ICCV 2019 | 旷视研究院提出新型矫正网络ScRN,优化场景文字识别性能
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
两年一度的国际计算机视觉大会 ICCV 2019 ( IEEE International Conference on Computer Vision) 将于当地时间 10 月 27 至 11 月 2 日在韩国首尔举办。旷视研究院共有 11 篇接收论文,涵盖通用物体检测及数据集、文字检测与识别、半监督学习、分割算法、视频分析、影像处理、行人/车辆再识别、AutoML、度量学习、强化学习、元学习等众多领域。在此之前,旷视研究院将每周介绍一篇 ICCV 2019 接收论文,助力计算机视觉技术的交流与落地。
本文是第 2 篇,旷视研究院(联合华中科技大学、北京大学、牛津大学)提出一个基于对称性约束的矫正网络 ScRN,用于场景文字识别。通过共享的 backbone,ScRN 显著提升文字识别性能的同时,所增加的计算量却可忽略不计。实验结果表明了本文方法的有效性和鲁棒性。

论文名称:Symmetry-constrained Rectification Network for Scene Text Recognition
论文地址:https://arxiv.org/abs/1908.01957
目录
导语
简介
方法
矫正模块
定义
几何属性预测
字符方向
识别模块
实验
对比 STN-based 方法
对比当前最优方法
结论
参考文献
往期解读
导语
场景文字阅读(Scene text reading)是当下一个重要而活跃的计算机视觉研究领域,其中,场景文字识别(Scene text recognition)是该技术的关键一步,它旨在把图像的文字区域转换成机器可读的符号。
由于复杂的背景、不规则的形状、多变的字体以及不等的光照条件,场景文字识别依然是一项充满艰巨挑战的任务。
现实场景中的文字有着变化多样的形状,比如水平、有向或者弯曲。关于非规则的文字处理,已经开展了大量工作。
比如 RARE 和 ASTER,在识别之前有一个矫正模块,通过矫正非规则文字从未提升文字识别精度。
这些矫正模块大多基于空间转换网络 STN(spatial transform network),如图 1a 所示,它以弱监督的方式预测文字轮廓的控制点。

但是,这些基于 STN 的算法预测的控制点是分离的,并且忽略了先验。如果没有关于这些先验的任何约束,在高度弯曲或变形的情况下,文字矫正的效果可能并不令人满意。
简介
为进一步提升不规则文字的矫正效果,旷视研究院提出一种新的方法 ScRN(Symmetry-constrained Rectification Network),它借助每个文字实例的中心线,并通过一些几何属性,来达到矫正的目的。
具体而言,每个文字的中心线会更加灵活地描述正常或弯曲文字的形态,它相关的几何属性可以稳定地评估方向,以及垂直方向上文字线条的边界。
进一步,控制点的生成过程确保了其空间分布中的对称性约束。ScRN 是一个简单的分割网络,它只包含两卷积层,因此,当与文字识别器结合时,它只产生可忽略不计的计算和内存开销。
相较于先前基于 STN 的方法,ScRN 由于受益于控制点的对称性约束,从而在鲁棒性和可解释性上有明显优势。通过这种方式,ScRN 可通过提升在不规则文字上的矫正表现而进一步提升文字识别的精度。如图 1b 所示。
方法
如图 2 所示,本文方法的 pipeline 包含三个主要部分:1)共享的 backbone 网络,2)矫正网络,3)识别网络。模型是端到端可训练的,并把文字矫正和识别融进一个统一的框架。

