自注意模型学不好?这个方法帮你解决!

编者按:上周,微软亚洲研究院高级研究员胡瀚在 B 站分享了 ECCV 2020 论文“解耦自注意模型”。针对自注意模型中的退化现象,论文提出了解耦自注意模型,有效避免了这一退化现象,并证明了其在多种视觉识别任务中广泛有效,包括语义分割、物体检测、动作识别等。
论文直播分享回放视频
以下是直播分享的文字实录:
论文地址:
https://arxiv.org/pdf/2006.06668.pdf
代码地址:
https://github.com/yinmh17/DNL-Semantic-Segmentation
https://github.com/Howal/DNL-Object-Detection
大家好,我是来自微软亚洲研究院的胡瀚,今天我将给大家分享一个我们 ECCV 2020 的工作,题目叫 Disentangled Self-Attention Models,中文叫解耦自注意模型。这些是我的合作者。

首先,我将简要介绍一下什么是自注意模型,以及其它的一些应用。第二部分,我会讲一下它在计算机视觉应用的时候经常出现的一个现象,叫退化现象,以及我们对这个现象做的一些诊断分析。最后是方法和结果。

图2:内容提纲
我想大部分同学应该已经听说过自注意模型(Self-Attention Models)。这些模型在自然语言处理(NLP)领域比较成功。目前,它在 NLP 建模的时候,居于主导地位,几乎所有 NLP 领域的一些网络结构,都会基于这样一个模型。其中的先驱工作,是谷歌在2017年提出的 Transformer。如果没有听过 Transformer,可能也听过 GPT、BERT 这样一些很有名的预训练方法。还有我们微软亚洲研究院同事提出来的 MASS,UniLM,VL-BERT 等等预训练框架,它们都是以 Transformer 为基本的网络框架。

图3:在NLP 建模中居于主导地位的自注意模型
那什么是自注意模型?我们用 NLP 里的单词或者 token 来进行一个说明。本质上,它就是一个可以叠加的变换单元。对于每一个单词,这个模型会将输入的特征向量变换成输出的特征向量y。在变化过程中会编码单词和单词之间的关系,具体来说是通过3个投影向量来实现单词和单词之间的交互,分别是查询 Query、关键字 Key 以及这个单词的 Value 向量。
在计算过程中,每一个单词的输出向量 y 会表示成所有单词 Value 的一个加权求和。我们看这样一个公式(如图4),相应的权重 w 指代的是每个 Key 单词对每个 Query 的影响,通常我们用一个内积来去计算。
我们看看左边这样一个例子,这里显示的是有一个输出的 Query 单词,当时叫 making,它会受其它句子里其它单词的影响,这里颜色的深浅表示影响的大小。在这个历史里面,我们会发现 more difficult 对 making 的影响最大,这就是自注意模块的一个例子。这样的模块可以累积很多层,从而能够形成比较深的网络。

图4:对自注意模型的介绍
前面已经提到,这一模型在 NLP 领域居于主导地位。对于视觉来说,它并没有像在 NLP 领域应用的这么广泛。但是,它也已经被发现在很多地方很有用了,而且还在迅速发展。这里列举2个先驱的工作,第一个工作叫 Non-Local Neural Networks,这是发表在2018年 CVPR 的工作,这个工作将自注意模型应用在 backbone networks 里,将它作为卷积的补充。卷积主要是去建模一个局部的信息,而自注意模块可以建模全局信息,所以它们可以互补。那在这个应用里面,它本身是去建模所有像素之间的关系的。比如说这里有一个 X 像素,它在一个球上面,那么可以对这个视频里面其它帧,其它像素都可以产生影响。这篇论文发现,往网络里加入这个模块之后,可以改善很多任务的性能,包括物体检测、语义分割,还有动作识别。
第二个工作叫 Relation Networks,关系网络,也是发表在2018年 CVPR 上的。这个工作不是去建模像素和像素的关系,而是去建模物体和物体的关系。以前,针对物体和物体关系的建模其实没有很好的工具,有了这个模型之后,就可以实现第一个完全的端到端的物理检测器。

图5:自注意模型在视觉领域的两个先驱工作
除了这些先驱工作以外,自注意模型现在其实已经被用于很多视觉应用里了。总的来说,可以划分成3种应用:第一种是去建模像素和像素的关系,第二种是去建模物体和像素的关系,第三种则是建模物体和物体的关系。这里我列举一些有代表性的工作,需要注意的是,相关工作非常多,这里只列举了很小一部分来让大家对这三类应用有个感性的认识。

