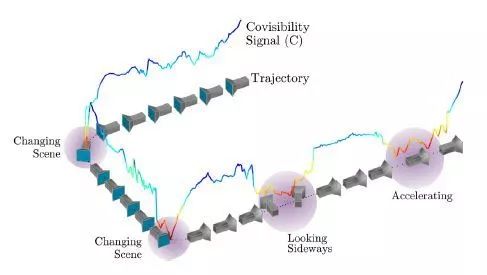
图5. 不同条件引起的共视信号C的局部极值。当遇到一个新的(不一样的)场景时,C可以捕捉相机视图的变化,瞬间侧视,或加速。共可见性度量的强度在[红,蓝]光谱中以颜色编码。
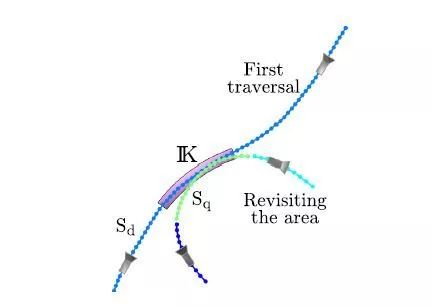
图6. 长度不等的序列之间的匹配。不同的序列用不同的颜色表示。当Sq查询到数据库时,公式(13)中最长序列的归一化项只在观察到相同和最短地图点的K个关键帧(品红区域)中计算。
3.通过序列视觉词向量进行匹配
对于每个具有NS 关键帧 Im (m∈[1,NS])的公式化序列S,我们计算相应的BoVW直方图。
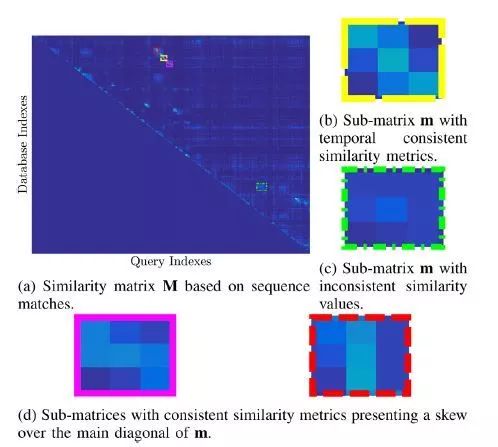
图7. 动态序列分割对相似矩阵m结构的影响
主要结果
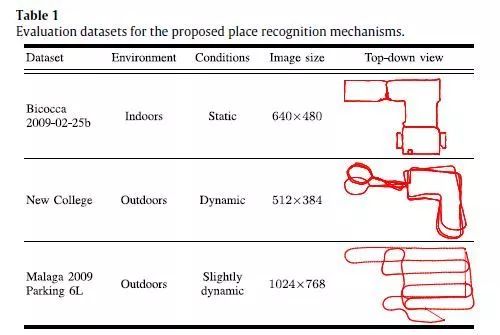
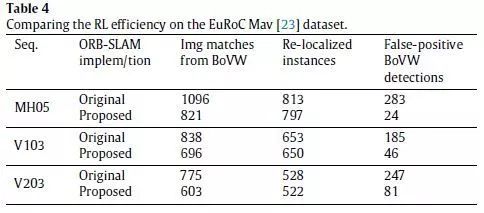
1、通过结构感知的高阶视觉词进行匹配
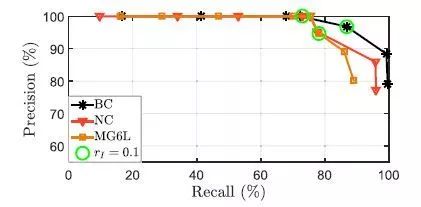
图8. 对应使用SVHVs的vPR具有挑战性的环境的P-R曲线
2、序列视觉字向量
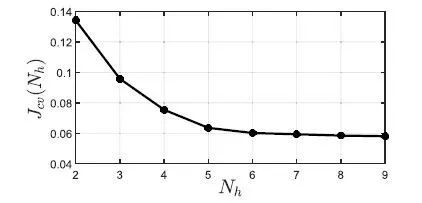
图9.不同Nh值的交叉验证错误。使用5个以上的逻辑回归分类器并不能显著提高性能。
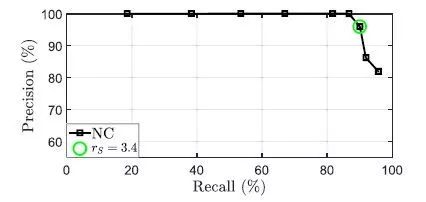
图10. 一个具有挑战性的数据集vPR使用序列匹配的P-R曲线
3、与最先进的vpr相比

Abstract
In this paper, an enhanced visual place recognition system is proposed aiming to improve the localization
performance of a mobile platform. Our technique takes full advantage of the continuous input image
stream in order to provide additional knowledge to the matching functionality. The well-established Bagof-
Visual-Words model is adapted into a hierarchical design that derives the visual information from the
full entity of a natural scene into the description, while it additionally preserves the geometric structure
of the explored world. Our approach is evaluated as part of a state-of-the-art SLAM algorithm, and parallelization techniques are exploited utilizing every available hardware module in a low-power device. The implemented algorithm has been tested on several publicly available datasets offering consistently accurate localization results and preventing the majority of redundant computations that the additional geometrical verifications can induce.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



