加入极市专业CV交流群,与10000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
导读:本文提出一种新颖的基于单张 RGBD 图像的物体6D位姿估计算法;不同于现有的直接回归位姿参数的方法,它开创性地提出用深度神经网络检测 3D 关键点来解决单目 6D 位姿估计这个问题。论文代码已开源。
https://arxiv.org/abs/1911.04231
https://github.com/ethnhe/PVN3D.git
导语
本文的研究课题是 6DoF 位姿估计,即在标准框架下识别一个物体的 3D 定位和方向。该技术是许多实际应用的一个重要组件,比如机器人、自动驾驶、增强现实等。
由于光线变化、传感器噪声、场景遮挡及物体截断等,6DoF 估计一直是一个颇具挑战性的问题,传统方法使用手工设计的特征,提取图像与物体网格模型之间的对应关系,但是这些人工设计的特征在明暗变化及严重遮挡的场景下表现不尽人意。
近期,随着机器学习与深度学习技术的爆发,深度神经网络(DNN)被用于解决这一任务,并取得显著效果。一些方法提出直接使用 DNN 回归物体的旋转和平移变换参数,但是由于旋转空间是非线性的,这些方法的泛化性往往较差。
另一些方法则通过 DNN 检测一个物体的 2D 关键点,再通过2D到3D点的对应关系使用PnP算法计算 6D 位姿参数。尽管这种两阶段的方法更加稳定,但 PnP 算法构建在最小化 2D 投影误差上,而 2D 上的小误差在真实的 3D 空间中会被放大很多。而且,3D 空间中的不同关键点可能会在 2D 投影后发生重叠,变得难以区分;更重要的,刚体的几何约束信息会由于相机的投影操作而部分损失。
另一方面,随着 RGBD 传感器和数据集的普及,额外的深度信息允许研究者将 2D 算法扩展至 3D 空间,并在 3D 物品检测等问题上取得了良好的性能。本文充分利用了刚体的几何约束信息,提出了一个基于 3D 关键点投票网络的 6DoF 位姿估计算法,并显著超越了当前的最佳性能。
简介
为推进这一方向,旷视研究院把基于 2D 关键点的方法推进至 3D 关键点,以充分利用刚体的几何约束信息,极大提升了 6DoF 估计的精确性。
