用Attention玩转CV,一文总览自注意力语义分割进展
机器之心专栏
作者:李夏
本文总结近两年语义分割领域对 attention 和“低秩”重建机制的探索,并介绍笔者被 ICCV 2019 接收为 Oral 的工作:Expectation-Maximization Attention Networks for Semantic Segmentation( 代码已开源: github.com/XiaLiPKU/EMANet )。 注: 本文中的 attention 仅指 self-attention,不涉及 soft-attention。
Attention 机制继在 NLP 领域取得主导地位[1]之后,近两年在 CV 领域也开始独领风骚。率先将之引入的是 Kaiming He 组的 Nonlocal[2]。此后层出不穷的文章,引发了一波研究 attention 机制的热潮。
仅2018年,在语义分割领域就有多篇高影响力文章出炉,如 PSANet[3],DANet[4],OCNet[5],CCNet[6],以及今年的Local Relation Net[7]。此外,针对 Attention 数学形式的优化,又衍生出A2Net[8],CGNL[9]。而 A2Net 又开启了本人称之为“低秩”重建的探索,同一时期的SGR[10],Beyonds Grids[11],GloRe[12],LatentGNN[13] 都可以此归类。
上述四文皆包含如下三步:1.像素到语义节点映射 2.语义节点间推理 3.节点向像素反映射。其中,step 2的意义尚未有对比实验验证,目前来看,step 1 & 3 构成的对像素特征的低秩重建发挥了关键作用。关于如何映射和反映射,又有了 APCNet[14] 和笔者的 EMANet[15] 等相关工作。
Nonlocal
Nonlocal[2]中的核心操作为:

其中 









关于

的形式,其中 



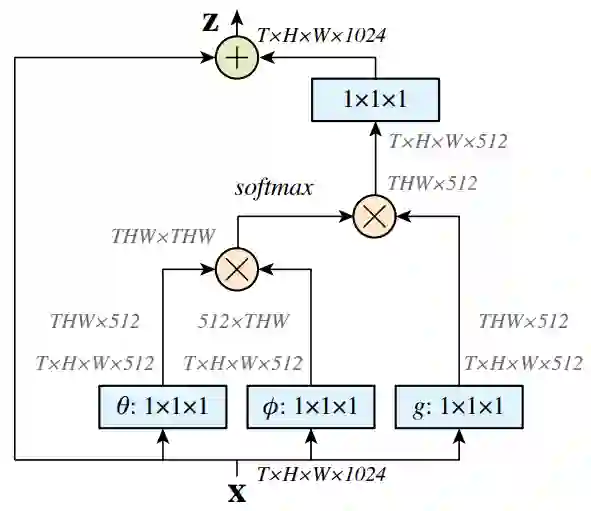
Non-local Block
其实,这里 
这里 
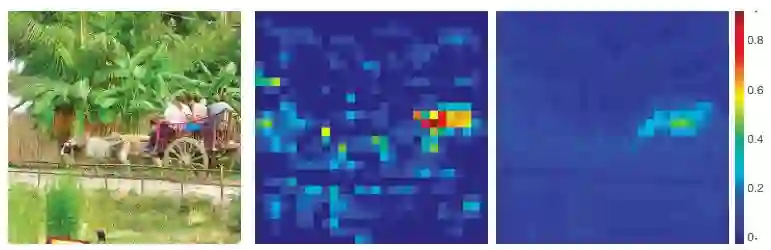
Other Attention Models
PSANet[3] 和 Nonlocal 最大的区别在于,相关度矩阵 


而 DANet[4],是把 Nonlocal 操作视为 spatial attention,以此引出了 channel attention ,两路融合。OCNet[5],则是将 object context (spatial attention) 和卷积强强联合,分别捕捉全局和局部信息,并在多个数据集上取得很高的精度。
Nonlocal 对于每个 



