全是英伟达 DGX A100。到今年年中,它将成为全球速度最快的 AI 超级计算机。
最近一段时间,超级计算机是科技公司比拼的重点。昨天商汤科技的 AIDC 刚刚启用,今天又传来了脸书超算的消息。
当地时间 1 月 24 日,Meta(原 Facebook)揭幕了其研究团队的全新人工智能超级计算机,预计在 2022 年中全部完成后,它将成为世界最快的计算机。
在报道文章中,Meta 表示新超算 AI Research SuperCluster(RSC)将帮助该公司构建更好的 AI 模型,这些模型可以从数万亿个示例中学习,构建跨数百种语言的模型,并同时分析文本内容、图像和视频,确定内容是否有害。当然,RSC 超算也可以用来开发新一代增强现实工具。
Meta 表示,该平台不仅有助于确保人们今天使用 Facebook 服务的安全性,而且在公司为元宇宙构建的将来也会发挥作用。
![]()
社交媒体起家的脸书在去年 10 月更名为 Meta,以反映其对元宇宙的关注,它认为元宇宙将成为移动互联网的继承者。
近几个月,元宇宙当之无愧是科技圈最热的词汇之一,这个概念指的是人们可以通过不同的设备访问共享的虚拟环境,在该环境里人们可以工作、娱乐和社交。「构建元宇宙需要巨大的计算能力(quintillion 级,10 的 18 次方),」Meta 首席执行官马克 · 扎克伯格(Mark Zuckerberg)在 Facebook 上说道: 「AI 和 RSC 将使新的人工智能模型成为可能,它们可以从数以万亿计的例子中学习,理解数百种语言甚至更多。」
Meta 表示,它相信 RSC 是目前运行速度最快的人工智能超级计算机之一。Meta 的一位发言人说,该公司已经与英伟达、Pure Storage 和 Penguin Computing 的团队合作,共同构建这台超级计算机。
高性能计算基础设施是用于训练大规模预训练模型的必要条件。Meta 表示,其 AI 研究团队一直在构建高性能系统,自研的第一代算力设施设计于 2017 年,在单个集群中拥有 2.2 万个英伟达 V100 Tensor Core GPU,每天可执行 3.5 万个训练任务。到目前为止,该基础设施在性能、可靠性和生产力方面为 Meta 研究人员确立了基准。
2020 年初,Facebook 认定加速算力增长的最佳方式是从头开始设计全新计算基础架构,以利用新的 GPU 和网络结构技术。该公司希望新 AI 超算能够在 1 EB 字节大的数据集上训练具有超过一万亿个参数的模型——仅从规模上看,这相当于 36000 年时长的高清晰度视频。
![]()
如此规模的超算肯定不能仅用于科研,Meta 表示,RSC 可以训练来自 Meta 生产系统的真实示例,确保新研究能有效地转化为实践。其推动的新模型可识别社交网络平台上的有害内容,并推动多模态人工智能,以帮助改善用户体验。Meta 认为,这是第一次有人以如此规模同时解决性能、可靠性、安全性和隐私问题。
![]()
AI 超算主要用于人工智能模型的训练,是通过将多个 GPU 组合成计算节点来构建的,其通过高性能网络结构连接这些节点,以实现 GPU 之间的快速通信。
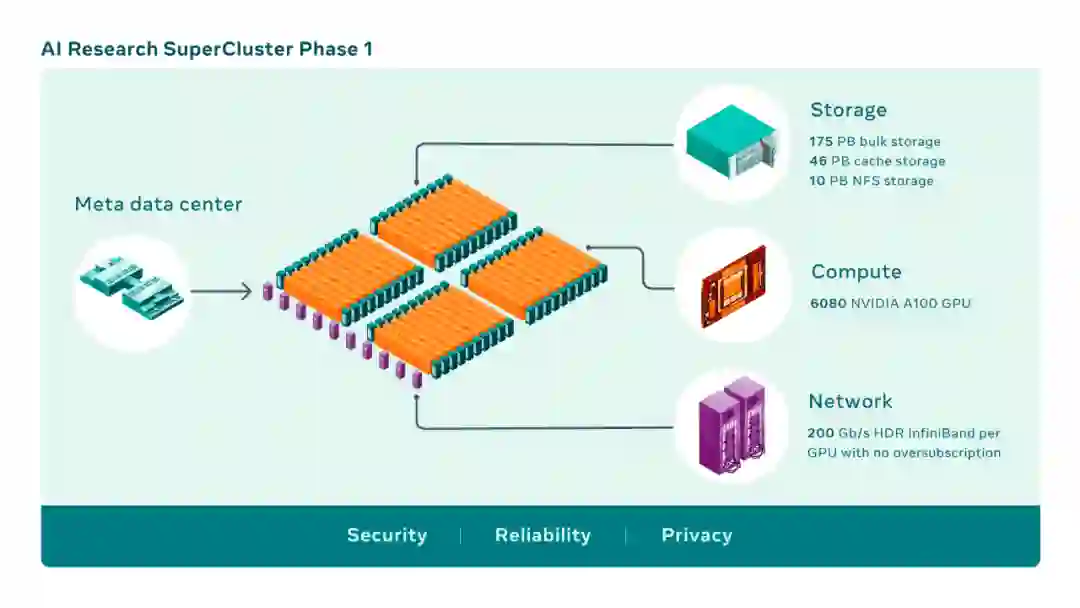
RSC 有 760 个 NVIDIA DGX A100 系统作为其计算节点,总共有 6080 块 GPU,每块 A100 GPU 都比 Meta 之前系统中使用的 V100 更强大。每个 DGX 通过没有超负荷的 NVIDIA Quantum 1600 Gb/s InfiniBand 两级 Clos 结构进行通信。RSC 的存储层具有 175 PB 的 Pure Storage FlashArray、46 PB 的 Penguin Computing Altus 系统中的缓存存储和 10 PB 的 Pure Storage FlashBlade。
