【泡泡图灵智库】基于基准点的开源视觉-惯导运动捕捉系统
泡泡图灵智库,带你精读机器人顶级会议文章
标题:An Open Source, Fiducial Based, Visual-Inertial Motion Capture System
作者:Michael Neunert ,Michael Bloesch,Jonas Buchli
来源:FUSION 2016
播音员:
编译:林瑞豪
审核:张蕾
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——基于基准点的开源视觉-惯导运动捕捉系统,该文章发表于FUSION 2016。
许多机器人任务依赖于给定工作空间内移动物体的精确定位。物体位姿和速度的信息可用于控制,运动规划,导航,与环境的交互或验证。通常使用运动捕捉系统来获得这种状态估计。然而,这些系统通常很昂贵,工作空间大小有限并且不适合户外应用。因此,我们提出了一种轻量且易于使用的视觉惯性同步定位和建图方法,该方法利用了经济的、纸质的人工地标,即所谓的基准点。结果表明,通过融合视觉和惯导数据,系统可以提供准确的估计,并且在快速运动和变化的光照条件下表现出较好的鲁棒性。传感器的估计值、基准点位姿和外在因素的紧密结合成确保了准确性,地图一致性并避免了对预校准的要求。通过开源实现代码和各种数据集(部分包含了Ground truth),大家能够使用这些数据集运行,测试,修改和扩展系统,或者在自己的机器人上直接运行该系统。
主要贡献
本文提出了一种基于单目-惯导EKF-SLAM的轻量级运动估计系统,该系统使用了人工地标。这项工作通过使用6 DoF的地标的角点观察并改编相应的卡尔曼滤波器,紧耦合SLAM和基于基准点的定位。这允许更小的地图尺寸和更精简的估计。与已有的依赖6DoF基准点的现有方法相比,所提出的框架在单个估计器中处理视觉测量和惯导数据,这保证了一致的数据并避免预校准和再校准。
算法流程
目前的定位系统包括两个主要组件:一个基准点检测器和一个融合传感器数据的EKF。在第一步中,由相机获取未失真的图像。然后,检测器处理图像,输出角坐标以及与每个检测到的标签相关联的唯一标识符号(id)。此外,它估计每个标签和相机之间的相对转换。该估计值通过迭代优化重投影误差获得,其中,重投影误差是被投影的3D角点的和它们在图像空间的检测值之间的误差。在第二步中,EKF使用来自重新检测到的标签角的信息来估计机器人的状态,包括位姿,线速度和角速度。另外,滤波器持续估计标签相对于像机坐标系的位置和方向。当第一次看到标签时,使用检测器输出的像机和标签之间的相对变换来初始化其位姿。在初始化之后,通过后续观察中使用标签角点的重投影误差,将在EKF内细化标签的位姿。为了确保一致性,相机和IMU之间的外部校准以及附加的IMU偏差也包括在滤波器状态中。
1、基准点
在系统中,使用的是AprilTags,并且是它在cv2cg中的实现版本。
2、硬件
我们的设置中,我们使用Skybotix VI-Sensor,用它的左边的相机和它的IMU。该传感器输出图像的频率是20HZ,输出IMU数据的频率是200HZ。
3、相机模型
本系统假设输入的是未失真图像,因此,输入时未失真图像的模型都是可以的。由于我们选择了Skybotix VI-Sensor,故选择了径向切变失真模型。例如一个3D点P在相机坐标系下时它对应的像素坐标:
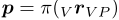
4、 滤波器
为了将从观测到的标签与车载惯导测量信息融合在一起,我们实现了扩展卡尔曼滤波器。为了传递机器人的状态,该滤波器使用惯导测量值,并根据可用的标签角测量值执行更新步骤。下面以单个传感器为例,推导必须的滤波公式:
4.1 坐标系系统
假设惯导工作空间坐标系系统W,假设重力点在这个坐标系的 负z方向。进一步,定义IMU坐标系B和相机坐标系为V.定义标签的坐标系系统T,原点是tag的几何中心,z轴和标签平面垂直。
4.2 传感器模型
先介绍IMU模型,考虑到高斯噪声和加速度计、陀螺仪的额外偏差项:
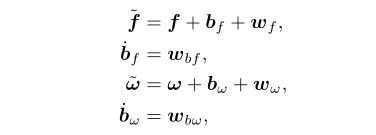
然后是观测到的标签的模型。我们提出了一个基于视觉模型的使用角投影的紧耦合策略。我们计算第i个标签角的位置:
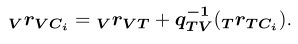
使用相机重投影地图,我们可以投影上述的点到图像平面,然后推导出相应的像素坐标系测量值
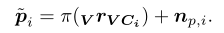
4.3滤波器状态和预测模型
我们把标签的位姿也包含到滤波器状态中来。滤波器可以细化标签位姿和保证地图一致性。使用机器中心表述来表示传感器状态和标签位姿,我们得到下述的滤波器状态:
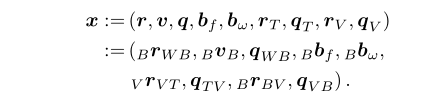
计算所选状态的总导数并插入IMU模型(1) - (4)得到:
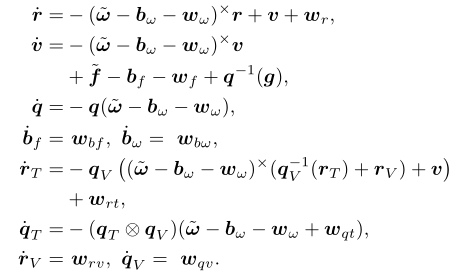
4.4 更新模型
通过直接使用重投影误差作为卡尔曼滤波器创新项来执行更新步骤。对每一个标签角,基于等式6,我们可以定义更新项