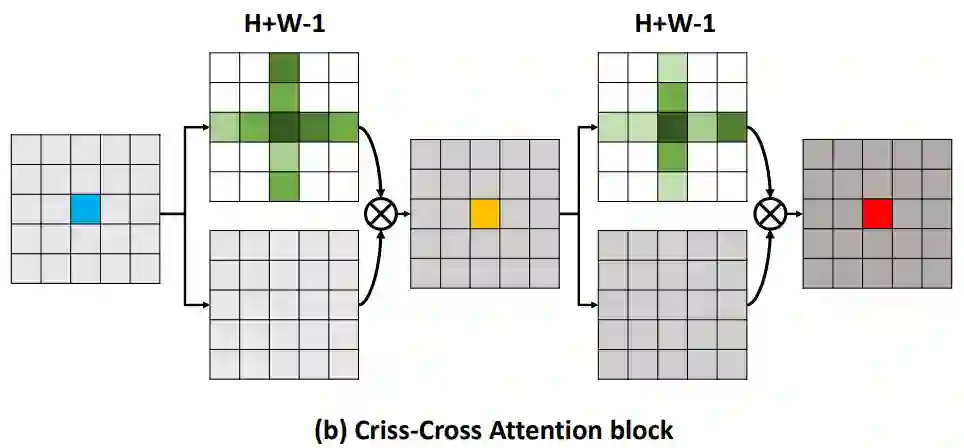
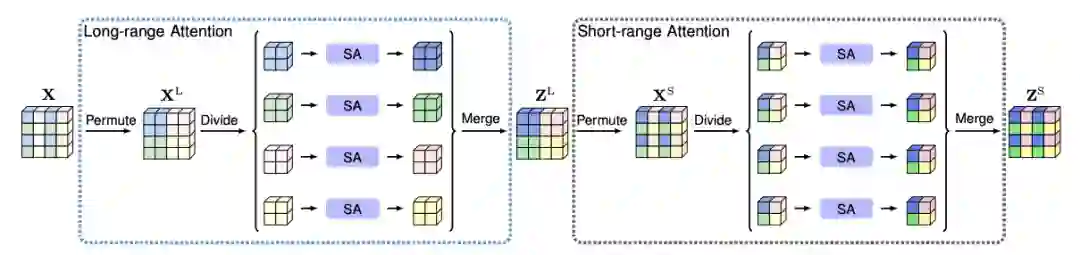
PKU兄弟实验室的 ISA[18]也是将 attention map 的全图计算分解为两步:第一步长距离attention ,第二步短距离。中间夹着一步 permute 操作。其实类似组卷积- shuffle -组卷积的过程,思路上顺承 IGCV[19],其复杂度也是
Oxford的DGMN[20]则通过MC采样,使每个像素计算attention所需的参考像素从 



另一种减少计算量的方法,是将 attention 的全图计算改为窗口内计算。MeanShift 若限制窗口大小,便是 Bilateral Filter,即每个像素的特征,更新为邻域内其他像素的加权平均。权重由特征相似度和空间距离计算而来。而 MeanShift 也被证明等价于迭代至收敛的Bilateral Filter[21]。
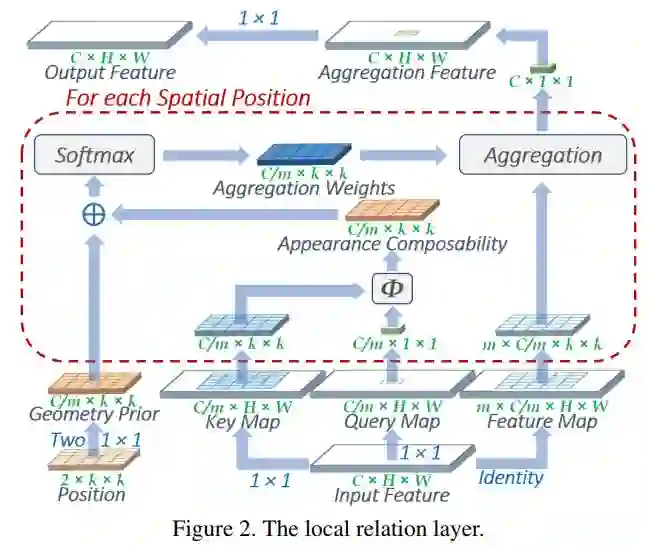
