微软亚研:对深度神经网络中空间注意力机制的经验性研究
机器之心专栏
来源:微软亚洲研究院
作者:朱锡洲、程大治、张拯、Stephen Lin(林思德)、代季峰
空间注意力(Spatial Attention)机制最近在深度神经网络中取得了很大的成功和广泛的应用,但是对空间注意力机制本身的理解和分析匮乏。
论文:An Empirical Study of Spatial Attention Mechanisms in Deep Networks
链接:https://arxiv.org/abs/1904.05873
摘要:空间注意力(Spatial Attention)机制最近在深度神经网络中取得了很大的成功和广泛的应用,但是对空间注意力机制本身的理解和分析匮乏。本论文对空间注意力机制进行了详尽的经验性分析,取得了更深入的理解,有些认知是跟之前的理解很不一样的,例如,作者们发现 TransformerAttention 中对 query 和 key 的内容进行比较对于空间注意力帮助很小,但对于 Encoder-Decoder Attention(编码器-解码器注意力)是至关重要的。另一方面,将可变形卷积(DeformableConvolution)与和 query 无关的 key saliency 进行适当组合可以在空间注意力中实现最佳的准确性-效率之间的权衡。本论文的研究结果表明,空间注意力机制的设计存在很大的改进空间。
引言

图 1. 不同的注意力因子的描述。采样点上方的颜色条表示其内容特征。当图中存在内容特征或相对位置时,表明该项将它们用于注意力权重计算。
注意力机制使神经网络能够更多地关注输入中的相关部分。自然语言处理(NLP)中最先研究了注意力机制,并开发了 Encoder-Decoder 模块以帮助神经机器翻译(NMT),当给定一个 query(例如,输出句子中的目标词),计算其输出时,会依据 query 对某些 key 元素(例如,输入句子中的源词)进行优先级排序。后来空间注意力模块被提出,用于建模句子内部的关系,此时 query 和 key 都来自同一组元素。重磅论文 Attention is All You Need 中提出了 TransformerAttention 模块,大大超越了过去的注意力模块。注意力建模在 NLP 中的成功,激发了其在计算机视觉领域中的应用,其中 Transformer Attention 的不同变体被应用于物体检测和语义分割等识别任务,此时 query 和 key 是视觉元素(例如,图像中的像素或感兴趣的区域)。
在给定 query,确定分配给某个 key 的注意力权重时,通常会考虑输入的三种特征:(1)query 的内容特征,可以是图像中给定像素的特征,或句子中给定单词的特征;(2)key 的内容特征,可以是 query 邻域内像素的特征,或者句子中的另一个单词的特征;(3)query 和 key 的相对位置。
基于这些输入特征,在计算某对 query-key 的注意力权重时,存在四个可能的注意力因子:(E1)query 内容特征和 key 内容特征;(E2)query 内容特征和 query-key 相对位置;(E3)仅 key 内容内容特征;(E4)仅 query-key 相对位置。在 Transformer Attention 的最新版本 Transformer-XL 中,注意力权重表示为四项(E1,E2,E3,E4)的总和,如图 1 所示。这些项依赖的属性有所区别。例如,前两个(E1,E2)对 query 内容敏感。而后两者(E3,E4)不考虑 query 内容,E3 主要描述显著的 key 元素,E4 主要描述内容无关的的位置偏差。尽管注意力权重可以基于这些因子被分解,但是这些因子之间的相对重要性尚未被仔细研究。此外,诸如可变形卷积和动态卷积(Dynamic Convolution)之类的流行模块虽然看起来与 Transformer Attention 无关,但也采用了关注输入的某些相关部分的机制。是否可以从统一的角度看待这些模块以及它们的运行机制如何不同等问题也未被探索过。
