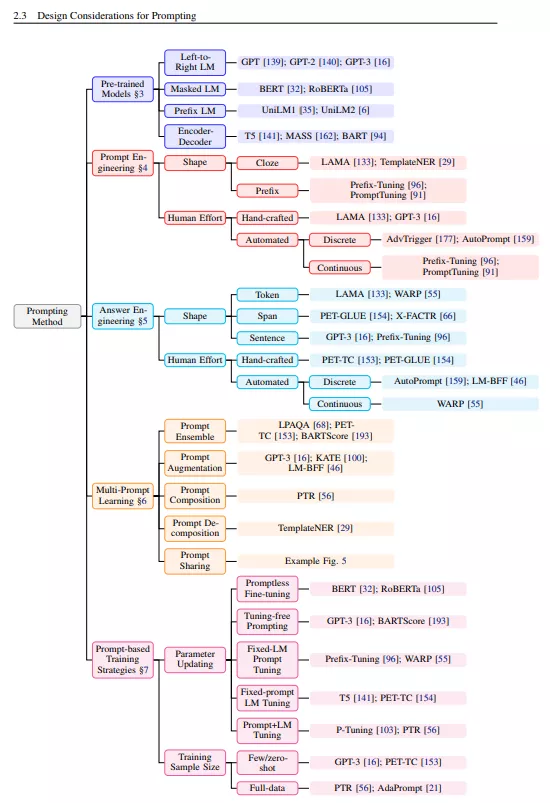
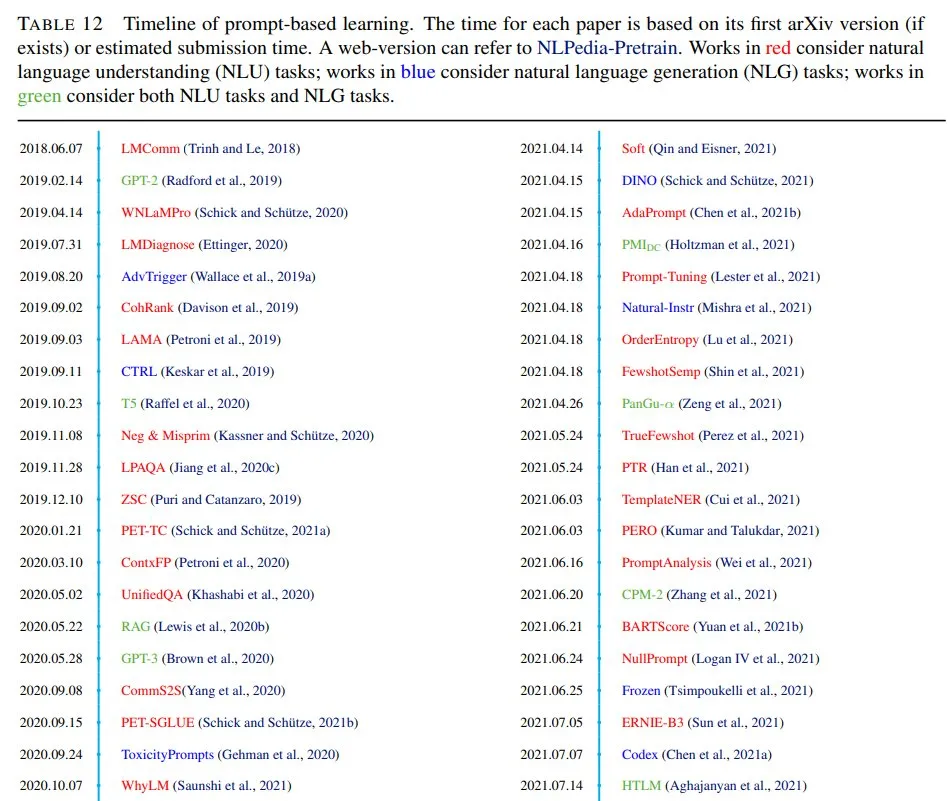
本文综述并组织了自然语言处理新范式——“基于提示的学习”的研究工作。与传统的监督学习不同的是,基于提示的学习是基于直接对文本概率建模的语言模型,监督学习训练模型接收输入x并预测输出y为P(y|x)。为了使用这些模型执行预测任务,使用模板将原始输入x修改为文本字符串提示符x ',其中有一些未填充的槽,然后使用语言模型按概率填充未填充的信息,得到最终字符串xˆ,从中可以导出最终输出y。这个框架的强大和吸引人的原因有很多: 它允许语言模型在大量的原始文本上进行预先训练,通过定义一个新的提示函数,模型能够执行少量甚至零次学习,在很少或没有标记数据的情况下适应新的场景。本文介绍了这一有希望的范例的基本内容,描述了一套统一的数学符号,可以涵盖各种各样的现有工作,并从几个维度组织现有的工作,例如预先训练的模型、提示和调优策略的选择。为了让有兴趣的初学者更容易理解这个领域,我们不仅对现有的工作进行了系统的回顾,并对基于提示的概念进行了高度结构化的类型化,而且还发布了其他资源。
地址: https://www.zhuanzhi.ai/paper/51f9620d879bb5b2dde5437372c97f5b
完全监督学习,即仅在目标任务的输入输出示例数据集上训练特定任务模型,长期以来在许多机器学习任务中发挥着核心作用(Kotsiantis et al., 2007),自然语言处理(NLP)也不例外。由于这种完全监督的数据集对于学习高质量的模型一直是不够的,早期的NLP模型严重依赖特征工程(Tab. 1 a.; e.g. Lafferty et al. (2001); Guyon et al. (2002); Och et al. (2004); Zhang and Nivre (2011)),其中,NLP研究人员或工程师利用他们的领域知识从原始数据中定义和提取显著特征,并提供具有适当归纳偏差的模型,以从这些有限的数据中学习。随着用于NLP的神经网络模型的出现,显著特征的学习与模型本身的训练结合在一起(Collobert et al., 2011;Bengio et al., 2013),因此重点转向了架构工程,其中的归纳偏差更倾向于通过设计一个合适的网络架构,有利于学习这些特征(Tab. 1 b.; e.g. Hochreiter and Schmidhuber (1997); Kalchbrenner et al. (2014); Chung et al. (2014); Kim (2014); Bahdanau et al. (2014); Vaswani et al. (2017))。