MSRA 的 Local Relation Net[7]设计了类似 Bilateral Filter 的操作,在特征相关度计算上使用了标准的 query,key,value 三元组,在空间相关度上设计了Geometry Prior。并且大胆地用这一算子替代了 
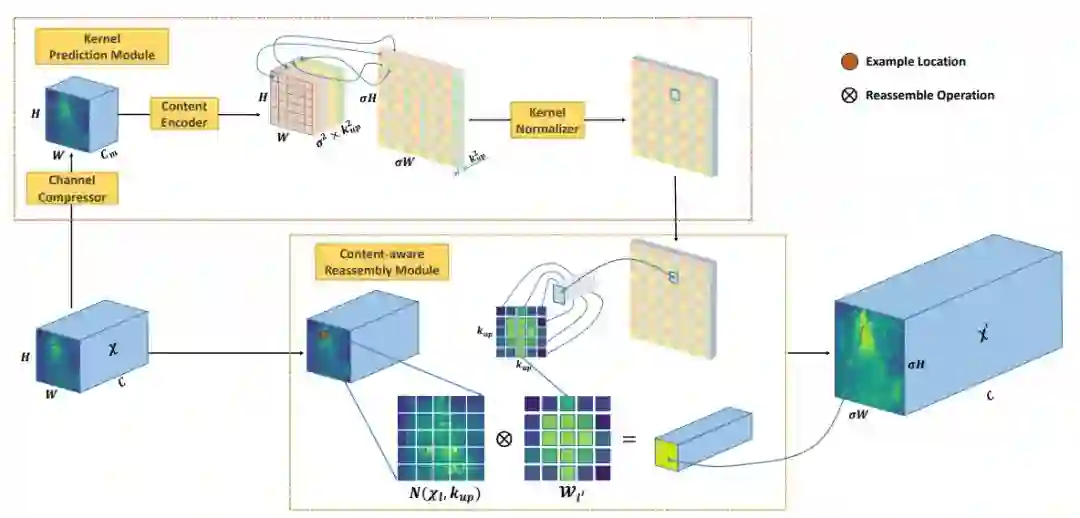
MMLab 的 CARAFE[22],用来进行特征上采样。其计算方式也是用窗口内像素特征的特征加权平均。其特殊之处在于,用于加权的权重是学习出来的,通过对特征变换、pixelshuffle上采样和通道归一化得到。
其实关于选择 global 还是 local 的问题,NLP 领域已经有好多研究,详见苏剑林的博文 《为节约而生:从标准Attention到稀疏Attention》。两个领域的研究,其实都在做类似的事情。
注释:本节所提及文章各有其出发点和独到之处,这里仅简单统一到一个框架下,并总结共通点。具体分析未免有缺失和差池,各文章精妙之处,还需参考其他博文。
A2Net and CGNL
NUS 的 A2Net[8] 和 百度的 CGNL[9] 另辟蹊径,从另一个角度优化了 Nonlocal 的复杂度。
Nonlocal 高昂的复杂度

