可构建AI的“AI”诞生:几分之一秒内,就能预测新网络的参数

作者:Anil Ananthaswamy
译者:刘媛媛
原文出处:quantamagazine.org

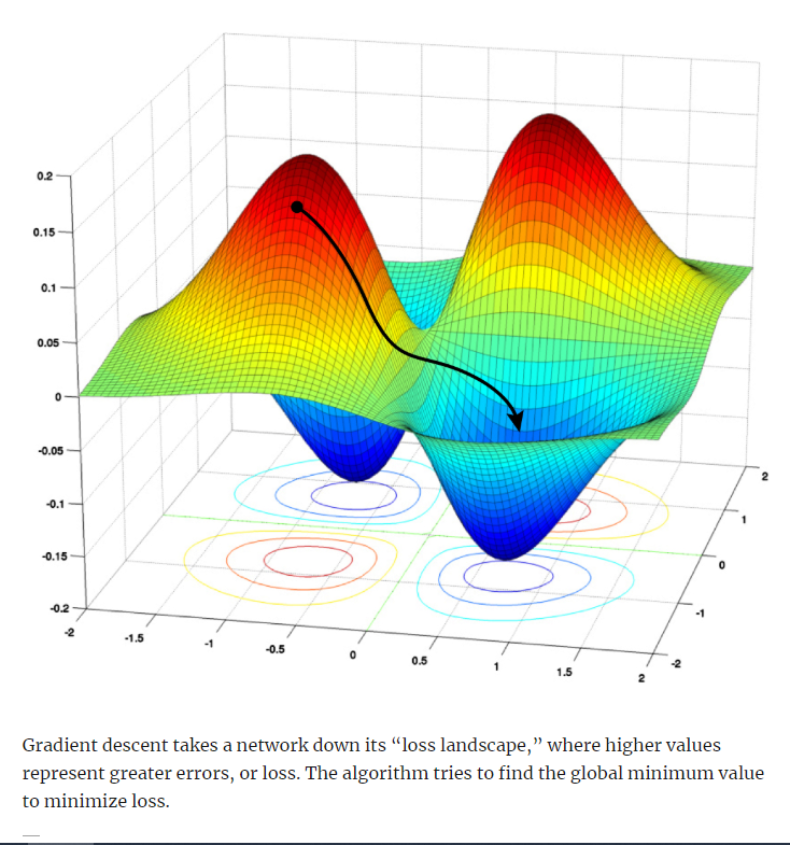
今天的神经网络更依赖于数据和算力。训练网络时,需要仔细调整表征网络的数百万甚至数十亿参数值,这些参数代表人工神经元之间连接的强度。目标是为它们找到接近理想的值,这个过程称为优化。但训练网络要达到这一点并不容易。伦敦 DeepMind 的研究科学家 Petar Veličković 说:“训练可能需要花费几天、几周甚至几个月的时间”。
但上述这种情况可能很快就会改变。安大略省圭尔夫大学的 Boris Knyazev 和他的同事设计并训练了一个“超网络”——一种其他神经网络的“霸主”,该网络可以加快训练过程。给定一个为某些任务设计的新的、未经训练的深度神经网络,超网络可以在几分之一秒内预测新网络的参数,理论上可以使训练变得不必要。由于超网络学习了深度神经网络设计中极其复杂的模式,因此这项工作也可能具有更深层次的理论意义。这项研究题为 Parameter Prediction for Unseen Deep Architectures。
目前,超网络在某些环境中表现的出人意料地好,但仍有增长空间。Veličković 说:“如果他们能解决相应问题,这将对机器学习产生很大的影响”。