这项工作将 Transformer Attention,可变形卷积和动态卷积视为空间注意力的不同实例(以不同注意力机制,涉及了注意力因子的不同子集)。为分析不同注意力机制和因子的影响,本文在广义注意力形式下对比了不同的注意力机制的各种因素,该调查基于多种应用,包括神经机器翻译,语义分割和物体检测。本研究发现:(1)在 Transformer Attention 模块中,对 query 敏感的项,尤其是 query 和 key 内容项 E1,在 Self Attention(自注意力)中起着微不足道的作用。但在 Encoder-Decoder Attention 中,query 和 key 内容项 E1 至关重要;(2)尽管可变形卷积仅利用基于 query 内容和相对位置项的注意力机制,但它在图像识别方面比在 Transformer Attention 中对应的项 E2 更有效且高效;(3)在 Self Attention 中,query 内容和相对位置项 E2 以及仅考虑 key 内容的项 E3 是最重要的。将可变形卷积与 Transformer Attention 中仅考虑 key 内容的项 E3 进行适当组合会提供比 Transformer Attention 模块更高的精度,且在图像识别任务上具有低得多的计算开销。
本文中的观察挑战了对当前空间注意力机制的传统理解。例如,人们普遍认为,注意力机制的成功主要归功于对 query 敏感的注意力项 E1 和 E2,尤其是 query 和 key 内容项 E1。这种理解可能源于最开始 Encoder-Decoder Attention 模块在神经机器翻译中的成功。事实上,在最近的一些变体,如 Non-Local 模块和 Criss-Cross 模块中,仅有 query 和 key 内容项 E1 得到保留,所有其他项都被丢弃。这些模块在 Self Attention 应用中仍能很好地发挥作用,进而增强了这种理解。但是本文的研究表明这种理解是不正确的。本文发现这些仅具有 query 敏感项的注意力模块实际上与那些仅具有 query 无关项的注意力模块性能相当。本文的研究进一步表明,这种退化可能是源于注意力模块的设计,而不是 Self Attention 的固有特征,因为可变形卷积被发现在图像识别任务中能有效且高效地利用 query 内容和相对位置。
这一实证分析表明,深度网络中空间注意力机制的设计还有很大的改进空间。本文的研究结果在这个方向上取得了一些初步进展,希望这项研究能够激发关于建模空间注意力中的运行机制的进一步研究。
广义注意力形式
给定 query 元素和一组 key 元素,注意力函数根据注意力权重对 key 内容进行相应的聚合,其中注意力权重衡量了 query-key 的兼容性。为了允许模型处理来自不同特征子空间和不同位置的 key 内容,多个注意力函数的输出依照一组可学习的权重进行线性组合。令 q 索引某内容特征为 z_q 的 query 元素,并且 k 索引具有内容特征 x_k 的 key 元素,最终输出的注意力特征 y_q 被计算为:
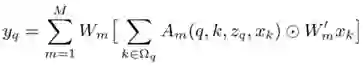
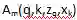
在这个广义注意力形式下,Transformer Attention 与可变形卷积、动态卷积的区别在如何计算
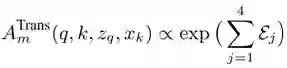
而可变形卷积的计算形式为(G 为双线性插值函数):
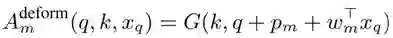
动态卷积也可以在进行微小修改后纳入广义注意力形式,详见论文。
Transformer Attention 中各项因子的对比
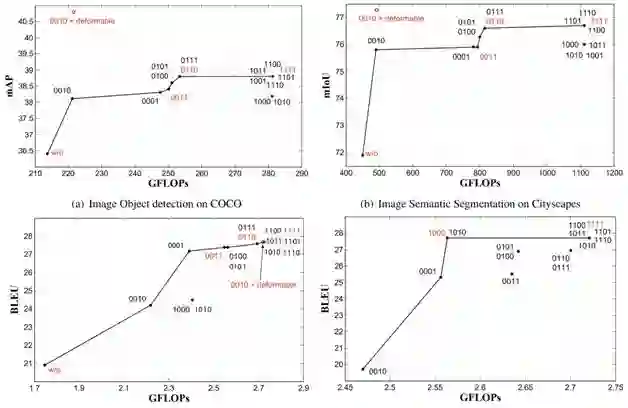
图 2.TransformerAttention 中四项的准确性–效率权衡(E1 对应 key 和 query 内容,E2 对应 query 内容和相对位置,E3 对应于仅考虑 key 内容,E4 对应于仅考虑相对位置)。这里数字对应着每项是否被激活(例如,0011 表示 E3 和 E4 被激活,w/o 表示不采用 TransformerAttention)。由于 Encoder-Decoder Attention 机制对于 NMT 是必不可少的,因此(d)中没有 w/o 设置。一些配置的结果在图中重叠,因为它们具有相同的精度和计算开销。研究中的关键配置以红色突出显示。图中还画出了本文中 Self Attention 的推荐配置「“0010 +可变形卷积”」。