其中 






由于 




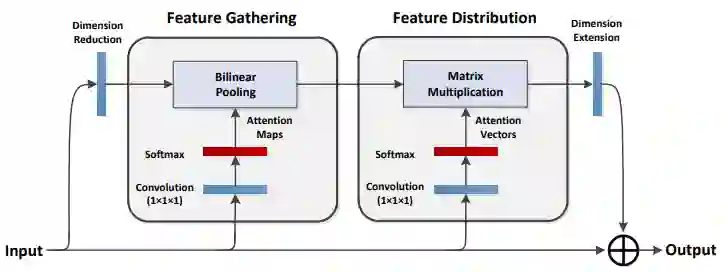
那么,如何从直觉上理解公式 (4) 呢? 



GloRe and so on
在 A2Net 基础上,Yunpeng Chen 继续做出了 GloRe[12]。相比于 A2Net,GloRe 在映射 (



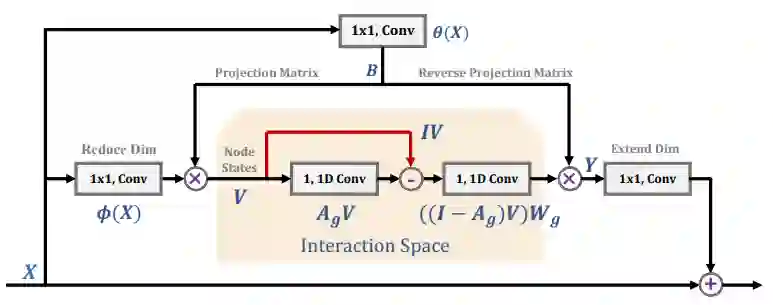
其实,和 GloRe 同一时期的相关工作还有 SGR[10], Beyonds Grids[11] 和 LatenGNN[13]。它们都采取三步走的策略,即映射、GCN 和反映射。他们的区别在于每一步的具体操作。
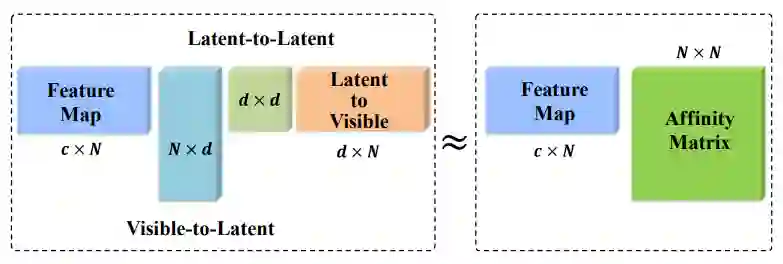
四篇文章在 GCN 步骤各有设计。不过,目前为止,没有看到任何公开的 ablation study 证明第二步 GCN 有效果,自己复现的部分实验,也没有跑出 GCN 有增益的结果。所以,只能暂且认为关键还是在于映射和反映射。
那么,映射和反映射,为何能表现突出呢?这里只说一下自己对语义分割这个任务的分析。我们用来抽取 Feature 用的 ResNet,在 ImageNet 千类数据集上训练,因此特征维度至少 1000 维。而分割问题少则 20 类左右,多也不超过几百类。使用过千维的特征,显然是过参数化了。
对高维数据分类是低效的,因为高维空间中分类边界过于复杂。而映射反映射的流程,其实是对特征的一个低秩重构,使得高维空间中的特征重新分布到低维流形上,便于后续的分类。其实,A2Net 在 ImageNet 上也证明了自己的价值,这说明不只是分割问题合适,类似的一系列任务,都适用这种映射-反映射模块。
上述的几篇文章,映射和反映射矩阵,多是通过
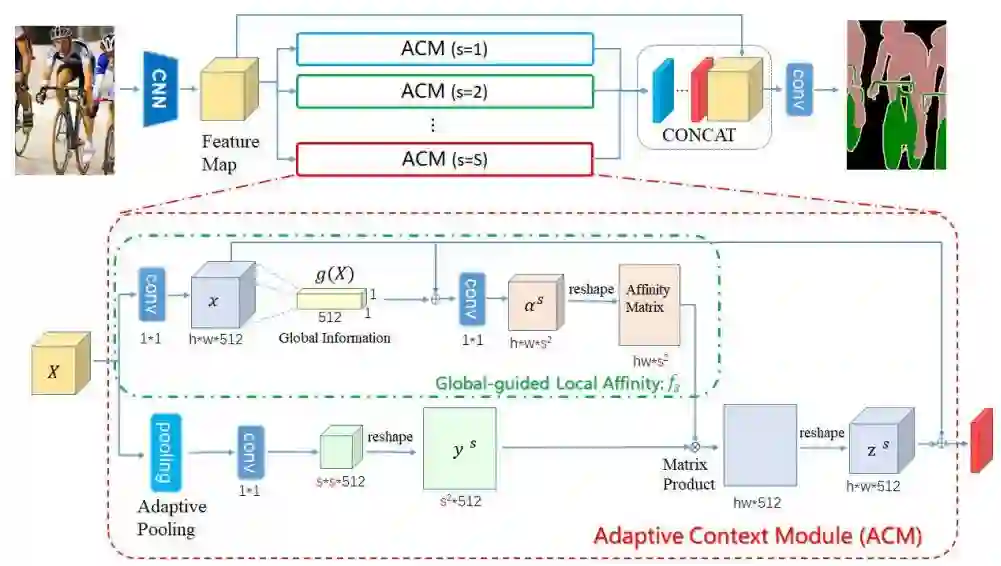
EMANet
本文认为,映射的关键,在于寻找一组“最合适”的描述子,即论文中的“基”。这组基最好具有如下的几条性质:1. 具有代表性 2. 数量少 3. 互不相似。性质1能保证重构后的 feature map 能够最大限度地还原有效信息;性质2则可以保证重构的低秩性,使重构后的特征处在高维空间中的低维流形中;性质3则是在性质2的约束下,尽可能达到性质1的保证。使用池化,即简单下采样的,得到的基充分满足性质2;但互相之间仍十分相似,因此性质3不满足;小物体下采样后可能会信息丢失,因此性质1也仅仅能对大物体满足。
笔者被ICCV 2019收录为Oral的论文 EMANet[23],提出了用 EM 算法来求解映射和反映射。EM 算法用于求解隐变量模型的最大似然解。这里把隐变量视为映射矩阵,模型参数即为 