具体而言,旷视研究院提出一种基于霍夫投票(Hough voting)的 3D 关键点检测神经网络,称之为 PVN3D,以学习逐点到 3D 关键点的偏移并为 3D 关键点投票,如图 1 所示。
本文的其中一个关键发现是一个简单的几何特性,即在 3D 空间中,一个刚体上任意两点之间的相对位置关系是固定的。因此,给定物体表面的一个可见点,它的坐标和方向可由深度信息获得,其相对于刚体上预选关键点的平移偏移量也是确定且可学习的。同时,深度神经网络学习逐点欧几里得偏移直截了当,且易于优化。
当应对含有多个物体的场景时,旷视研究院在网络中引入一个实例语义分割模块,并和关键点投票任务联合优化。本文发现,联合训练这些任务可以让网络学出更好的表征从而提升网络在每一个任务上的性能。一方面,语义分割通过确认一个点属于物品的哪一部分从而辅助判断该点到关键点的平移偏移;另一方面,平移偏移量包含的物品的尺度信息有助于模型区分外表相似但大小不同的物体。
旷视研究院在 YCB-Video 和 LineMOD 两大公开数据集上进行了评估实验,结果表明该方法以大幅优势取得了当前最佳性能。
方法
给定一张 RGBD 图像, 物品 6DoF 位姿估计任务旨在估计一个把物体从其物品坐标系转换到相机坐标系的刚性变换。这一转变包含一个 3D 旋转变换和一个 3D 平移变换。
为此,旷视研究院基于深度 3D 霍夫投票网络开发了一种新颖的方法——PVN3D,如图 2 所示。
这是一种两阶段方法,在检测出物品的 3D 关键点之后使用最小二乘法拟合出位姿参数。具体而言,输入RGBD 图像,通过特征提取模块融合表面特征和几何信息获得逐点特征。这些特征被送至一个 3D 关键点检测模块以预测逐点到 3D 关键点的偏移(以投票出 3D 关键点)。
另外,本文提出一个实例分割模块用于处理多物体场景,其中包含一个语义分割模块用以预测逐点的语义标签,一个中心投票模块用以预测逐点相对其物体中心的平移偏移量。
借助已学习的逐点到其所在物品中心点的偏移,应用聚类算法区分具有相同语义标签的不同实例,然后使用相同实例上的点投票并聚类出该物品的 3D 关键点。最后,利用相机坐标系下的物品关键点坐标和物品坐标系下的 3D 关键点坐标的对应关系,使用最小二乘拟合算法估算出物品的 6DoF 位姿参数。