图 2:本文方法 pipeline
矫正模块
定义文本的形状对于矫正文本来讲十分关键,因为矫正的过程可视为一种形状转化。
如上所示,对称性约束对于精确的文字矫正来说是必须的。在矫正模块添加这些约束之后,本文使用文字中心线及其相关的几何属性描述文字实例的形状。
本节将会引入一个文字矫正的新表征,描述如何使用给定的几何属性矫正文字图像,并强调了引入字符方向用于精确矫正的必要性。
定义
文字矫正的几何属性如图 3 所示。
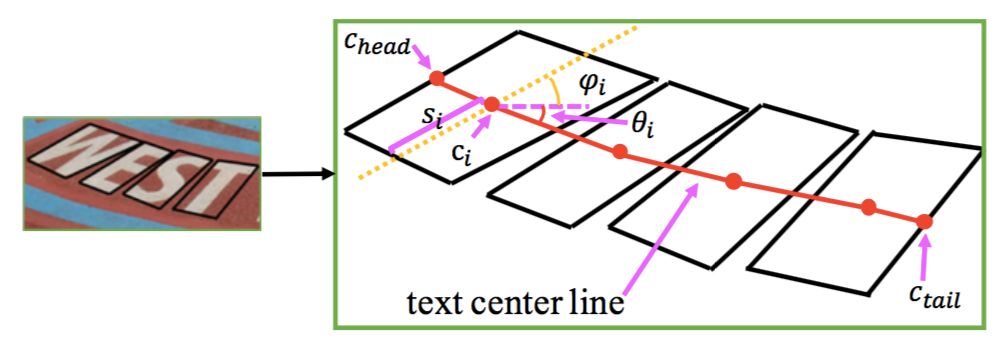
图 3:文字表示图式
一个文字实例可被看成一个有序的字符序列 A。首先,构建一个中心点 list C;其次,按照顺序连接中心点构成文字中心线(TCL)。
尺度 scale 被定义为文字中心点 C 距离上下边框中点的距离,文字方向 θ 被定义为 TCL 与水平方向的夹角,字符方向 φ 被定义为上下边框中点连线与水平方向的夹角。
对于属于 TCL 但不属于 C 的点,其几何属性值被最近的两个中心点线性插值。通过这种方式,文字的形状被精确描述,并可用于后续的矫正步骤。
几何属性预测
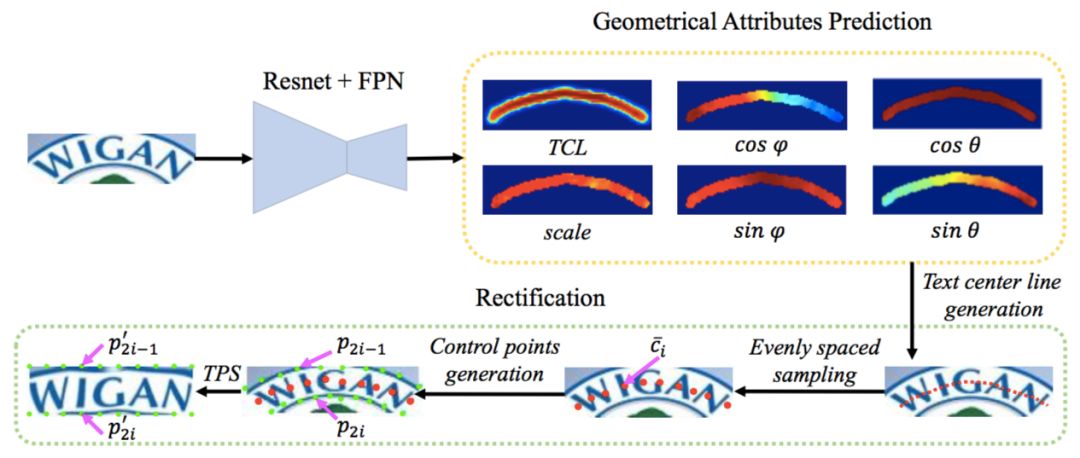
图 4:矫正过程
矫正过程如图 4 所示。为产生几何属性,本文使用了一个轻量级的预测器,它只包含两个卷积层,并输出 6 个通道来表示 TCL、scale、文字方向、字符方向的几何属性信息。根据这些几何属性信息,ScRN 可以精准地生成控制点,用于之后的文字矫正中。
字符方向
当所有字符的边界框是矩形时,字符方向和文字方向是垂直的。但是,在更普遍的情况下,这种垂直并不是正确的字符方向,从而导致矫正失败。
如图 5 所示,左图是 ScRN 的矫正结果,右图是未采用字符方向的矫正效果。

图 5:控制点以及矫正结果,左为字符方向,右为正常的文字方向
识别模块
根据预测的几何属性,我们对 backbone 生成的特征图进行矫正,并从已矫正的特征图中预测一个字符序列。首先,我们会将特征图经过全卷积网络变为一个特征序列,并使用基于注意力机制的编解码器进行文字解码。识别模块的设置如表 1 所示。

表 1:识别模块的架构
实验
对比 STN-based 方法
本文方法与两种基于 STN 的方法做了对比。一个是类似于 ASTER 那样,利用 STN 自动学习控制点,然后进行矫正,称之为 STN_baseline;另一个则是在 STN 中增加了控制点监督的方法,称之为STN_supervision。
这两个方法与本文方法共享相同的 backbone 和识别模块,只是在矫正模块上略有区别。三种方法的实验结果对比如图 7 所示。

