CVPR 2019 | 旷视研究院提出一种行人重识别监督之下的纹理生成网络
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
转载自:旷视研究院
本文提出一种端到端学习策略,可在行人重识别的监督下生成人体纹理。
导语
近年来,单一图像的人体 3D 姿态与形状估计的研究热情居高不下,但是却忽略了纹理生成(texture generation)这一重要问题。
旷视研究院提出一种端到端学习策略,可在行人重识别的监督下生成人体纹理。通过从输入数据中提取的纹理来渲染合成图像,并将重识别网络作为感知衡量标准,研究员最大化了输入与渲染图像之间的相似度。
多项实验结果表明,该模型可从单一图像中生成纹理,且纹理质量超越现有同类方法。未来,旷视研究员将对其进行跨领域应用迁移,探索生成纹理的可能性用途。
简介
针对人体的 3D 自动建模技术对于很多应用(包括虚拟现实、动画、视频剪辑、虚拟试穿)而言都非常重要。在人体 3D 重建领域,从单张图像生成 3D 人体模型愈发受到关注。
研究员从传统范式与深度学习范式出发,提出了大量相关方法,但这些方法只能精确估计出人体的姿态与形状,却不能生成纹理,这是目前人体 3D 重建研究所忽略的地方。
虽然从单张图像中生成人体纹理相当重要,但到目前为止,针对它的方法仅有两种,且存在不同的缺陷;单张图像的纹理生成也很有挑战性:首先,人体遮挡必然会导致不可能获得被遮挡部位的纹理信息;第二,人体姿态的多样性及其背景都会使纹理提取的过程更加复杂。
旷视研究院引入重识别方法来监督纹理生成模型。重识别即一种识别和检索人的方法,可作为距离标准衡量不同视角看到的纹理,从而上述第一个问题得到解决;重识别网络可在提取身体特征的同时消除来自姿态与背景信息的干扰,从而解决第二个问题。由此可知,将重识别网络作为监督信息去引导训练纹理生成网络是有效的。
基于重识别监督,旷视研究院提出一种从单一图像生成人体纹理的新方法。实例结果如图 1 所示。为了以端到端的方式来训练该模型,研究人员用 SMPL 人体模型渲染图像,把由重识别网络提取的纹理之间的距离作为训练损失(即重识别损失)。结果显示,该方法能很好的生成人体纹理.

图 1:Market-1501 上的纹理生成结果
为展示重识别网络的重要性,旷视研究员对比了重识别损失其它图像生成任务常见的损失函数,实验结果显示,本文模型生成的人体纹理优于其它方法。
除此之外,研究员还把本文方法用于其它事物的纹理生成,比如更好地生成鸟的纹理。另外,由于 3D 扫描纹理的稀缺,使用本文方法生成纹理的多样性远远高过 3D 扫描纹理的多样性。行为识别的实验证明,使用由高多样性纹理合成的数据集预训练网络更加有效。
方法
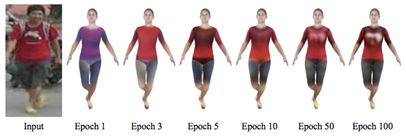
图 2:训练过程的可视化
本文模型的核心思想是最大化输入图像与已生成的纹理渲染图像之间的感知相似度。研究员假定,由更好纹理渲染的人体会与输入图像有更高的相似度。由图 2 可知,随着训练的增加,渲染图像与输入图像的相似度也在增加。
整个训练流程如图 3 所示。首先,研究员用 HMR 来预测 SMPL 参数,并用预测的参数来计算人体网格;然后,用纹理生成器(U-Net)来从单一图像生成纹理,并进一步用可微渲染器(Opendr)在这些生成的纹理在上渲染人体图像;随后,输入与渲染图像通过 part- based 卷积基线被送入一个预训练人体重识别网络 ,并最小化提取出的特征距离。
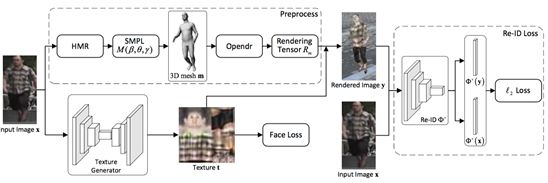
图 3:本文框架图示
人体网格重建
由于考虑到 SMPL 身体模型具有的出色建模效果与高计算效率,因此本文方法用其渲染纹理。SMPL 模型可以用形状参数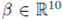
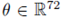
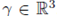
尽管重识别网络能降低由人体姿态与 translation 的变化带来的影响,但是(尤其是人体的位置与朝向)仍会干扰训练过程。因此,研究员仍然需要用输入图像来对渲染图像进行一致化处理,让渲染图像与输入图像中人体的形状和姿态保持一致。
就具体技术细节而言,研究员采用当前最好的 3D 人体姿态与形状估计方法 HMR。HMR 可以用一个迭代 3D 回归模型来生成 SMPL 的形状、姿态与平移参数。因此,从图像中估计出的 3D 网格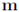
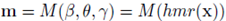
纹理渲染
在该步骤中,研究员用 U-Net 来生成纹理,然后用一个可微渲染器 Opendr 将生成的纹理映射到 3D 网格之上。本文使用 Opendr 的渲染函数生成人体模型的渲染矩阵。
在 3D 人体网格 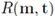
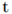
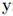