图6:对自注意模型当前工作的总结
关于像素和像素建模的问题,除了刚才提到的 Non-Local Neural Networks,尝试去和卷积互补以外,我们还有一些工作尝试去完全的替换卷积。
关于物体和像素关系的建模问题,会有些工作去尝试替换 RoIAlign 模块,这个模块也是在物体检测里必不可少的一个模块。近期还有一个很火的工作,叫 DETR,它是将 Transformer 整体应用到物体检测里去,几乎不需要任何物体检测这个领域相关的一些先验知识。
关于物体和物体关系建模的问题。刚才提到 Relation Networks,这个模型已经被广泛的应用于各种视频的识别任务里面,包括视频物体检测、多目标跟踪、视频动作识别等等。如果想了解更多更详细的进展,大家可以去看我在 CVPR 2020 做的一个 tutorial :

PPT链接: https://ancientmooner.github.io/doc/CVPR2020_tutorial_hanhu.pdf
下面我讲讲将自注意模型应用到计算机视觉的时候,会出现的退化现象,以及我们对此做的一些诊断分析。
在通常的理解里面,我们认为自注意模型是在建模一个 pairwise 的关系,也就是一个二阶的关系。例如在图7这个例子中,我们希望建模所有像素之间的关系。一个很重要的问题就是这个模型是不是真的能够学到这种二阶 pairwise 关系。

图7:自注意模型对 pairwise 关系的建模
如果说要学到一个有意义的二阶 pairwise 关系,那么我们会期待不同的 Query 像素会被不同的 Key 像素所影响。我们看图8的例子,左图指代 Query 像素,右图指 Key 像素,而这里示意的两个 Query 像素,一个位于汽车上面,一个位于消防栓上面。我们同时也示意了一些 Key 像素,这里有4个绿色的框。
如果说学到一个好的二阶关系,我们就希望它会有这样一个效果:红色的框主要被这2个绿色框(上面的两个)所影响;而黄色的框又被另外一些绿色的框(下面的两个)所影响。

图8:理想中的学习效果
但是实际上,我们会发现,结果和预期其实很不一样(如图9)。对于左边的这2个 Query 像素来说,通常会被同一组 Key 像素所影响,例如这里的2个像素(红色的线所连接的两个像素),那这也就意味着,自注意模型从一个 Query 有关的模型退化到了一个 Query 无关的模型。那起作用的很有可能是一个一阶的、全局的 unary 模型,而不是我们所想要的二阶的 pairwise 模型。

图9:实际中的学习效果
图10是一些更实际的例子。这2个例子分别将自注意模型应用到物体检测和语义分割里。这里白色的十字指的是 Query 像素,这里有2个 Query 像素,它们都在很不一样的地方,但是,我们会发现,不同的 Query 像素对应的 activation map,也就是注意力图,长得很不一样。这里颜色越暖,就表示影响力越大,所以我们看到这两个 activation map 几乎一模一样。同样地,我们可以观察到语义分割里其实也是很像的。这也就意味着,自注意模型很有可能退化到了一个一阶的、全局的 unary 模型。我们去年有一篇论文叫 GCNet,第一次发现并且研究了这样一种现象。

图10:退化现象的两个例子
那我们很自然就会想,是什么原因导致了这样一种退化现象的发生。为了回答这些问题,我们深入检查了自注意模型的数学表达式,我们看这样一个内积的形式。
我们发现其实这样一种表达式可以分解成两项,一项是白化的 pairwise 项,还有一项是隐藏的 unary 项,注意这里白化的 pairwise 意思就是说,和之前的 Query、Key 不太一样,我们形成白化。就是先减均值,减完均值之后再做内积。这样数学形式是更纯粹的一个 pairwise 项。而第二项则是只与 Key 相关,而与 Query 无关,所以我们称为一阶项。

我们研究了,如果只用一种项,没有另外一项,那么它学到的模型,在语义分割里面会有什么表现?然后我们发现,如果没有 unary 项,它的结果甚至比标准的自注意模型效果还要好。标准的自注意模型实际上既包含 unary 项,也包括 pairwise 项,这个结果表明在标准的自注意模型里面,二阶的 pairwise 项和一阶的 unary 项在一起学的时候,并没有被学好。