但是这种技术只有在网络需要优化时才有效。为了构建最初的神经网络(一般由从输入到输出的多层人工神经元组成),工程师必须依靠直觉和经验法则。这些架构在神经元层数、每层神经元数等方面可能有所不同。
所以在 2018 年,Ren 和他在多伦多大学的前同事 Chris Zhang 及他们的顾问 Raquel Urtasun 尝试了一种不同的方法。他们设计了所谓的图超网络(Graph Hypernetwork: GHN),可以在给定一组候选架构的情况下,找到解决某些任务的最佳深度神经网络架构。
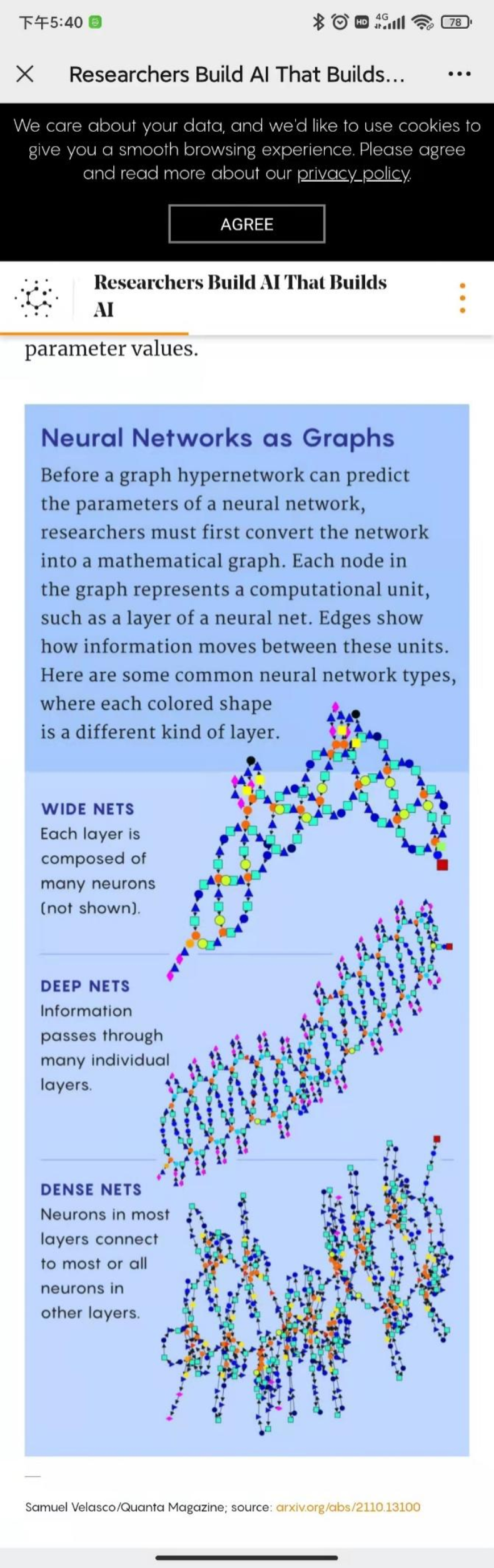
该名称概述了他们的方法。“图”指的是深度神经网络的架构,可以被认为是一个数学图——由线或边连接的点或节点的集合。这里的节点代表计算单元(通常是神经网络的整个层),边代表这些单元互连的方式。
图超网络的工作原理是首先对于任何需要优化的架构(称其为候选架构),它尽最大努力预测候选者的理想参数。然后将实际神经网络的参数设置为预测值,并在给定任务上对其进行测试。Ren 的团队表明,这种方法可用于对候选架构进行排名,并选择表现最佳的架构。
当 Knyazev 和他的同事看到图超网络的想法时,他们意识到可以在此基础上进行构建。在他们的新论文中,该团队展示了如何使用 GHN,不仅从一组样本中找到最佳架构,还可以预测最佳网络的参数,使其在绝对意义上表现良好。在还没有达到最好的情况下,其可以使用梯度下降进一步训练网络。
Ren 说:“这是一篇非常扎实的论文,它包含了更多我们所做的实验。看到图超网络在非常努力地提升绝对性能,我们大家都很高兴。”
首先,他们依赖 Ren 等人将神经网络架构描绘为图的技术。图中的每个节点都是关于执行某种特定类型计算的神经元子集的编码信息。图的边缘描绘了信息如何从一个节点到另一个节点,从输入到输出。
第二,他们借鉴了训练超网络预测新的候选架构的方法。这需要另外两个神经网络。第一个启用对原始候选图的计算,从而更新与每个节点相关的信息,第二个将更新的节点作为输入,并预测候选神经网络的相应计算单元的参数。这两个网络也有自己的参数,必须在超网络正确预测参数值之前对其进行优化。
具体流程如下,首先你需要训练数据——候选人工神经网络(Artifical Neural Network: ANN)架构的随机样本。对于示例中的每一个架构,先从一个图开始,之后使用图超神经网络预测参数,并使用预测的参数初始化候选 ANN。使用 ANN 来执行一些特定的任务,如图像识别。通过计算 ANN 的损失函数,来更新做出预测的超网络参数,而不是更新 ANN 的参数做出预测。这样可以使超网络在每一次迭代后做的更好;然后,通过迭代标记过的训练数据集中的每一个图像和架构的随机样本中的每一个 ANN,来减少每一步的损失,直到达到最优。一般这个情况下,你就可以得到一个训练有素的超网络。
因为 Ren 的团队没有公开源代码,所以 Knyazev 的团队采纳了这些想法,从头开始编写了自己的软件,并对其进行了改进。首先,他们确定了 15 种类型的节点,通过混合、匹配可以构建任何现代深度神经网络。他们还在提高预测的准确性上取得了一些进步。
最重要的是,为了确保 GHN-2 学会预测各种目标神经网络架构的参数,Knyazev 及其同事创建了一个包含 100 万个可能架构的独特数据集。Knyazev 说:“为了训练我们的模型,我们创建了尽可能多样化的随机架构”。
因此,GHN-2 的预测能力更有可能被很好地推广到看不见的目标架构。谷歌研究院大脑团队的研究科学家 Thomas Kipf 说:“例如,它们可以解释人们使用的所有典型的最先进的架构,这是一个重大贡献。”
借助经过全面训练的 GHN-2 模型,该团队预测了 500 个以前看不见的随机目标网络架构的参数。然后将这 500 个网络(其参数设置为预测值)与使用随机梯度下降训练的相同网络进行对比。尽管有些结果更加复杂,但新的超网络通常可以抵御数千次 SGD 迭代,有时甚至做得更好。