其中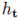
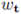
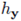
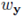
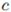
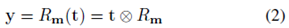
其中,只要人体的 3D 框固定,则渲染张量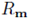
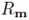
损失函数
重识别损失
重识别损失是渲染图像与输入图像逐层特征间的距离。在给定一对输入、渲染图像时,研究人员首先将预训练的重识别网络作为 x,y 的特征提取器。进一步,在 ResNet 的 Block 后面,惩罚了各个中间特征激活的距离(其中n = 4,v = 1,...,n):
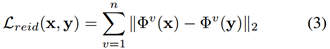
重识别的设置与广泛用于图像生成的感知损失类似,在感知损失那里,它使用的是一个在 ImageNet 上预训练的网络。然而,旷视研究院的方法超越了在知觉损失上训练的模型。这是因为重识别网络已是专门经过训练去最小化有关同一个人的图像间的距离,且最大化不同人图像间的距离。
由于人的身份主要靠其纹理来确定,因此重识别网络在引导纹理生成过程中表现更好。在本文提出的方法中,研究人员使用的是带有 PCB 的人体重识别模型。因为可以简单、高效地从不同身体部位提取特征。
面部损失
为了提升生成图像的拟真度,研究员将面部的损失设计成面部与手部在(来自SURREAL)生成的纹理与 3D 扫描的纹理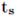
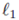
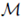
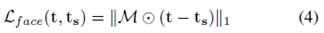
面部损失可以使得生成的面部纹理与扫描的纹理中对应的部位相似。至于为何研究人员在训练过程中使用面部损失而非简单地用扫描纹理盖住生成的面部,是因为使用面部损失可以消除头部与躯干间的颜色差异。由图 4 可知,如果没有在训练过程中采用面部损失,则最终得到的图像质量很低。

图 4:带有和不带有面部损失的结果
综上所述,整个损失函数为:
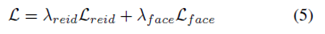
实验
对比现有方法
由上可知,重识别在本文模型中发挥了至关重要的作用。研究员把模型同另外两个针对纹理生成任务的损失函数(逐像素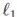

图 5:定性结果

表 1:定量结果
从量化结果可知,使用重识别损失训练的模型性能优于使用其它损失函数的模型。用逐像素
用感知损失(Perceptual Loss)训练的模型表现甚至更差。躯干部分的感知质量不好。这是因为在 ImageNet 上训练的网络倾向从物体上提取物体的一般特征,而非聚焦于身体的纹理。
在所有的实验结果中,
不同模型设置的对比
本文使用重识别网络提取人体的纹理特征,但是如何选取重识别网络提取的特征以提升纹理生成的效果,则是一个很值得探索的话题。针对这一问题,研究员做了一系列对比实验,结果如图 6 和表 2 所示。