本文学习算法的目标是训练一个 3D 关键点检测模块 M_k,用于预测逐点到 3D 关键点的偏移;以及一个语义分割模块 M_s 和中心点投票模块 M_c,用于实例语义分割。这样网络训练自然形成一个多任务学习任务。本文使用一个多任务监督损失函数和若干个训练细节来实现。
如图 2 所示,在特征提取模块提取逐点的特征之后,3D 关键点检测模块检测每个物体的3D关键点,具体而言,该模块预测从可见点到目标关键点的欧几里得平移偏移量。
通过这些可见点的坐标和预测的偏移量计算出目标关键点的位置作为投票点。这些投票的点由聚类算法进行聚类以消除离群点的干扰,群集的中心点被选为投票选出的关键点。关键点平移量学习模块 M_k 使用 L1 loss 进行监督:
给定提取出的逐点特征,语义分割模块 M_s 预测每点的语义标签,本文使用 Focal
同时,中心点投票模块 M_c 投票出不同物体的中心点,以区分相同语义的不同实例。由于中心点可视为一种特殊的物体关键点,该模块和 M_k 类似,使用L1 loss 进行监督学习:
本文使用一个多任务损失函数联合监督 M_k、M_s、M_c 的学习:
实验
在YCB-Video和LineMOD基准上的实验结果
表 1 给出了在 YCB-Video 数据集上的量化评估结果。如表所示,本文方法(PVN3D)即使在没有借助任何迭代优化算法时也能大幅超越其他方法;而在迭代优化算法ICP 的加持下,本文方法(PVN3D+ICP)取得了更好的性能。
表 1:不同方法在YCB-Video数据集上的量化结果
表 2 给出使用 ground truth 分割的评估结果,PVN3D 依然取得最佳性能。
![]() 表 2:在YCB-Video数据集上使用ground truth分割的量化结果
图 3 可视化了在YCB-Video数据集上的一些预测结果,PVN3D 比先前方法更准确。
图 4 展示随着物品被遮挡比例的增加,不同方法的表现性能曲线。可见本文方法在物品被大量遮挡的场景下表现更加稳定。
图 4:YCB-Video数据集上不同程度的遮挡下算法的性能曲线
表 3 给出了在 LineMOD 数据集上的量化结果,本文模型同样取得当前最佳性能。
表 2:在YCB-Video数据集上使用ground truth分割的量化结果
图 3 可视化了在YCB-Video数据集上的一些预测结果,PVN3D 比先前方法更准确。
