Meta实习生让AI「调教」AI?ResNet-50无需训练,2400万参数秒级预测
![]()
新智元报道

新智元报道
编辑:好困 拉燕
【新智元导读】10年前,当我们有了足够的数据和处理能力,深度神经网络也就实现了对传统算法的超越。今天,神经网络对数据和算力更加饥渴,甚至需要微调数百万甚至数十亿的参数来进行训练。不过,这种情况或许很快就会改变。

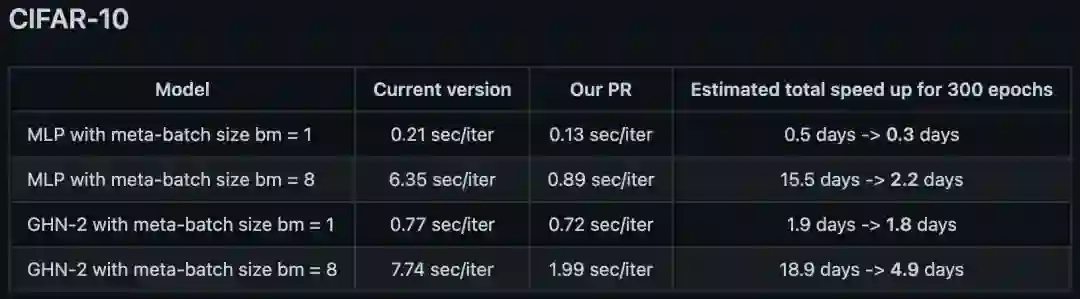
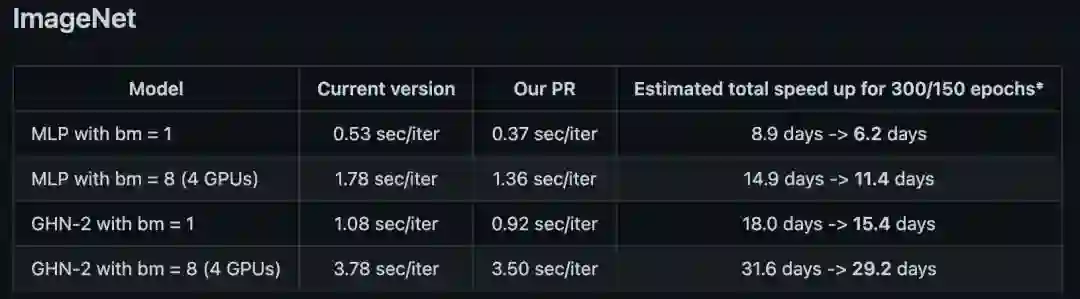
训练AI的AI训练师
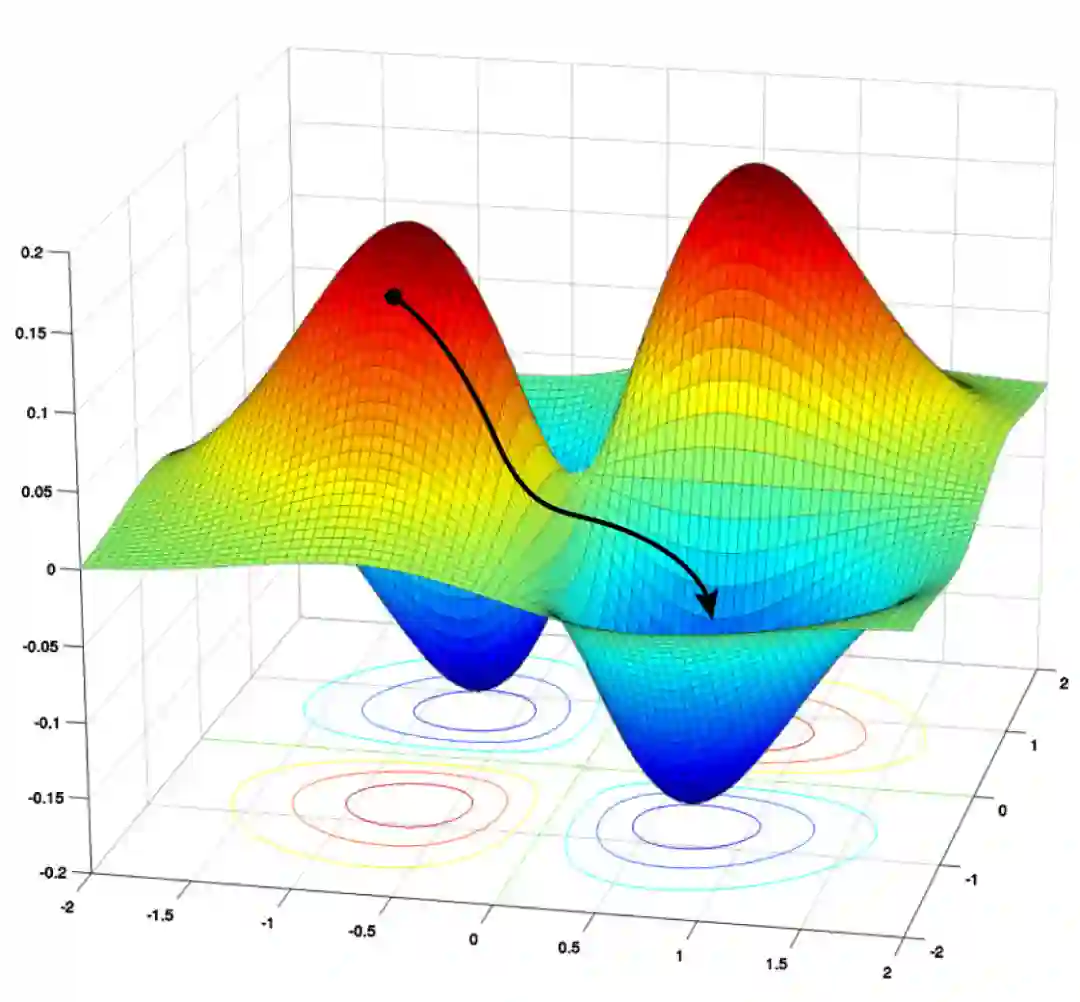