![]()
与 Meta 的传统生产和研究基础设施相比,RSC 的早期基准测试表明,它运行计算机视觉工作流程的速度是之前的 20 倍,运行英伟达多卡通信框架 (NCCL) 的速度快了 9 倍,训练大规模 NLP 模型快了 3 倍。这意味着一个拥有数百亿参数的模型可以在 3 周内完成训练,而之前这一数字是 9 周。
作为参考,在最新一次 MLPerf 神经网络训练基准中测试的最大生产就绪(production-ready)系统是英伟达部署的 4320-GPU 系统,该系统可以在不到一分钟的时间内训练 BERT 。然而,BERT「只有」1.1 亿个参数,与 Meta 想要使用的数万亿个参数也无法相比。
RSC 的推出还伴随着 Meta 使用数据进行研究的方式的变化:
与我们之前仅利用开源和其他公开可用数据集的 AI 研究基础设施不同,RSC 允许我们在模型训练中包含来自 Meta 生产系统的真实示例,确保研究有效地转化为实践。
研究人员还写道,RSC 将采取额外的预防措施来加密和匿名这些数据,以防止泄漏。这些步骤包括将 RSC 与更大的互联网隔离既没有入站连接也没有出站连接,RSC 的流量只能从 Meta 的生产数据中心流入。此外,存储和 GPU 之间的数据路径是端到端加密的,数据是匿名的,并经过审查过程以确认匿名。
AI 超算 RSC 已经于昨天正式启用,但它的开发仍在进行中。Meta 表示,一旦完成构建 RSC 的第二阶段,它将可能成为全球最快的 AI 超级计算机,其混合精度计算性能接近 5 exaflops(10 的 18 次方)。
在 2022 年,Meta 正计划将 GPU 的数量从 6080 个增加到 16000 个,这将使 AI 训练性能提高 2.5 倍以上。InfiniBand 互联结构将扩展为支持 16000 个端口,采用两层拓扑结构。该系统的存储系统将具有 16 TB/s 的目标交付带宽和 EB 级容量,以满足不断增长的需求。
https://ai.facebook.com/blog/ai-rsc
https://spectrum.ieee.org/meta-ai-supercomputer
https://www.reuters.com/technology/meta-introduces-fastest-ai-supercomputer-2022-01-24/
https://blogs.nvidia.com/blog/2022/01/24/meta-ai-supercomputer-dgx/
https://www.wsj.com/articles/meta-unveils-new-ai-supercomputer-11643043601
使用Python快速构建基于NVIDIA RIVA的智能问答机器人
NVIDIA Riva 是一个使用 GPU 加速,能用于快速部署高性能会话式 AI 服务的 SDK,可用于快速开发语音 AI 的应用程序。Riva 的设计旨在轻松、快速地访问会话 AI 功能,开箱即用,通过一些简单的命令和 API 操作就可以快速构建高级别的对话式 AI 服务。
2022年1月26日19:30-21:00,最新一期线上分享主要介绍:
对话式 AI 与 NVIDIA Riva 简介
利用NVIDIA Riva构建语音识别模块
利用NVIDIA Riva构建智能问答模块
利用NVIDIA Riva构建语音合成模块
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com