EM 本身保证收敛到似然函数的局部最大值,因此 EM 算法迭代而出的描述子和映射关系,相对于简单地用网络学习到的,更能保证满足性质1;性质2可以通过设置较小的
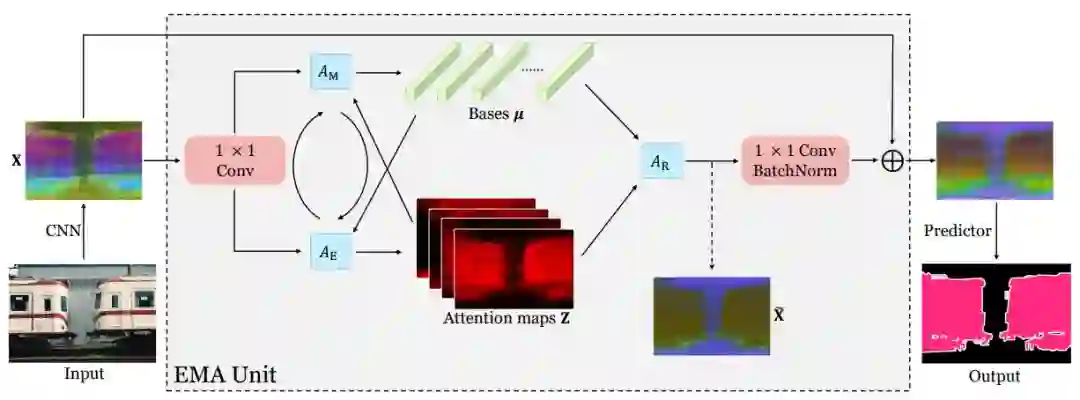
此处,我们可以考虑下 EMANet 和 A2Net 的关联。将公式(4)摘抄下来:

如果我们将其中的 




总结
本文抛开 glocal context 的观点,重新从传统算法的角度出发,对上述文章作了重新的思考总结。回顾而来,所谓最新的成果,不过是站在了先贤的肩膀上,在深度学习的形式上进行了探索。追本溯源,笔者本人也不过是经典算法 EM 的搬运工。借此,向鼎力帮助我的三位师兄(Zhisheng Zhong,Jianlong Wu和Yibo Yang)和两位导师(Zhouchen Lin, Hong Liu)致敬。
感谢Qijie、大大拉头的仔细审稿。还要感谢《EM 算法的九层境界》的作者史博和科学空间苏剑林,他们的博文对我有很大的启发。
参考
Attention is All You Need https://arxiv.org/abs/1706.03762
Non-local Neural Networks https://arxiv.org/pdf/1711.07971.pdf
PSANet: Point-wise Spatial Attention Network for Scene Parsing https://hszhao.github.io/papers/eccv18_psanet.pdf
Dual Attention Network for Scene Segmentation https://arxiv.org/abs/1809.02983
OCNet: Object Context Network for Scene Parsing https://arxiv.org/abs/1809.00916
CCNet: Criss-Cross Attention for Semantic Segmentation https://arxiv.org/abs/1811.11721
Local Relation Networks for Image Recognition https://arxiv.org/abs/1904.11491
A2 -Nets: Double Attention Networks https://papers.nips.cc/paper/7318-a2-nets-double-attention-networks.pdf
Compact Generalized Non-local Network https://arxiv.org/abs/1810.13125
Symbolic Graph Reasoning Meets Convolutions https://pdfs.semanticscholar.org/4959/7c2c8d65f4d3b817aabfa31f16f3791be974.pdf
Beyond Grids: Learning Graph Representations for Visual Recognition https://www.biostat.wisc.edu/~yli/preprints/yin_nips2018_camera_ready.pdf
Graph-Based Global Reasoning Networks http://openaccess.thecvf.com/content_CVPR_2019/papers/Chen_Graph-Based_Global_Reasoning_Networks_CVPR_2019_paper.pdf
LatentGNN: Learning Efficient Non-local Relations for Visual Recognition https://arxiv.org/abs/1905.11634
Adaptive Pyramid Context Network for Semantic Segmentation http://openaccess.thecvf.com/content_CVPR_2019/papers/He_Adaptive_Pyramid_Context_Network_for_Semantic_Segmentation_CVPR_2019_paper.pdf
Expectation-Maximization Attention Networks for Semantic Segmentation https://arxiv.org/abs/1907.13426
An Empirical Study of Spatial Attention Mechanisms in Deep Networks https://arxiv.org/abs/1904.05873
Feature Denoising for Improving Adversarial Robustness https://arxiv.org/abs/1812.03411
Interlaced Sparse Self-Attention for Semantic Segmentation https://arxiv.org/abs/1907.12273
Interleaved Group Convolutions for Deep Neural Networks https://arxiv.org/abs/1707.02725
Dynamic Graph Message Passing Networks https://arxiv.org/abs/1908.06955
A General Framework for Bilateral and Mean Shift Filtering https://people.csail.mit.edu/jsolomon/assets/MeshBilateral.pdf
CARAFE: Content-Aware ReAssembly of FEatures https://arxiv.org/abs/1905.02188
Expectation Maximization Attention Networks for Semantic Segmentation https://xialipku.github.io/publication/expectation-maximization-attention-networks-for-semantic-segmentation/