然而,从2017-2019年开始,NLP模型的学习发生了翻天覆地的变化,这种完全监督的范式现在正在发挥越来越小的作用。具体来说,标准转移到训练前和微调范式(Tab. 1 c.; e.g. Radford and Narasimhan (2018); Peters et al. (2018); Dong et al. (2019); Yang et al. (2019); Lewis et al. (2020a))。在这种范式中,一个具有固定架构的模型被预先训练为语言模型(LM),预测观察到的文本数据的概率。由于训练LMs所需的原始文本数据非常丰富,这些LMs可以在大型数据集中进行训练,在此过程中学习它所建模的语言的鲁棒通用特性。然后,通过引入额外的参数,并使用特定任务的目标函数对它们进行微调,将上述预先训练的LM适应于不同的下游任务。在这个范例中,重点主要转向了目标工程,设计在训练前和微调阶段使用的训练目标。例如,Zhang等人(2020a)表明,引入一个预测文档中显著句子的损失函数,将导致更好的文本摘要预训练模型。值得注意的是,预先训练的LM的主体通常是(但不总是;Peters (2019)也进行了微调,使其更适合解决下游任务。
现在,在2021年写这篇文章的时候,我们正处于第二次巨变之中,“预训练、微调”程序被我们称之为“预训练、提示和预测”的程序所取代。这个范式,不是通过目标工程将预先训练好的LMs应用到下游任务,而是将下游任务重新制定,使其看起来更像在原始LM训练中通过文本提示解决的任务。例如,当识别社交媒体帖子的情绪时,“我今天错过了公交车。我们可以继续提示“我感觉是这样的”,然后让LM用一个充满感情的词来填补这个空白。或者如果我们选择提示语“English: I missed the bus today.”法语:”),LM可以用法语翻译来填空。这样,通过选择适当的提示,我们可以操纵模型行为,使预先训练的LM本身可以用来预测期望的输出,有时甚至不需要任何额外的任务特定训练(Tab. 1 d.; e.g. Radford et al. (2019); Petroni et al. (2019); Brown et al. (2020); Raffel et al. (2020); Schick and Schutze ¨ (2021b); Gao et al. (2021)。这种方法的优点是,给定一套适当的提示,在完全无监督的方式下训练的单一LM可以用来解决大量任务(Brown et al., 2020; Sun et al., 2021)。与大多数概念上诱人的前景一样,这里有一个陷阱——这种方法引入了快速工程的必要性,找到最合适的提示,让LM能够解决手头的任务。