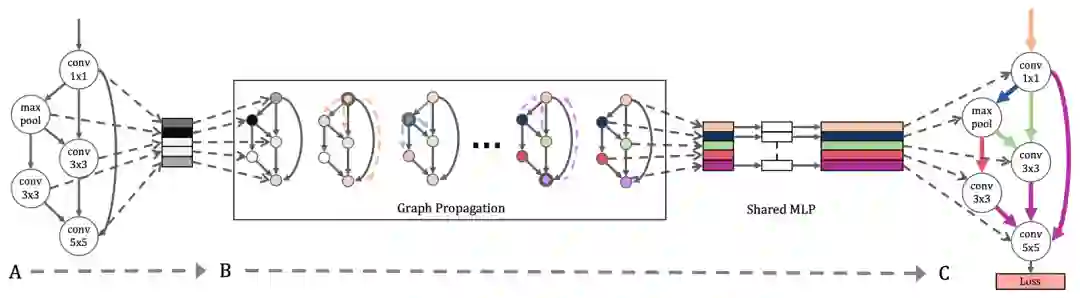

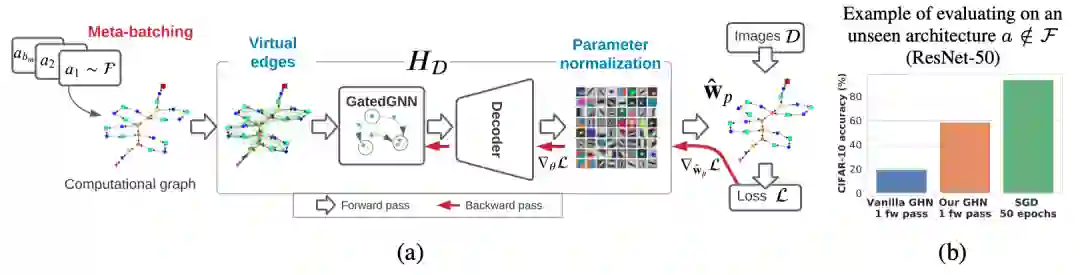
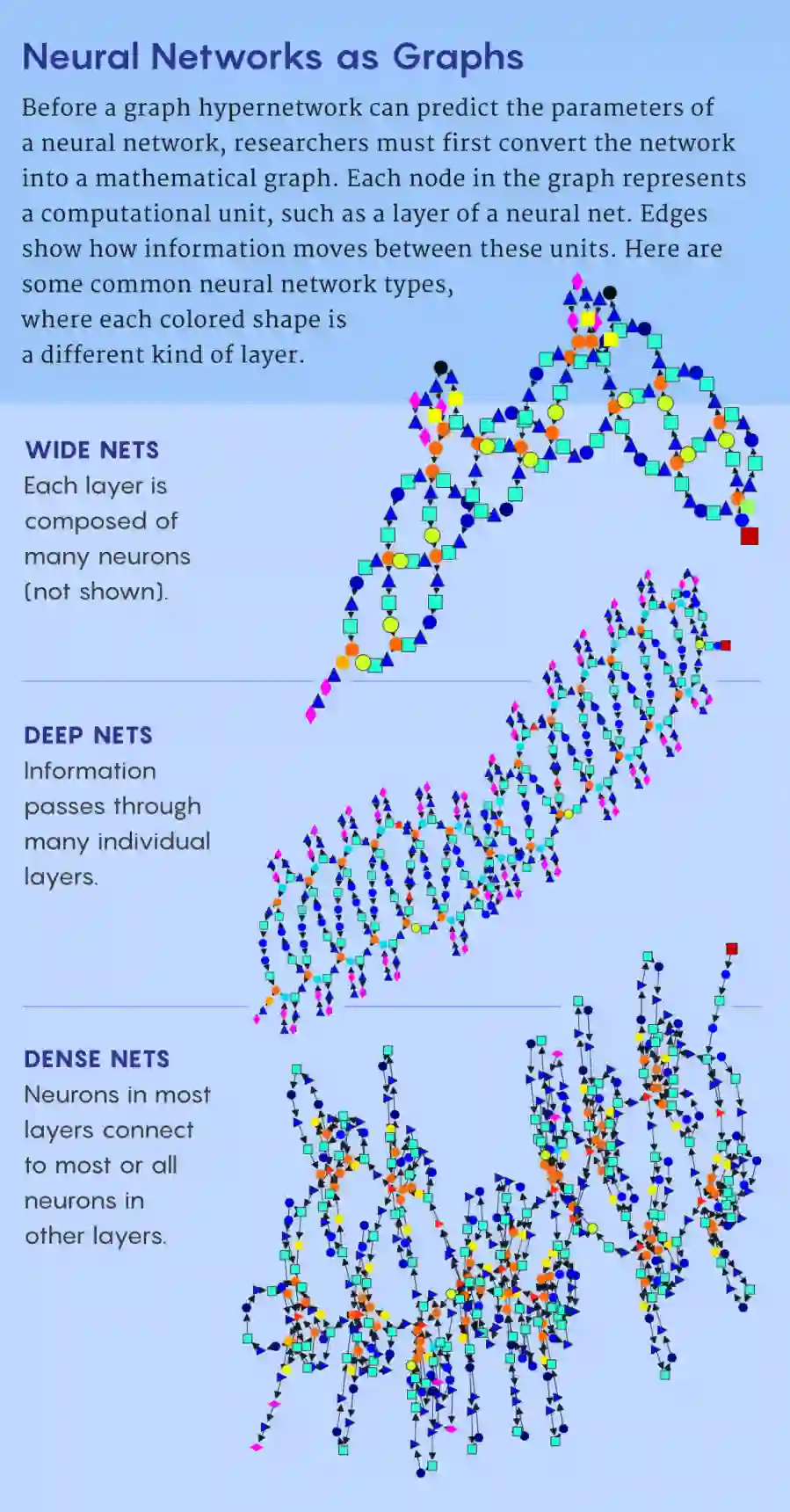
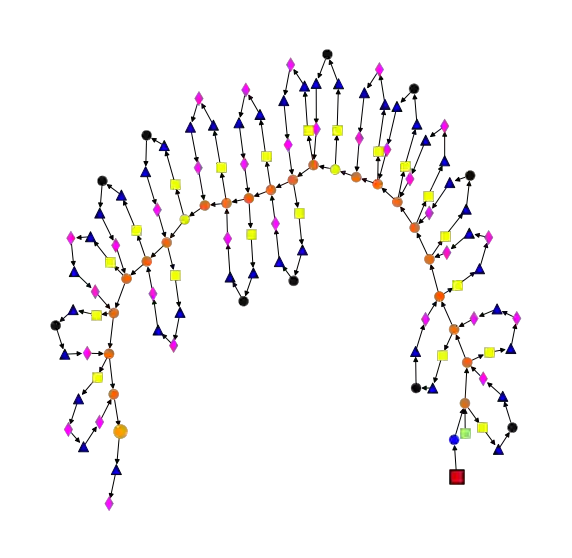
比SGD更好用?
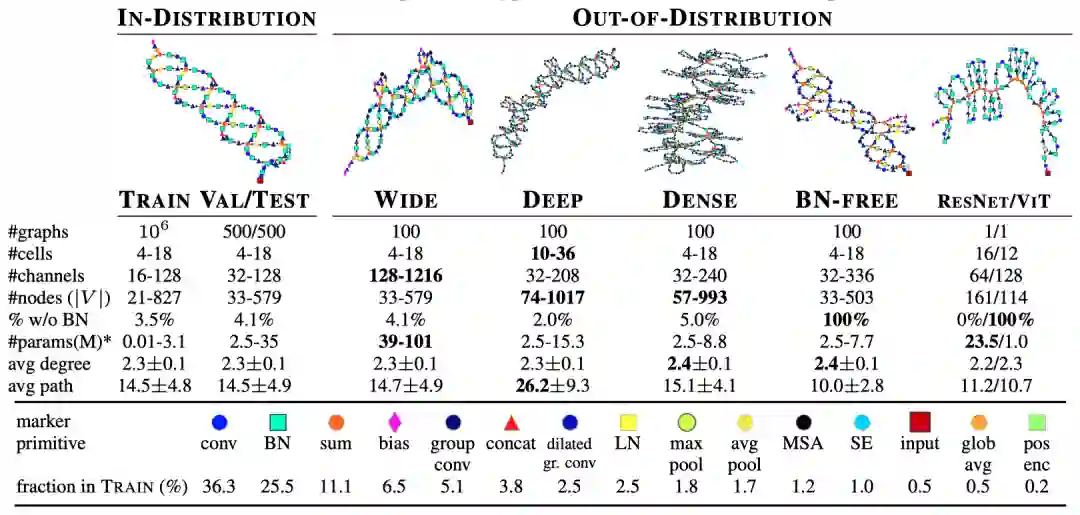
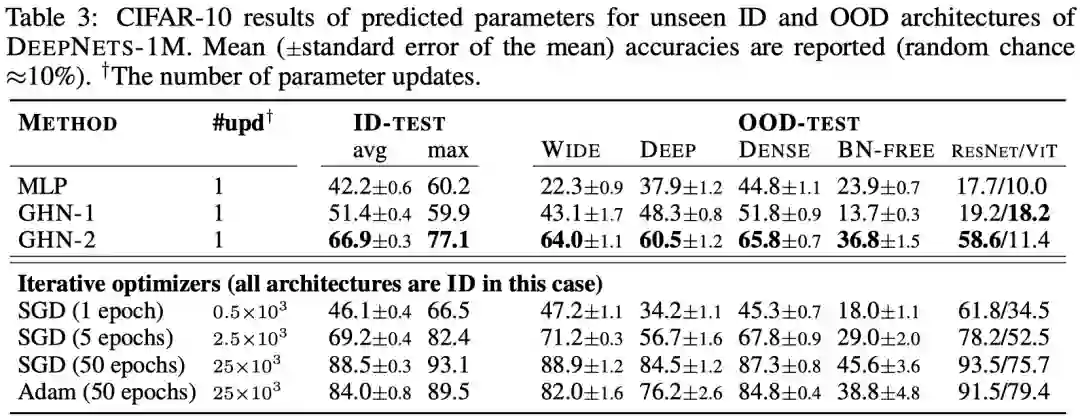