图12:pairwise 项和 unary 项单独学习的效果
进一步去看,就是每一项单独学的时候,都会学到什么样的视觉线索。图13中,左边的两幅图是单独用 pairwise 项学到的注意力图,分别对于2个 Query 像素的注意力图,也是左上角的 Query 像素和侧下方的 Query 像素。右边一幅图,是单独用 unary 项学到的注意力图。
我们发现,pairwise 项会学到同一个类别内部像素之间的关系。先看左边一幅图,图里的 Query 像素,位于图片天空的区域,可以看到,所有天空区域都有一个很高的响应。再看右边这个图,图里的 Query 像素位于汽车上面,所有汽车的像素都会有一个很高的响应。

图13:pairwise 项学到同一个类别内部像素之间的关系
我们再看单独用 unary 项的时候会学到什么样的特性。可以看到,图14的注意力图很像一个边缘图,主要集中在边缘的像素上面。我们去比对了一下真实(ground truth)的边缘图,会发现2者其实很相似。
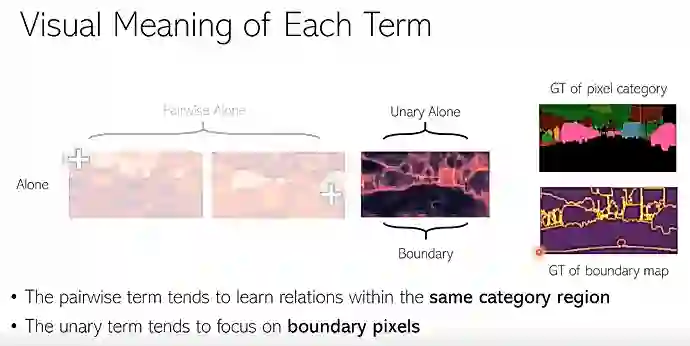
图14:unary 项学到边缘的像素
事实上,现在这些现象,在语义分割里其实是有一定普遍性的。为了证明这样一种普遍性,我们除了给一些可视化的例子外,还去做了统计分析。
我们统计了学到的注意力图和 GT 的每个像素类别的 region,以及边缘图的相关系数。图15为结果,其中63.5指的是 pairwise 项和像素区域图的一个相关系数,46.0表示 unary 项和边缘图的相关系数。它们都还比较高,所以可以看出它们其实有一个很强的相关性。
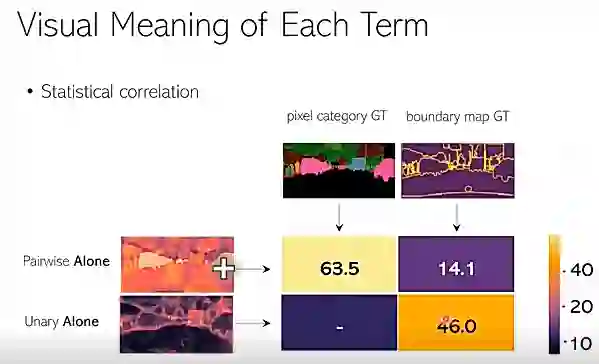
图15:不同项和对应部分的相关系数
接下来比较分别学,以及用标准的自注意模型同时去学的效果。图16是同时学的效果,我们会发现,下面2个图,跟上面比,语义要模糊很多,没有上面那么清晰。同时,我们也去统计了一下,它们和增值的一个相关性,我们看到,pairwise joint 的相关性从63.5,降到了31.8,unary joint 的相关性,从46.0降低到了17.2。这个结果表明在标准的自注意模型里面,联合学习这两项学到的语义特性,要比单独去学弱很多。

图16:联合学习这两项的效果比单独去学要弱很多
那为什么联合学习表现会很差?我们尝试去寻找背后的原因,重新去看一下相似度的计算过程。当我们把这两项,pairwise 项和 unary 项移到 exp 外面的时候,发现它们其实是乘项的关系。