图 7:ScRN、STN baseline 和 STN supervision 的矫正结果对比
可以看到,借助对称性约束,ScRN能够得到更好的矫正结果和识别结果。
对比当前最优方法
表 4 给出了本文方法与当前最优方法在七个文本识别数据集上的对比结果。
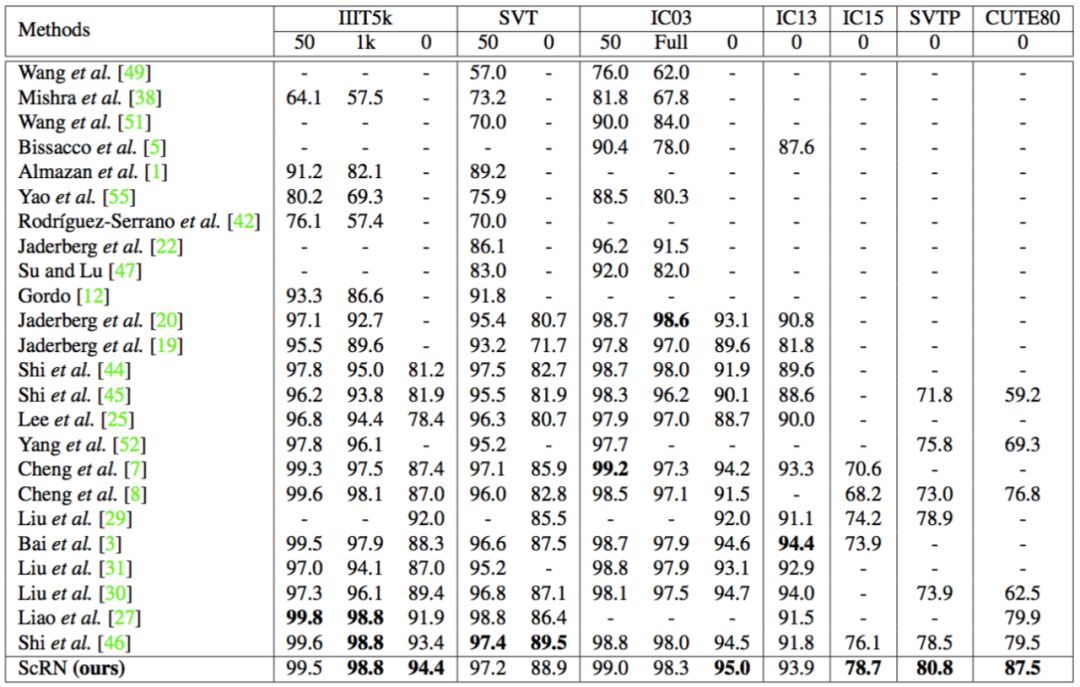
表 4:一系列方法和数据集上的对比结果
结论
本文提出一个基于对称性约束的矫正网络 ScRN,用于场景文字识别。ScRN 是一个非常灵活的模块,它即可轻松整合进现有识别模型之中,也可在一个统一架构中实现端到端训练。
本文的文字识别系统含有 ScRN,在一系列基准数据集上取得了当前最优的成绩,尤其是在那些带有大比例不规则文字图像的数据集上。
通过共享的 backbone,ScRN 显著提升识别性能的同时,所增加的计算量却可忽略不计。实验结果表明了本文方法的有效性和鲁棒性。
未来,旷视研究院将把该方法扩展到一个端到端的文字识别系统,以处理任意形状的文字实例。
参考文献
F. L. Bookstein. Principal warps: Thin-plate splines and the decomposition of deformations. TPAMI, 11(6):567–585, 1989.
Z.Cheng,Y.Xu,F.Bai,Y.Niu,S.Pu,andS.Zhou.Aon:To- wards arbitrarily-oriented text recognition. In CVPR, pages 5571–5579, 2018.
M. Jaderberg, K. Simonyan, A. Zisserman, et al. Spatial transformer networks. In NIPS, pages 2017–2025, 2015.
B.Shi,M.Yang,X.Wang,P.Lyu,C.Yao,andX.Bai.Aster: an attentional scene text recognizer with flexible rectifica- tion. TPAMI, 2018.
S. Long, J. Ruan, W. Zhang, X. He, W. Wu, and C. Yao. Textsnake: A flexible representation for detecting text of ar- bitrary shapes. In ECCV, pages 19–35. Springer, 2018.
T. Lin, P. Dolla ́r, R. B. Girshick, K. He, B. Hariharan, and S. J. Belongie. Feature pyramid networks for object detec- tion. In CVPR, pages 936–944, 2017.
-完-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~