图 4 展示随着物品被遮挡比例的增加,不同方法的表现性能曲线。可见本文方法在物品被大量遮挡的场景下表现更加稳定。
图 4:YCB-Video数据集上不同程度的遮挡下算法的性能曲线
表 3 给出了在 LineMOD 数据集上的量化结果,本文模型同样取得当前最佳性能。
![]() 表 3:不同方法在LineMOD数据集上的量化结果
表 3:不同方法在LineMOD数据集上的量化结果
表 4 对比了基于 3D 关键点范式的方法和基于别的范式方法的性能,在相同的输入和神经网络架构下,基于3D关键点的方法 (3D KP) 性能远超直接回归位姿参数的方法 (RT),基于 2D 关键点的方法 (2D KP; 2D KPC; PVNet) 以及基于稠密对应关系的方法(Corr)。本文相信基于3D关键点的位姿估计范式是一个极具潜力的研究方向,值得更多深入的研究。
表 4:不同范式在YCB Video数据集上的表现性能
表 5 对比了不同关键点选择方式以及关键点数目对性能的影响,可见使用FPS算法选择的关键点优于3D检测框的8个角点,并且预测8个关键点是网络输出空间大小和最小二乘拟合位姿参数误差的一个较好的平衡。
表 6 和表 7 显示,联合训练两种任务的三个模块(M_k, M_s, M_c)能让网络学出更好的表征,从而在语义分割和位姿估计任务上能相互促进,彼此提升性能。图 5 展示了联合训练对外观相似,大小不同的物品的区分作用。
![]() 图 5:联合训练对同外观,不同大小物品的语义区分效果
图 5:联合训练对同外观,不同大小物品的语义区分效果
结论
旷视研究院提出一种新颖的基于深度 3D 关键点投票网络的 6DoF 位姿估计算法,其性能在两大公开基准上大幅超越先前所有方法。
本文同样表明,通过联合训练语义分割及3D 关键点两种任务可以学出更好的表征从而提升各个任务的性能。相信在解决 6DoF 位姿估计问题上,基于 3D 关键点的方法是一个极具潜力且值得深入研究的方向。
Peng, S., Liu, Y., Huang, Q., Zhou, X., & Bao, H. (2019). Pvnet: Pixel-wise voting network for 6dof pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 4561-4570).