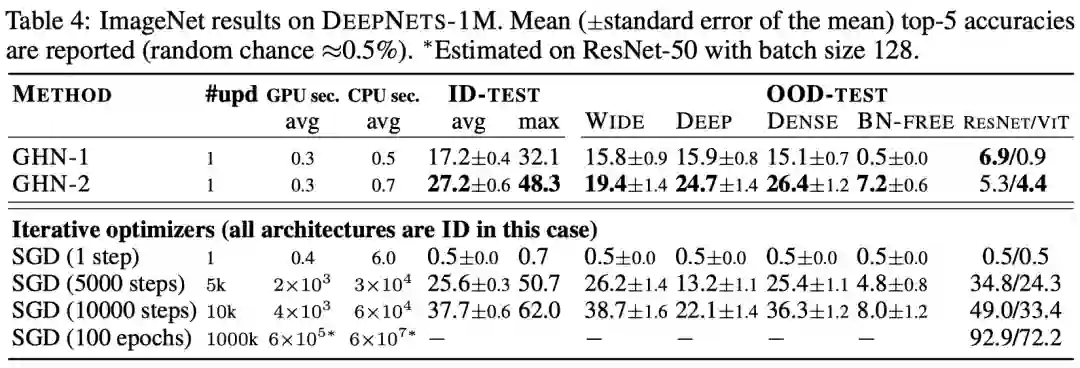
超网络的未来——在GHN-2之后
参考资料:

登录查看更多
相关内容

人工神经网络(Artificial Neural Network,即ANN ),是20世纪80 年代以来人工智能领域兴起的研究热点。它从信息处理角度对人脑神经元网络进行抽象, 建立某种简单模型,按不同的连接方式组成不同的网络。在工程与学术界也常直接简称为神经网络或类神经网络。神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
最近十多年来,人工神经网络的研究工作不断深入,已经取得了很大的进展,其在模式识别、智能机器人、自动控制、预测估计、生物、医学、经济等领域已成功地解决了许多现代计算机难以解决的实际问题,表现出了良好的智能特性。
专知会员服务
17+阅读 · 2019年11月17日
Arxiv
0+阅读 · 2022年4月20日


相关VIP内容
专知会员服务
17+阅读 · 2019年11月17日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月20日