视频中的时序关系推理(解决静态帧行为识别问题)
文章来源:Video Intelligence - 知乎专栏
行为识别有很多困难场景(hard example)需要应对:
1)复杂行为,涉及较多主体、客体或场景等
2)行为类别,反映的是前后时序产生的变化
3)行为持续时间有长有短,开始与结束结点很模糊
4)很难收集到包含足够多modality的large-scale数据集,这对于泛化的行为识别很困难。
5).......
本文主要解决第二个问题。
分析
视频中的行为识别,这个topic近来很火,做的人很多。一些主要数据集,比如UCF101, HMDB51,Sports-1M,THUMOS,还有刚发布的Kinetics等,都做得很不错。大部分方法是围绕Two-stream和C3D展开的。
1)Two-stream,即利用视频帧图像(spatial)以及根据帧图像通过无监督提取的光流场图像(Flow)来各自train一个模型,并在网络产生结果之后,对结果做一个后融合。这两个modality分别表示静态信息和短时序信息。
在这个思路上有很多杰出的工作,如Fusion-NN,TSN,salient area based, spatial-temporal bilinear pooling, temporal blinear encoding等能取得当时的SOTA。
2)C3D,比之C2D,多了一个时序上的密集采样 卷积,以此弥补Spatial modality上的短时序信息缺乏问题,虽然从整体结果来看,效果并不如two-stream fusion后的结果。
在这上面的尝试,有 I-3D, ResNet-3D, P-3D, non-local-3D 等等。
上面的方法基本可以很有效的解决从一张图就能识别出行为的类别,比如踢球,你看到运动员在踢球,那这肯定是在踢足球了,再加上光流信息的融合,概率就更高了(我们能知道踢的动作了)。但是这些方法都不能解决长时序问题,或者更具体的说: 如果这个行为是因为前后的时序变化而产生的,那么仅仅看单帧,或者短时序,是不能识别出这个类别的。比如人在叠被子,被子的变化很难通过单帧和短时序被CNN学习,只有看到叠被子前和叠被子后的变化,你才知道他在叠被子。这种情况对于真实场景非常常见, 不是一些小量数据集能反应出来的。
今天要分享的这篇论文 Temporal relation reasoning in videos 就是解决这个问题的(文后会总结效果)。(论文链接:https://arxiv.org/pdf/1711.08496.pdf)
Bolei Zhou 最近的paper,看样子像是投给了CVPR,前几天也开源了代码(链接:https://github.com/metalbubble/TRN-pytorch),代码整体框架是基于yuanjun xiong 的TSN。
他的做法可以简单的理解成改变了TSN的信息汇总的选举方式,感觉虽然是对temporal relation的一个研究,但结构简单,只限于每帧过完CNN后的feature以及选择MLP的结构做为关系的联接,应该说这个方向还有很大的空间。
先介绍下TSN。
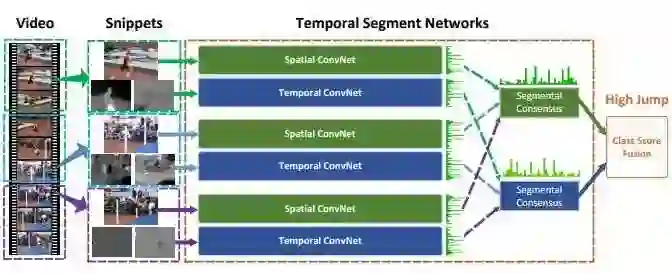
temporal segment networks, 针对于 trimmed videos,当然他们港中文后面又出了一篇针对untrimmed videos的文章。输入视频被(平均)分为N个segment,每个segment中随机采样一张frame,然后送入CNN。CNN之后,出现了N个frame的 feature map,然后Segmental-Consensus机制将对这些汇总的信息选举一个总的结果,在原论文和公开的代码里面,这个机制其实只用了简单的Max-pooling,average-pooling,或者top-k pooling。
TSN对于整段video的content representation很有效,一度在UCF101和HMDB上占据很长时间的SOTA。特别是加上强基础网络之后,比如Inception-V3 + Kinetics pretrain之后,又能将UCF101,THUMOS14等数据集刷新一遍。
TSN的网络结构天然的就可以做时序关系推理,存在以下问题需要先解决。
1.时序尺度不齐整。
不同的action 持续时间不一样,连帧信息在时间轴上的变化快慢也不一样,所以如果要进行关系推理,需要解决这个问题。Bolei的方案是增加到multi-scale的time range,对于输入视频,会分别计算N-relation,及(2,3,...,N-1)-relation的结果,作为整体来表示。
2.找到合适的数据集。
这篇文章需要解决的问题很有针对性,如果数据集不合适,可能很难超过baseline。Bolei选取了 Something-Something, Jester dataset, Charades 这三个dataset。后面在数据集部分会具体介绍。
下面开始梳理论文。
介绍