Xu, D., Anguelov, D., & Jain, A. (2018). Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 244-253).
Qi, C. R., Litany, O., He, K., & Guibas, L. J. (2019). Deep hough voting for 3d object detection in point clouds. In Proceedings of the IEEE International Conference on Computer Vision (pp. 9277-9286).
Qi, C. R., Liu, W., Wu, C., Su, H., & Guibas, L. J. (2018). Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 918-927).
Wang, C., Xu, D., Zhu, Y., Martín-Martín, R., Lu, C., Fei-Fei, L., & Savarese, S. (2019). Densefusion: 6d object pose estimation by iterative dense fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 3343-3352).
Comaniciu, D., & Meer, P. (2002). Mean shift: A robust approach toward feature space analysis. IEEE Transactions on pattern analysis and machine intelligence, 24(5), 603-619..
Duan, K., Bai, S., Xie, L., Qi, H., Huang, Q., & Tian, Q. (2019). Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE International Conference on Computer Vision (pp. 6569-6578).
极市平台视觉算法季度赛,提供真实应用场景数据和免费算力,特殊时期,一起在家打比赛吧!
![]()
添加极市小助手微信
(ID : cv-mart)
,备注:
研究方向-姓名-学校/公司-城市
(如:目标检测-小极-北大-深圳),即可申请加入
目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群
,更有
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、
干货资讯汇总、行业技术交流
,
一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ ![]()

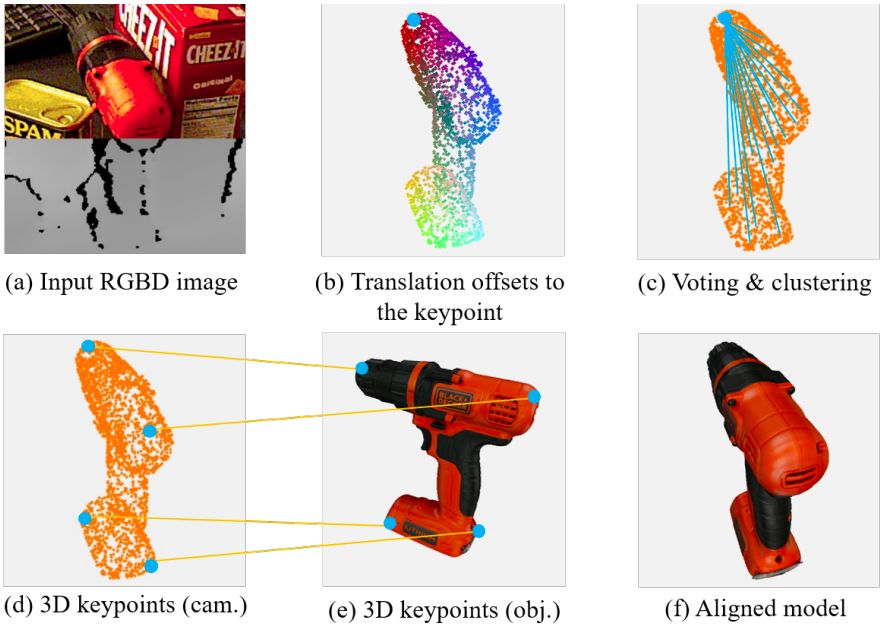
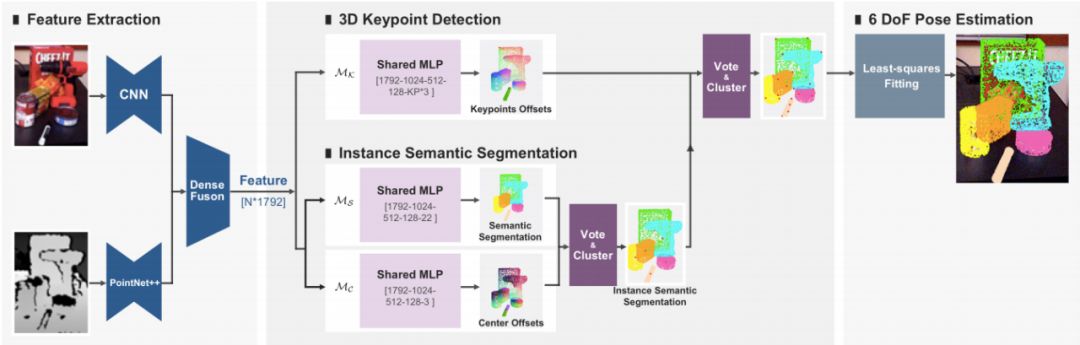
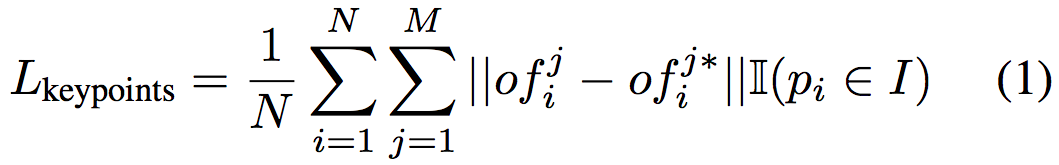
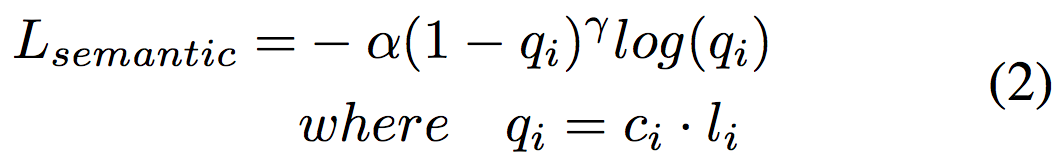
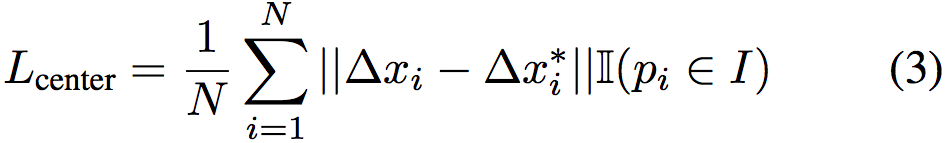
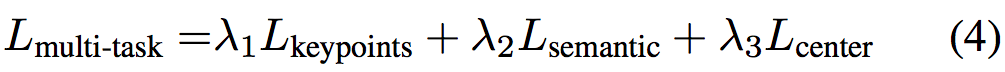
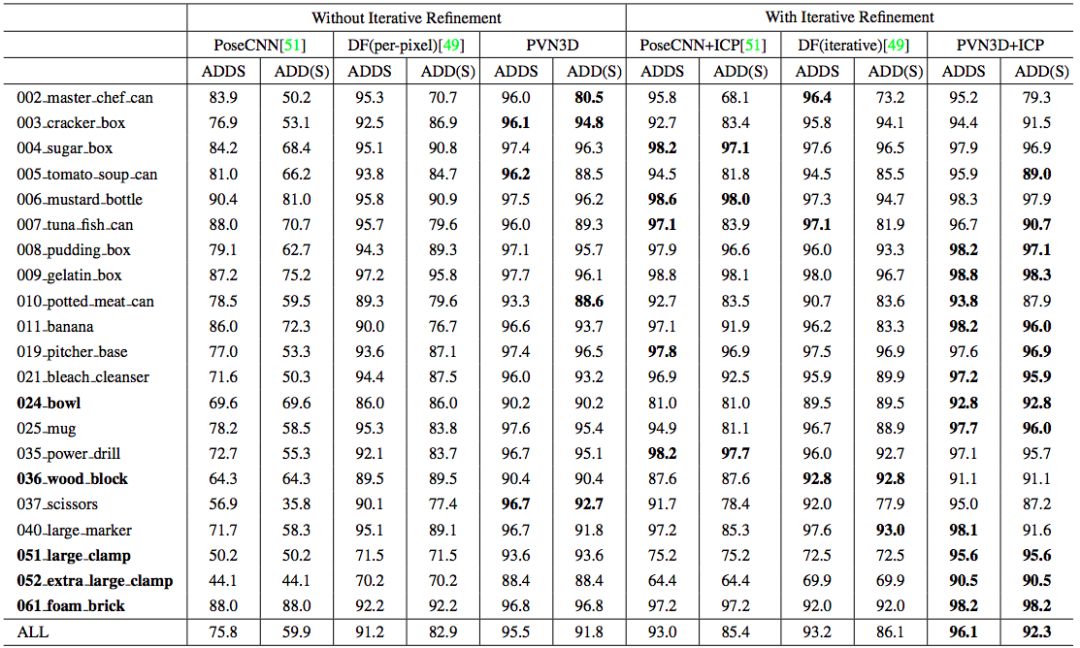
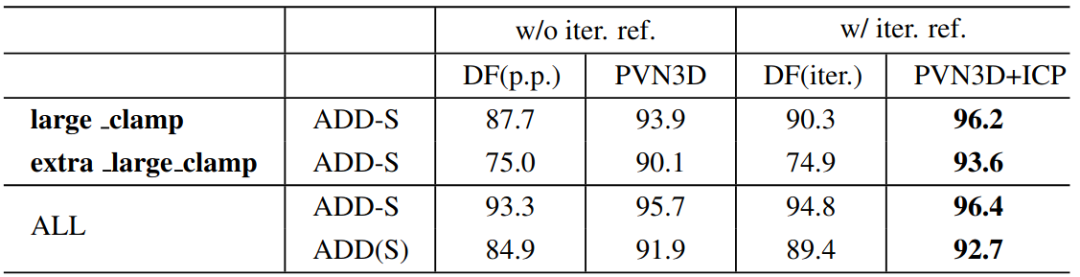 表 2:在YCB-Video数据集上使用ground truth分割的量化结果
表 2:在YCB-Video数据集上使用ground truth分割的量化结果
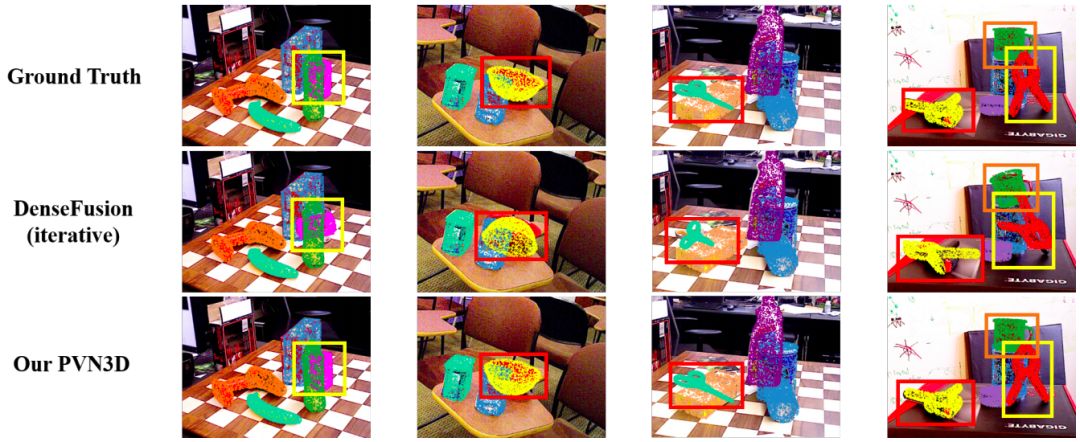
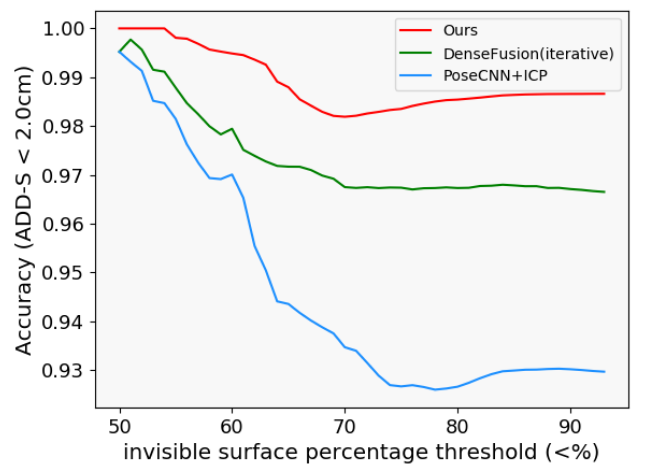
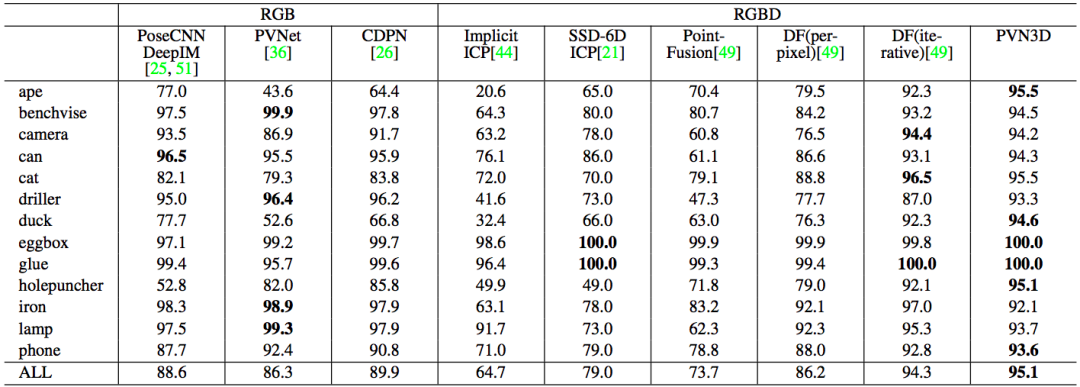 表 3:不同方法在LineMOD数据集上的量化结果
表 3:不同方法在LineMOD数据集上的量化结果




 图 5:联合训练对同外观,不同大小物品的语义区分效果
图 5:联合训练对同外观,不同大小物品的语义区分效果