图6:定性结果
表2:定量结果
首先,旷视研究员使用重识别网络的深层特征训练模型。定性和定量结果均说明深层特征不能保持人体纹理的一些细节特征(如衣服花纹等),因为其在网络的深层中很难表达。
随后,不进行姿态对齐,而是从人体姿态数据集中随机采集的姿态来渲染图片。由结果可知,不进行姿态对齐,上臂和腿处的纹理常常出现问题。另外,当人体只占据图像一部分时,模型将部分的背景当做人体的纹理从而导致生成的纹理错误。
最后,研究员使用去掉 PCB 模块的网络训练模型。定量和定性结果均可说明,无 PCB 的模型生成的纹理质量相对较差。这是因为 PCB 模型可以提取人体的每一部分特征,从而指导其纹理生成。
鸟类纹理生成
本文模型不仅可用于人体纹理生成,还可提取一般物体的纹理。旷视研究员首先在 CUB-200-2011 数据集上训练一个重识别模型,然后用其指导鸟类纹理生成。研究员把本文模型与 Angjoo Kanazawa 等人的工作(CMR)进行对比,后者使用感知损失(Perceptual Loss)作为损失函数训练纹理生成网络。最终结果如图 7 所示:

图 7:鸟类纹理生成
由上可知,本文模型性能超过 Angjoo Kanazawa 等人的工作。这也说明,重识别损失相较于感知损失更适合纹理生成任务。
动作识别实验
旷视研究员从 Market1501 数据集提取 1500 个纹理,使用 Gul Varol 等人提出的方法合成数据集,称之为 SURREAL++;研究员分别在 SURREAL 和 SURREAL++ 上预训练用于动作识别的 Non-local 网络,并进一步在 UCF101 数据集上微调。实验结果如表 3 所示:
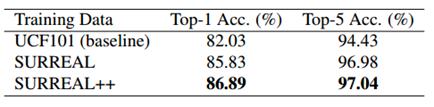
表3:动作识别实验
从上可知,SURREAL++ 数据集结果更好。这也说明,本文方法可生成大量的人体纹理,且具有更高的多样性,可提升合成数据集质量。
结论
旷视研究院提出一个从单一 RGB 图像生成纹理的端到端框架,其实现的关键是把预训练的 ReID 网络作为纹理生成的监督器。如上所述,ReID 网络不仅可以提取人体特征,还可以降低姿态变化产生的影响,因而是纹理生成任务的一个很好的监督器。
研究员还证明,ReID 网络在一般物体的三维重建工作中具有广泛的应用潜力,以及纹理的多样性可使预训练模型性能更优。由于生成的人体纹理的质量受限于低质量的可微渲染器,因此研究员推断,高质量的渲染器将显著提升本文方法的性能。
另外,由于本文框架以类似于输入图像的方式渲染合成图像,遮挡部位的纹理质量无法保证。但是,在训练图像中,研究员发现,另一张图像 x′ 与输入图像 x 具有相同 ID ,尽管姿态不同。接着,研究员把渲染图像 y 的姿态与 x' 对齐,从而以另一个视角来监督纹理生成的过程。这将是下一阶段的探索目标。
论文名称:Re-Identification Supervised Texture Generation
论文链接:https://arxiv.org/abs/1904.03385
参考文献
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, DavidWarde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generativeadversarial nets. In Advances in neural information processing systems, pages2672–2680, 2014.
Angjoo Kanazawa, Michael J Black, David W Jacobs, and JitendraMalik. End-to-end recovery of human shape and pose. In IEEE Conference onComputer Vision and Pattern Recognition, 2018.
Angjoo Kanazawa, Shubham Tulsiani, Alexei A. Efros, and JitendraMalik. Learning category-specific mesh reconstruction from image collections.In ECCV 2018, pages 386–402, 2018.
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, andMichael J Black. Smpl: A skinned multi-person linear model. ACM Transactions onGraphics (TOG), 34(6):248, 2015.
Matthew M. Loper and Michael J. Black. Opendr: An approximatedifferentiable renderer. In ECCV 2014, pages 154–169, 2014.
Natalia Neverova, Riza Alp Gu ̈ler, and Iasonas Kokkinos. Dense posetransfer. In ECCV 2018, pages 128–143, 2018.
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net:Convolutional networks for biomedical image segmentation. In Medical ImageComputing and Computer-Assisted Inter- vention, pages 234–241, 2015.
Gul Varol, Javier Romero, Xavier Martin, Naureen Mahmood, Michael JBlack, Ivan Laptev, and Cordelia Schmid.Learning from synthetic humans. In IEEEConference on Computer Vision and Pattern Recognition, pages 4627–4635,2017.
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按关注极市平台
觉得有用麻烦给个在看啦~