图17:重新去看相似度的计算过程
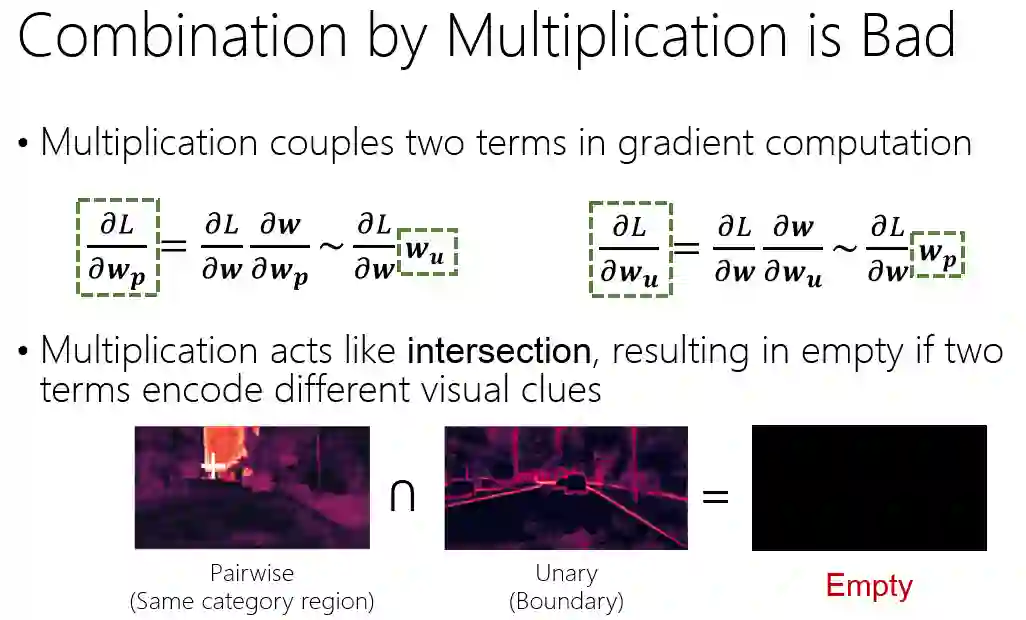
我们认为,乘项的联合不是一个太好的选择,主要有两个原因。第一个原因是乘项的联合会将两者的梯度耦合在一起。我们可以看图18中两项梯度反向传播的公式,左边是针对 pairwise 项的梯度,右边是针对 unary 项的梯度。可以看到 pairwise 项的梯度,它会和 unary 项的值呈正相关,unary 项的梯度会和 pairwise 项的值呈正相关。
这样一种特性其实不是很好,为什么?因为如果有一项值很小,比如 unary 项很小,几乎等于0,那么它对于 pairwise 项的梯度也几乎是0,也就是说这个 pairwise 项几乎不学习了,这样其实不利于优化。
另一方面,乘项的联合更像是取交集。比如,我们看图18这样两个图,它们其实是很不一样的视觉线索,一个是区域,一个是边缘。当它们取交集之后,那就是一个空集。整体是空集就没有任何意义了。所以不是很好。
有了以上的一些观察和分析,我们接着讲我们是怎么去解决这样一个退化问题的。刚才提到乘项的联合不是很好,因为是取交集,那第一个措施,就是把取交集变成取并集,我们叫 union。如果取并集的话,当两项学的东西不一样的时候,取并集之后,两项内容都会包含进来,最后这个总的注意力图会见到更多东西。那如何去实现便捷的操作呢?其实很简单,我们把乘法变成加法。通过加法操作,我们会发现它们的梯度,也可以被解耦开了,就跟它的值没关系。

图19:解决方法:把取交集变成取并集
我们在语义分割的一个比较常用的标准平台评测集 Cityscapes 上面做了实验,当我们将乘法替换成加法的时候,看到了0.7个点的提升。同时,可以看到它学到的注意力图也会更有意义,就是非常清晰。这些相关系数,同时也增加了很多。从31.8提升到了67.9,从17.2提升到了65.7,很显著的提升。

图20:在 Cityscapes 上做实验的数据提升
那这样是不是就足够了?还有没有其它耦合的因素?我们发现其实还是有的。
如图21的公式,我们发现,在 pairwise 项和 unary 项里面,有一个共同的元素叫 k_j,就是 K 变化,它们是共享的。于是我们想说,是不是应该把它们给解耦开,使两项里面的 K 变化是独立的,所以就得到了下方的公式。