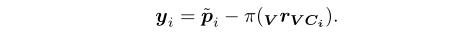
主要结果
1、 基准点估计的位姿评估
在table dataset上的结果:一开始的误差很小,在第一帧,基于重投影误差的初始化非常准,EKF进一步优化位姿后达到了毫米级精度。
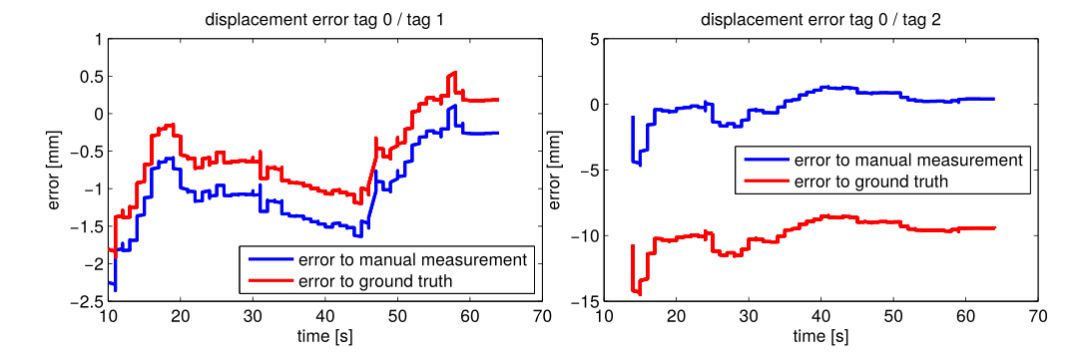
图1 估计得到的标签位置和人工测得的以及外部运动捕捉结果对比
此外,得到的标签的相对旋转误差大概在0.2-0.5度之间。
2、运动测试估计
2.1 数据集table上的结果:和外部运动捕捉系统相比(ground truth),位置误差厘米级。旋转误差最大不超过3度。
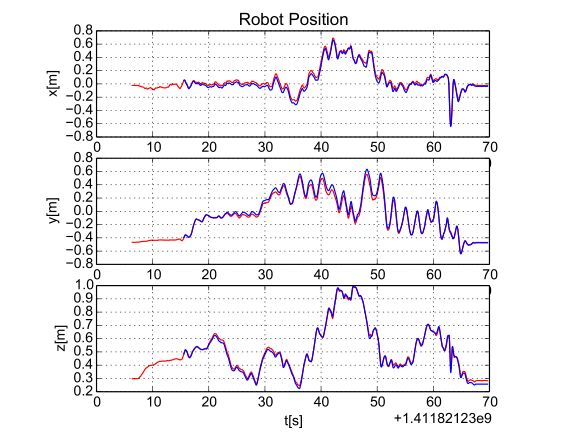
图2 估计得到的机器人位置(蓝色)和ground truth位置(红色)
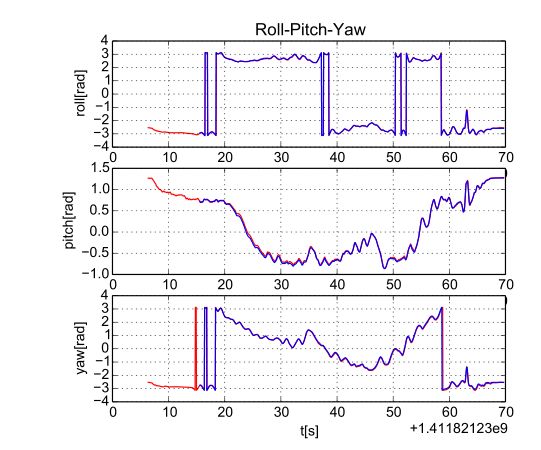
图3 估计得到的机器人旋转(蓝色)和ground truth旋转(红色)
2.2 数据集 dataset_1:
人为制造快速运动的场景,许多图像检测不到标签,只有20%的部分提供了惯性测量。此外,只有15%的部分有可视的标签。但是,当有其它的标签可视的时候,依旧是可以收敛到ground truth。
2.3 大范围数据集:
因为没有运动捕捉系统可以适用于这么大的区域,用回环的方式来测量精度。数据集pavillon和数据集cube 。评估算法的质量的参数有两个:重投影误差、系统输出的标签的位置和检测器的瞬时的标签测量值之间的位移。
cube:在回环时平均重投影误差时56.07像素。以检测器的位姿估计值作为参考,位置偏移是0.86m. 全程是70m长,36个标签。相对误差是1.2%。
pavillon:回环时的平均重投影误差时51.01像素,以检测器的位姿估计值作为参考,位置偏移时0.38M.全程80m,33个标签,相对误差时0.5%。
3、 在线的外部估计
没有ground truth,因此同一个环境录10个数据集来验证重复性,类似运动,50-60s,RMS值 位移是1.5cm,旋转是0.0035M。

Abstract
Many robotic tasks rely on the accurate localization of moving objects within a given workspace. This information about the objects’ poses and velocities are used for control, motion planning, navigation, interaction with the environment or verification. Often motion capture systems are used to obtain such a state estimate. However, these systems are often costly, limited in workspace size and not suitable for outdoor usage. Therefore, we propose a lightweight and easy to use, visual- inertial Simultaneous Localization and Mapping approach that leverages cost-efficient, paper printable artificial landmarks, so called fiducials. Results show that by fusing visual and inertial data, the system provides accurate estimates and is robust against fast motions and changing lighting conditions. Tight integration of the estimation of sensor and fiducial pose as well as extrinsics ensures accuracy, map consistency and avoids the requirement for precalibration. By providing an open source implementation and various datasets, partially with ground truth information, we enable community members to run, test, modify and extend the system either using these datasets or directly running the system on their own robotic setups.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com