GHN-2 在 ImageNet 上表现不佳,ImageNet 是一个相当大的数据集。平均而言,它的准确率只有 27.2% 左右。尽管如此,这与使用 5,000 步 SGD 训练的相同网络的 25.6% 的平均准确度相比也是有利的。 (当然,如果你继续使用 SGD,你最终可以以相当大的成本获得 95% 的准确率。)最关键的是,GHN-2 在不到一秒的时间内做出了 ImageNet 预测,而使用 SGD 在图形处理单元上预测参数,来获得相同的性能,平均花费时间比 GHN-2 要长 10,000 倍。
Veličković 说:“结果绝对令人印象深刻,他们基本上大大降低了能源成本。”
当 GHN-2 从架构样本中为一项任务找到最佳神经网络,而该最佳选择还不够好时,至少模型已经得到了部分训练并且可以进一步优化。与其在使用随机参数初始化的网络上释放 SGD,不如使用 GHN-2 的预测作为起点。Knyazev 说:“基本上我们模仿的是预训练”。
与此同时,Knyazev 看到了很多改进的机会。例如,GHN-2 只能被训练来预测参数以解决给定的任务,例如对 CIFAR-10 或 ImageNet 图像进行分类,但不能同时进行。在未来,他设想在更多样化的架构和不同类型的任务(例如图像识别、语音识别和自然语言处理)上训练图超网络。然后根据目标架构和手头的特定任务来进行预测。
如果这些超网络真的成功,新的深度神经网络的设计和开发,将不再局限于财力雄厚和能够访问大数据的公司。任何人都可以参与其中。Knyazev 非常清楚这种“使深度学习民主化”的潜力,称其为长期愿景。
然而,如果像 GHN-2 这样的超网络真的成为优化神经网络的标准方法,Veličković 强调了一个潜在的大问题。他说:“你有一个神经网络——本质上是一个黑盒子,再使用图超网络去预测另一个神经网络的参数。当它出错时,你无法解释[它]。”
当然,在很大程度上这已经是神经网络的特点了。Veličković 说:“我不会称之为弱点,而称之为警告信号。”
然而,Kipf 看到了一线希望。“一些其他的事物让我对此感到最兴奋,即 GHN-2 展示了图神经网络在复杂数据中寻找模式的能力。”
通常,深度神经网络会在图像、文本或音频信号中找到模式,这些是相当结构化的信息类型。而 GHN-2 在完全随机的神经网络架构图中找到模式。这是非常复杂的数据。
然而,GHN-2 可以泛化——这意味着它可以对看不见的、甚至分布式网络架构以外的参数做出合理的预测。Kipf 说:“这项工作向我们展示了许多模式在不同的架构中以某种方式相似,并且模型可以学习如何将知识从一种架构转移到不同的架构,这可能会激发一些神经网络的新理论。”
如果是这样的话,它可能会让我们对这些黑匣子产生新的、更深入的理解。
热门视频推荐
更多精彩视频,欢迎关注学术头条视频号

winter
【学术头条】持续招募中,期待有志之士的加入



登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月20日
Arxiv
10+阅读 · 2021年10月4日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月20日
Arxiv
10+阅读 · 2021年10月4日