上图是文章首页的图,人可以从左图很轻松的推断出即将发生的事情,即这是人的关系推理能力,但是CNN看了左图后根本不会知道拉“罐瓶子摔下来”,“卷画帘”这样的行为。要让计算机认识这两个行为,需要两张及以上的帧图像来相互辅助识别。这就是时序关系推理,一个行为需要被多个帧协作来解释。
下图是framework。
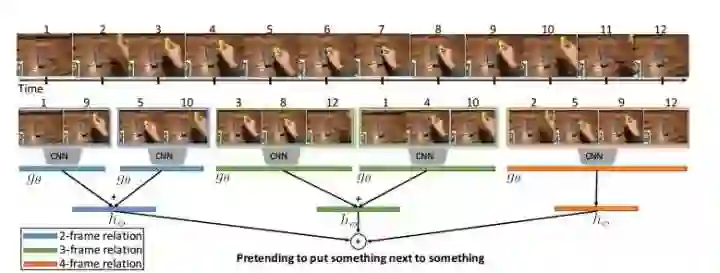
1~12号帧不一定是连续帧,这里需要强调,因为否则这和dense sampling差距并不大。
蓝色,绿色和橙色分别表示2帧关系,3帧关系,4帧关系。
图示是一个N=4的multi-scale time relation network,即2,3, 4 这三种关系网都包含。
看到这里,思路很清晰了。对于输入视频(其中的所有帧),不用通过密集采样,而是利用关系推理来采样关键帧。
具体做法就是基于TSN,过了一遍代码,思路很清晰流畅,我这里做一个具体的解释:
假设输入视频包含上图的12帧,我们要做一个N=4的multi-scale time relation network:
(a)先采样9帧,(编号分别为1,2,3,4,5,8,9,10,12)
(b)在9帧中排列采样4帧对儿,数量就是C4_9(排列)个4帧对儿。
(c)取n=N-1,N-2...,2,计算出(a)中排列采样出的n帧对儿。
(d)将以上的关系对儿各自过一遍CNN,或者说所有12帧过完CNN后,在特征上面再采样,一样的。
(e)对于不同的n都会得到一个帧对儿的特征集合。这些特征的信息会融合到一起,然后各个n的总结果再加在一起。
(a)-> (c)的采样步骤是Bolei在论文里提到的一个trick,这可以大大减小计算量。
This allows O(kN2) temporal relations to be sampled while evaluating the CNN on only N frames.
关系建模
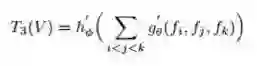
这是一个文中的3帧关系模型:输入视频V,Σ指在输入帧中排列采样3帧对儿,当然如果去掉了i<j<k后,就成了组合了:)
两个函数h,g,就是MLP的两层,fi,j,k在文中即帧通过CNN后的特征。
实验部分
数据集,论文中采用的3个数据集都是varying driven action,共同特点就是都很难从单帧中直接推出结果。
something-something 是一个human-object interaction recognition dataset, 共含有174类,分布在10万个视频中,其中一些比较模糊的类别非常有挑战性,比如“tearing something into two pieces” versus "tearing something just a little bit", "turn something upside down" versus "pretending to turn something upside down". 可以看出这个数据集的主要特点就是时序关系,目标变化来反映这个行为,而不是目标本身来决定。
Jester dataset 是一个手势识别的数据集,包含27类,分布在15万左右个视频中。如果看静态图像,每帧的主体内容就是手。而真实标记是由varying hand决定的。
charades是一个daily activity recognition dataset。都是一些室内的行为,比如把衣服放在椅子上等。157个类别分布在1万个左右的视频中。
一些实验如下,意料之中会比较有效。对比的baseline大都是基于单帧、光流(短时序)的。其实我很好奇如果用TSN做baseline的效果,因为TSN就是一个比较naive的关系融合网络。
刷新了charades的SOTA。
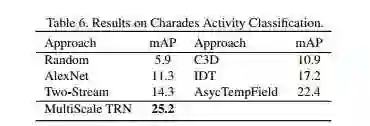
总的来说,这篇文章算是在时序关系推理上的一个新尝试,作者是受到了看图说话中关系网络的应用的启发(Inspired by the implementation of relation networks in image captioning)。
文章后面尝试和“生物学原理”产生共鸣,即用视觉常识来解释TRN的内部机理。
1)利用TRN来选择具有代表性的帧图像,并用之来识别activity。
2)通过实验证明时序顺序对行为识别非常敏感。
3)通过降维投影看到关系网络的作用,以及帧关系越长,对同类特征的聚类效果越好。
总结
当UCF101, Sports-1M, Kinetics等数据集做到差不多的时候,Charades,something-something等dataset会被行为识别方向推上台面重点研究,这篇文章比较像是TSN的一个升级版,从motivation引出框架,实验也比较充分,都取得了较好的效果。最后还用了人的视觉常识来解释。算是这个角度的一个开端吧。
- 文章推荐 -
加入极市Email List (http://extremevision.mikecrm.com/pdKKGSx),获取极市最新项目需求,以及前沿视觉资讯等。