图21:另一个耦合的因素
我们发现把 K 变化解耦以后,学到的视觉线索更加清晰。我们看到右侧图的下方几乎是零了,但中间图的下方其实还有一些响应。同时,相关的系数也可以看到还有进一步的提升,从67.9提升到75.9,从65.7提升到69.6。
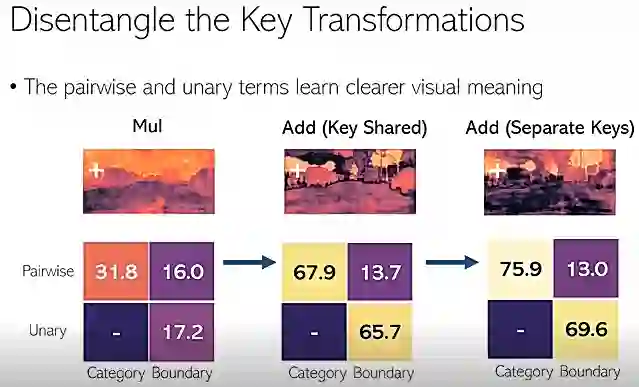
图22:K 变化解耦以后效果的提升
通过对标准的自注意模型做了改动,我们在语义分割的一个任务里面,总共带来了两个点的提升,从78.5提升到80.5。相比于自注意模型的基本网络,我们提升了近5个百分点,这是一个很显著的提升。

图23:改动标准的自注意模型后的效果提升
我们把这一方法叫做 Disentangled Non-Local Neural Networks,简称 DNL。我们在语义分割的3个数据集上面都做了实验,发现它相比于标准的自注意模型都有一个显著的提升。在 Cityscapes 提升了1.2点,在 PASCAL-Context 提升了4.5个点,在 ADE20K 提升了1.3个点。

同时这些模型也很通用,也能够去改进物体检测。图25中的第一个表格是把它应用到 COCO 物体检测里的一个例子,bbox 和这个 mask 都有1.3个点的提升。同时,把它应用在 Action recognition,基于 Kinetics 来做评测,它 Top-1 和 Top-5 都有0.4和0.5个提升。考虑到标准的 attention model,针对 baseline 提升相对很显著,几乎是100%。
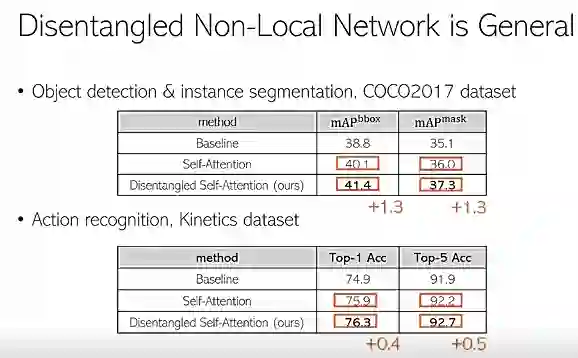
图25:在物体检测数据集上的实验结果
下面我们看一看在检测和动作识别里面,分别学到了什么样的一个特性。
图26是应用到物体检测里面的一个例子,左边是标准的模型,右边是我们的解耦模型。十字的框表示的是不同的 Query。可以看到左边的模型里面,对于不同的 Query,学到的 attention map 几乎是一样的。而在我们的模型里面,它表现会很不一样。例如 Query 点在人身上,那么对它有影响的这些像素,就主要是在前景里面,但 Query 像素是背景的时候,对它有影响的区域就主要是背景的区域。另外一些例子,也会有同样的性质,就是左边的 attention map 都长得很像,右边会根据 Query 的变化而变化。

图26:在物体检测上的实验结果
在动作识别里面,也能观察到同样的现象。图27中,我们每个视频都取了四帧放在一行,然后每一行代表不同的 Query 点。图中上部分是标准的模型,下半部分是解耦的模型。看位于图片下两行的例子,会发现不同的 Query 点对应的 attention map 长得很像,而在解耦模型里面,则会有一些跟 Query 有关的 attention map 出来,它会收到跟 Query 有关的一些性质。

图27:在动作识别上的实验结果
最后做一个简单的小结。在这次分享中,我们尝试着回答了2个问题。第一个是,在视觉任务里面,自注意模型有没有被学好?那我们的回答是,大部分其实没有学好。如果大家感兴趣可以去看我们去年的 GCNet 工作。第2个问题是,怎么样才能够有效地建模自注意模型?我们提出了一个解耦的设计,它可以更有效地学到建模这个制度与机制。
我们的代码已经开源了,如果感兴趣可以扫描二维码获取,他们分别是应用在语义分割和物体检测里的。同时,这个方法也在 mmsegmentation 里,欢迎大家试用和交流。

你也许还想看:








