Transformer深至1000层还能稳定训练,微软实习生一作,LSTM之父转发
博雯 发自 凹非寺
量子位 | 公众号 QbitAI
近几年,随着业内“大力出奇迹”的趋势,Transformer的模型参数量也是水涨船高。
不过,当参数从数百万增加至数十亿,甚至数万亿,性能实现相应提升时,Transformer的深度也受到了训练不稳定的限制。
至少,还没有优化方法能在Transformer扩展至上千层的同时,还保证其稳定性。
但现在,微软研究院一篇论文出手,直接将Transformer提升到了1000层:
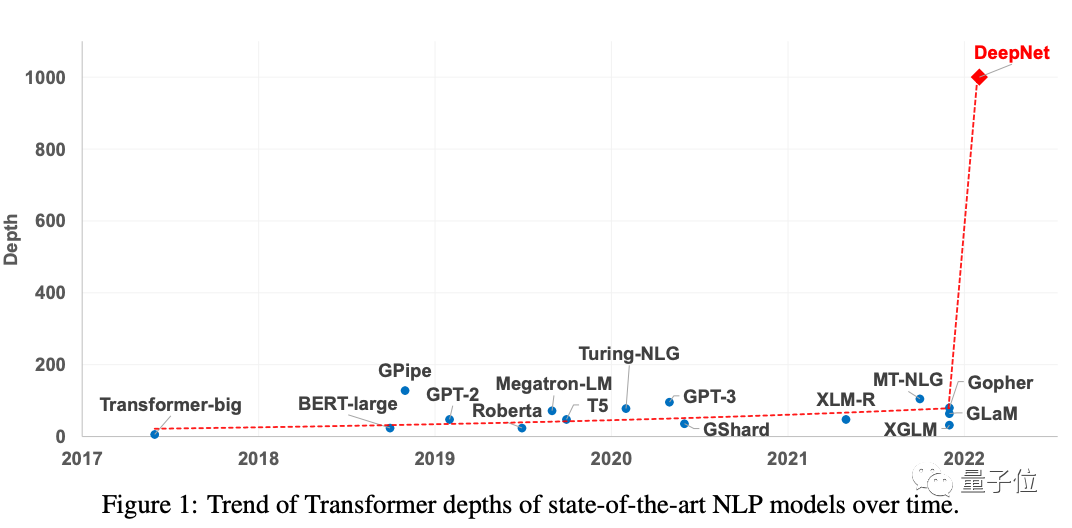
所采用的方法,甚至只需要修改几行代码就能完成。
LSTM之父, 获得IEEE CIS 2021年神经网络先驱奖的Sepp Hochreiter也转发了这项研究:
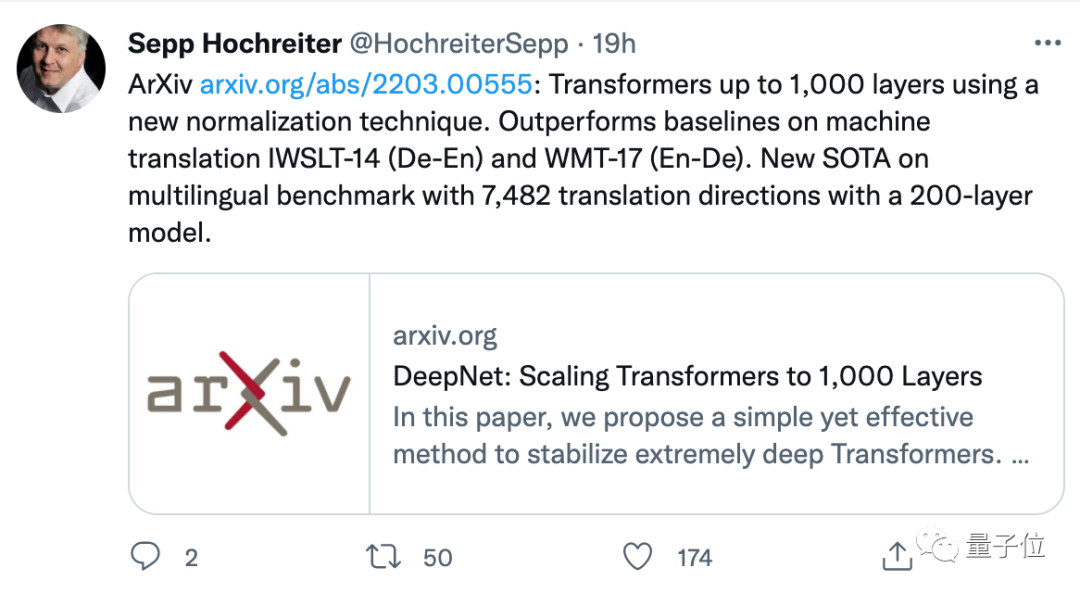
接下来,我们就来一起看看这一方法到底是如何做到的。
几行代码提升至1000层
要解决不稳定优化的问题,首先要知道其原因。
论文认为,这种不稳定性源于训练开始时“爆炸式”的模型更新。
这会使模型陷入一种局部最优状态,增加每个LN(Layer Normalization)的输入量,通过LN的梯度会随着训练变得越来越小,从而导致梯度消失,使模型难以摆脱一开始的局部最优状态。
最终破坏了优化的稳定性。
因此,基于这一问题,开发者残差连接处引入了一个新的归一化函数,DeepNorm:

△DeepNorm伪代码
DeepNorm在执行层归一化之前up-scale了残差连接,在不同架构下具有不同的参数:

这一函数将Post-LN的良好性能和Pre-LN的稳定训练高效结合了起来,最终将Transformer扩展到2500个注意力和前馈网络子层(即1000层)比以前的模型深度高出一个数量级。
将DeepNorm方法应用到Transformer的每一个子层中,就得到了一个全新的DeepNet模型。
事实证明,相较于已有的优化方法Post-LN,DeepNet的模型更新几乎保持恒定:
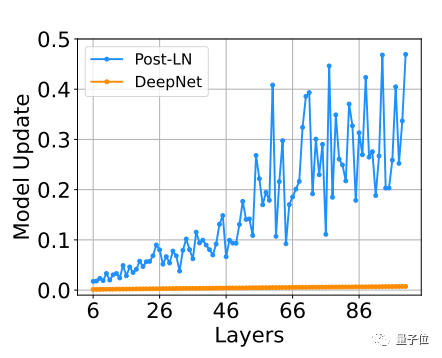
△基于IWSLT-14 De-En翻译数据集的训练
除此之外,开发者也将DeepNet与NormFormer、ReZero、DS-init等多个Transformer模型进行比较,结果在WMT-17 En-De数据集上,DeepNet在多个深度上都效果最好:
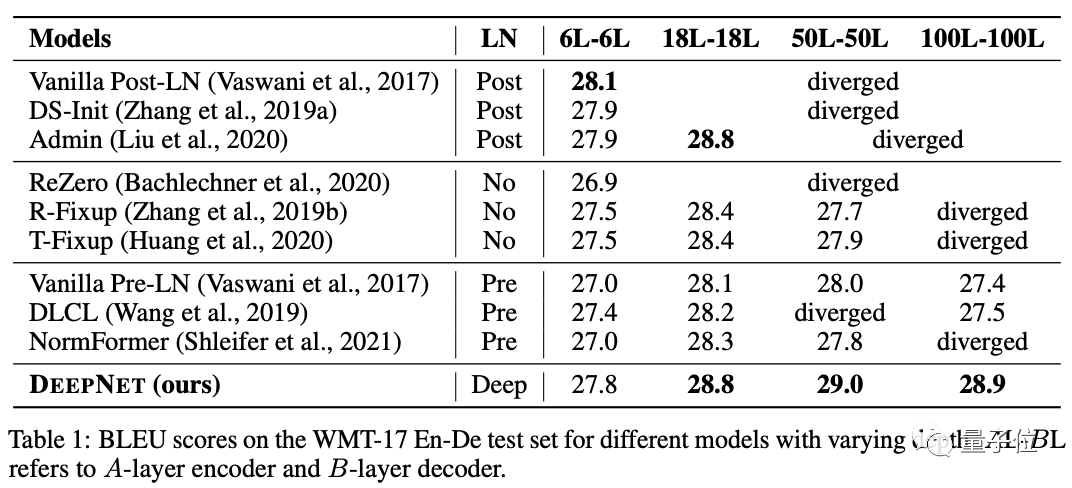
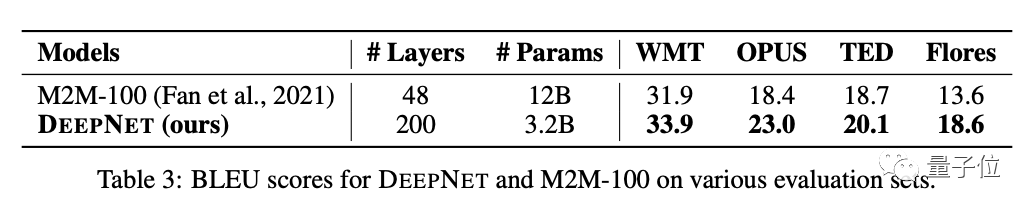
与Facebook AI的M2M模型(120亿参数量、48层)相比,DeepNet(32亿参数量、200层)实现了5 BLEU值的提升。
最后,论文作者之一的董力也现身说明,整体而言,这一研究的价值就是:
1、扩展到1000层增加深度是为了探究上限
2、DeepNorm方法对浅层的Transformer也有稳定作用

作者介绍
论文两位共同一作Hongyu Wang和Shuming Ma,其中Hongyu Wang为微软研究院的一名实习生,并在此期间完成了论文。
而Shuming Ma(马树铭)本科和研究生皆毕业于北京大学,2019年加入微软亚洲研究院,现在是NLP组的一名研究员。

通讯作者为微软亚洲研究院NLP小组的首席研究员韦福如,2004年和2009年从武汉大学计算机科学系获得理学士学位和博士学位,曾任职于IBM中国研究中心。

论文:
https://arxiv.org/abs/2203.00555
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