(1)在 Self Attention 中,与和 query 无关项相比,query 敏感项起着很小的作用。特别是 query 和 key 内容项,该项对准确性的影响可忽略不计,而在图像识别任务中计算量很大。总的来说,Transformer Attention 模块带来的精度提升很大(从不带 Transformer Attention 模块的配置(「“w / o”」)到使用完整版 Transformer 注意力的配置(「“1111”」))。其中,query 无关项(从配置「“w / o”」到「“0011”」)带来的收益比 query 敏感项(从配置「“0011”」到「“1111”」)带来的收益大得多。特别地,query 和 key 内容项 E1 带来的性能增益可以忽略不计。删除它(从配置「“1111”」到「“0111”」)只会导致精度微弱下降,但能大大减少图像识别任务中的计算开销。
(2)在 Encoder-Decoder Attention 中,query 和 key 内容项是至关重要的。如果不用 E1 会导致精度明显下降,而仅使用配置「“1000”「提供的精度几乎与完整版本(配置「“1111”」)相同。这是因为 NMT 的关键步骤是对齐源语句和目标语句中的单词。遍历 query 和 key 内容对于这种对齐是必不可少的。
(3)在 Self Attention 中,query 内容及相对位置的项 E2 和仅有 key 内容项 E3 是最重要的。相应的配置「“0110”」提供的精度非常接近完整版(配置「“1111”」),同时在图像识别任务中节省了大量的计算开销。还值得注意的是,捕获显著性信息的仅有 key 内容项 E3 可以有效地提高性能,而几乎没有额外的开销。
本文的研究结果与人们普遍认知相反,尤其是人们认为 query 敏感项,特别是 query 和 key 内容项对于 Transformer Attention 的成功至关重要。实验结果表明,这仅适用于 Encoder-Decoder Attention 场景。在 Self Attention 场景中,query 和 k_ey 内容项甚至可以删除。
可变形卷积和 Transformer Attention 中 E_2 的对比
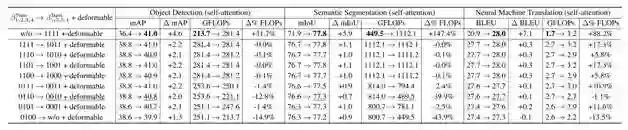
图 3. 可变形卷积和 Transformer Attention 中 E_2 的对比
(1)对于目标检测和语义分割,可变形卷积在准确性和效率上都大大超过 E2 项。对于 NMT,可变形卷积在准确性和效率方面与 E2 项相当。在效率方面,可变形卷积不需要遍历所有关键元素。这种优势在图像上是显而易见的,因为涉及许多像素。在准确性方面,可变形卷积中的双线性插值基于特征图的局部线性假设。这种假设在图像上比在语言上更好,因为图像局部内容变化很缓慢,但语言中单词会发生突然变化。
(2)可变形卷积与仅有 Key 内容项(「“0010 +可变形卷积”」)的组合提供了最佳的准确性 - 效率权衡。其准确性与使用可变形卷积和完整的 TransformerAttention 模块(「“1111 +可变形卷积”」)相当,计算开销略高于仅有可变形卷积的开销(「“w/o +可变形卷积”」)。
动态卷积和 Transformer Attention 中 E_2 的对比

图 4. 动态卷积和 Transformer Attention 中 E_2 的对比。二者都利用了 query 的内容信息和相对位置。在表的后四行中,E_2 的空间范围也被限制到了一个固定大小,以进一步揭示其和动态卷积的区别。
(1)在机器翻译中,动态卷积和 Transformer Attention 的 E_2 项性能相当,且动态卷积计算量较低。但在物体检测和语义分割中,动态卷积比 E_2 性能显著下降。
(2)在对 E_2 限制空间范围与动态卷积和卷积核一致后,随着卷积核缩小,动态卷积和 Transformer Attention E_2 的性能都有所下降,但是 E_2 还是比动态卷积性能好且计算量更低。动态卷积在图片识别任务上表现欠佳的可能原因是该模块的许多细节是为了机器翻译设计的,可能不适用于图像识别任务。
本文为机器之心专栏文章,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



